- The paper introduces a CTD model that exploits contextualized token representations to correct ASR misrecognitions in speech queries.
- It employs a BERT-based encoder with a composition layer that aggregates input, contextual, and difference vectors for improved token discrimination.
- Experimental results show significant F1 improvements, achieving 89.6% on standard datasets and 52.2% on realistic benchmarks.
Contextualized Token Discrimination for Speech Search Query Correction
Introduction
The paper presents Contextualized Token Discrimination (CTD), a BERT-based framework for correcting misrecognized tokens in speech search queries transcribed by ASR systems. The motivation stems from the persistent challenge of ASR errors—especially homophonic and contextually illogical substitutions—that degrade downstream search and retrieval quality. CTD leverages contextualized token representations to discriminate and correct erroneous tokens, outperforming prior context-free and context-aware approaches. The work also introduces a new benchmark dataset (AAM) with realistic ASR errors, enabling comprehensive evaluation of correction models.
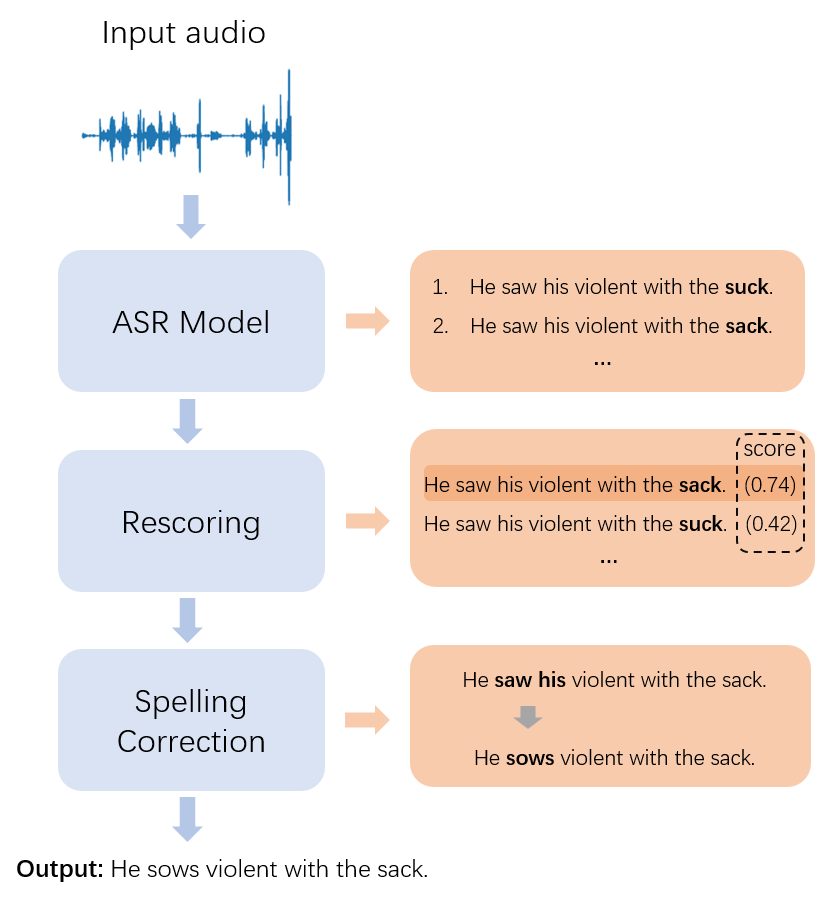
Figure 1: Overview of the ASR pipeline and the role of spelling correction in post-processing transcribed queries.
Traditional ASR error correction methods include statistical machine translation, phrase-based correction, and sequence-to-sequence models. Recent advances utilize pre-trained LLMs (PLMs) and LLMs for context-aware correction, with architectures such as Soft-Masked BERT and FastCorrect-2. However, these models often fail to fully exploit the contextual dependencies inherent in speech data, particularly for languages like Chinese where homophonic errors are prevalent. The CTD method is designed to address these limitations by explicitly modeling the compatibility between token-level input and its contextualized representation.
Methodology
Pretrained Contextualized Encoder
CTD employs a fine-tuned BERT-base-chinese model as its encoder. The model is first fine-tuned with MLM loss on domain-specific, error-free sentences to learn robust word dependencies. For each input query, BERT generates contextualized token representations, which are sensitive to the surrounding context and can highlight semantic misalignments caused by ASR errors.
Correction Module
The core innovation is the composition layer, which aggregates three vectors for each token: the input token embedding, its contextualized representation, and their difference. This aggregation is inspired by ESIM and is formalized as:
ci=[viC;viI;viC−viI]
where viI is the input token embedding and viC is the contextualized representation from the last BERT layer. The concatenated vector ci is passed through an MLP classifier to predict the corrected token. Training is performed end-to-end, with the loss computed only on error tokens and a sampled subset of correct tokens to balance the learning signal.
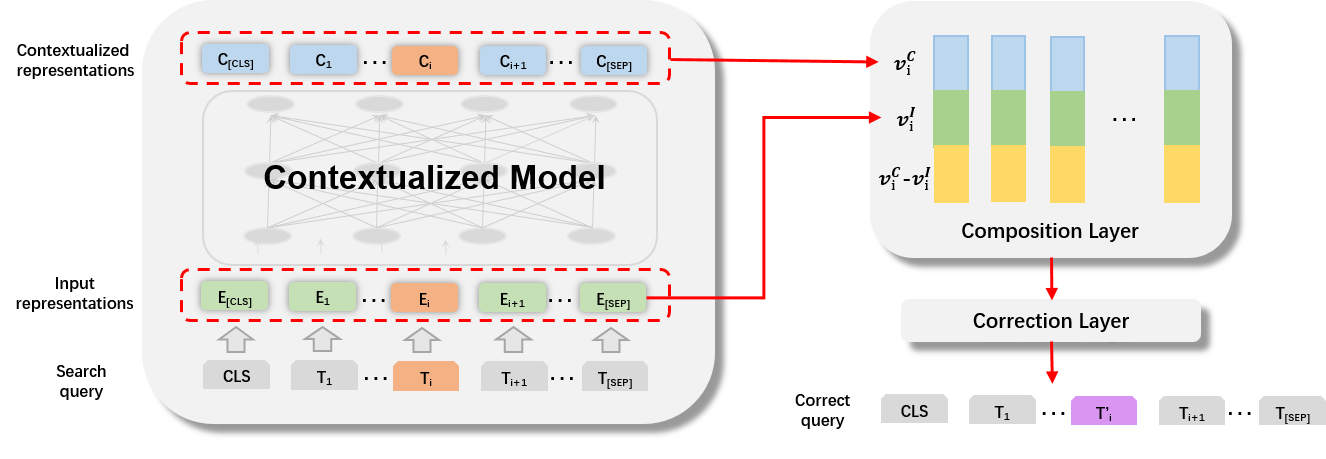
Figure 2: Architecture of CTD, showing the contextualized encoder, composition layer, and correction module. Error tokens are highlighted for discrimination.
Contextual Token Similarity Analysis
The paper provides empirical evidence that correct tokens exhibit higher cosine similarity with their context, while erroneous tokens are less correlated. This observation justifies the use of contextualized representations for error detection and correction.
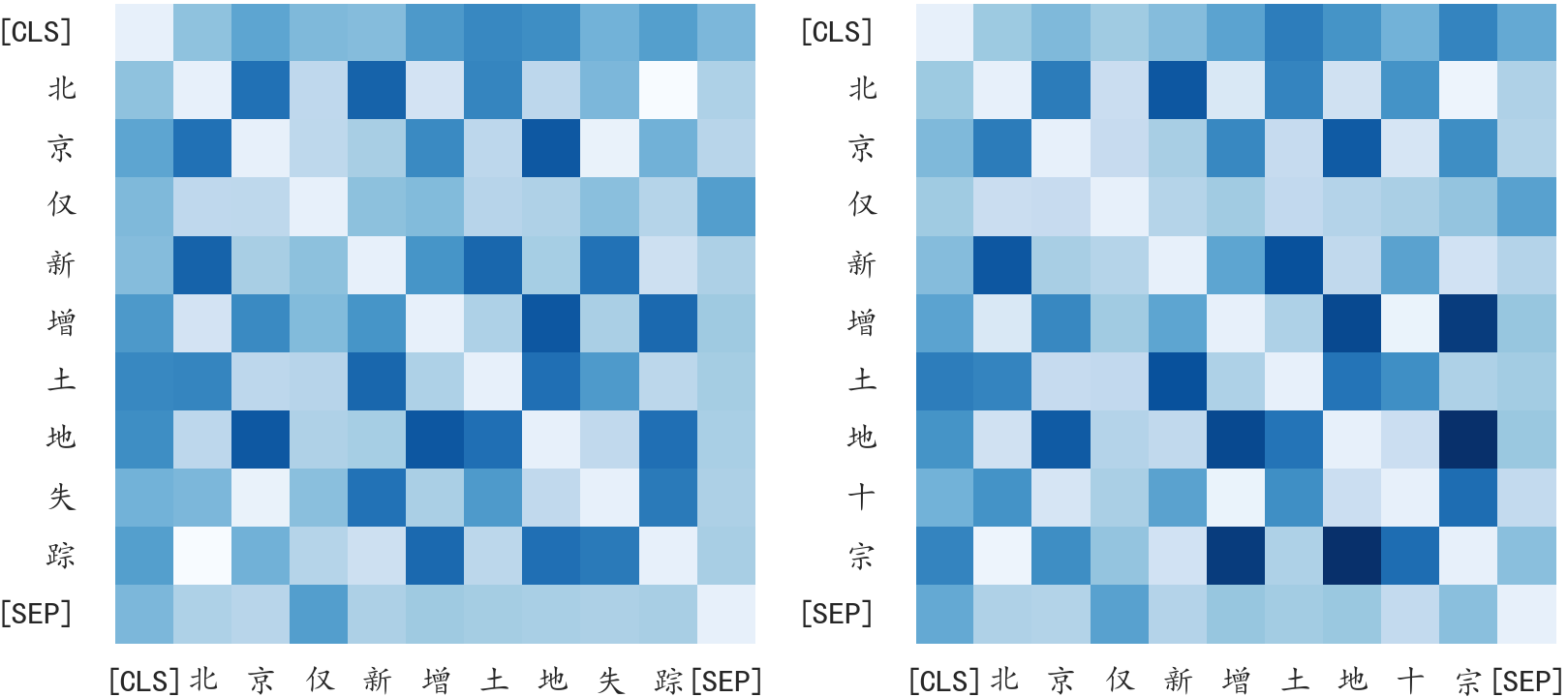
Figure 3: Cosine similarity matrices for misrecognized and correct queries, illustrating the contextual misalignment of error tokens.
Experimental Results
Datasets
- SIGHAN: Standard Chinese spelling correction dataset with 1,100 texts and 461 error types.
- AAM: Newly constructed benchmark with 6,965 pairs from Aidatatang, AISHELL-1, and MagicData, containing realistic ASR errors.
Model Configuration
- Base Model: Fine-tuned BERT-base-chinese (12 layers, 768 hidden size, 12 attention heads, 120M parameters).
- CTD: Adds composition layer and MLP classifier (156M parameters).
Training Details
- Optimizer: AdamW (β1=0.9, β2=0.98, ϵ=10−9)
- Learning rate: Linear warmup to 5×10−4, exponential decay
- Batch size: 512 sequences
- Early stopping applied
- Sentence-level accuracy, precision, recall, F1 score
Results
On SIGHAN, CTD achieves an F1 score of 89.6%, surpassing BERT (64.9%) and Soft-Masked BERT (66.4%). On AAM, CTD attains an F1 score of 52.2%, outperforming baselines by a substantial margin. The improvement is attributed to the domain-specific fine-tuning and the discriminative power of the composition layer.
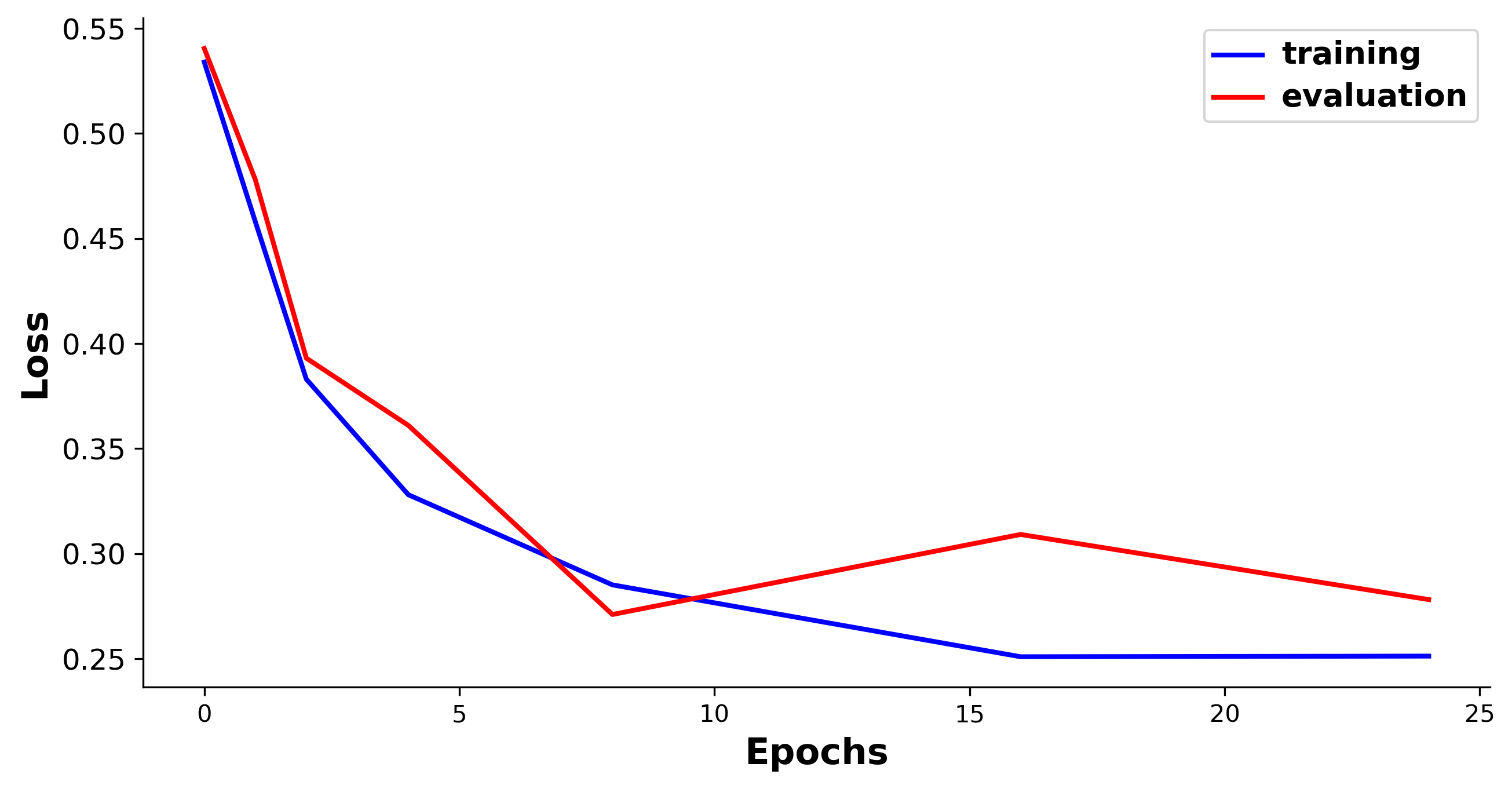
Figure 4: Training loss curve of CTD on the AAM dataset, demonstrating stable convergence.
Qualitative analysis on AAM test cases shows CTD can correct contextually illogical substitutions (e.g., replacing "opinions" with "should be reduced" in regulatory contexts), but struggles with errors requiring external world knowledge.
Implications and Future Directions
The CTD framework demonstrates that explicit modeling of token-context compatibility yields significant gains in ASR error correction, especially for languages with high homophonic ambiguity. The introduction of the AAM dataset provides a realistic benchmark for future research. However, the current approach is limited to same-length error/correction pairs and relies heavily on domain-specific data, which may restrict generalization. Future work should address insertion/deletion errors, explore few-shot adaptation, and integrate external knowledge sources to handle semantically complex corrections.
Conclusion
Contextualized Token Discrimination (CTD) offers a robust, scalable solution for speech search query correction by leveraging fine-tuned contextualized representations and a discriminative composition layer. The method achieves state-of-the-art results on both standard and realistic ASR error datasets, with clear practical advantages for industrial deployment. Further research should focus on expanding the error types handled and improving generalization across domains.