When three experiments are better than two: Avoiding intractable correlated aleatoric uncertainty by leveraging a novel bias--variance tradeoff
Published 4 Sep 2025 in cs.LG | (2509.04363v1)
Abstract: Real-world experimental scenarios are characterized by the presence of heteroskedastic aleatoric uncertainty, and this uncertainty can be correlated in batched settings. The bias--variance tradeoff can be used to write the expected mean squared error between a model distribution and a ground-truth random variable as the sum of an epistemic uncertainty term, the bias squared, and an aleatoric uncertainty term. We leverage this relationship to propose novel active learning strategies that directly reduce the bias between experimental rounds, considering model systems both with and without noise. Finally, we investigate methods to leverage historical data in a quadratic manner through the use of a novel cobias--covariance relationship, which naturally proposes a mechanism for batching through an eigendecomposition strategy. When our difference-based method leveraging the cobias--covariance relationship is utilized in a batched setting (with a quadratic estimator), we outperform a number of canonical methods including BALD and Least Confidence.
The paper introduces a novel bias–variance strategy that leverages a cobias–covariance relationship to reduce bias across experimental rounds.
The methodology employs quadratic estimation and eigendecomposition for robust and efficient batch selection in low-data, noisy environments.
Numerical experiments demonstrate significant performance gains over standard active learning techniques, especially in settings with heterogeneous noise.
Avoiding Intractable Correlated Aleatoric Uncertainty via Bias–Variance Tradeoff
Introduction and Motivation
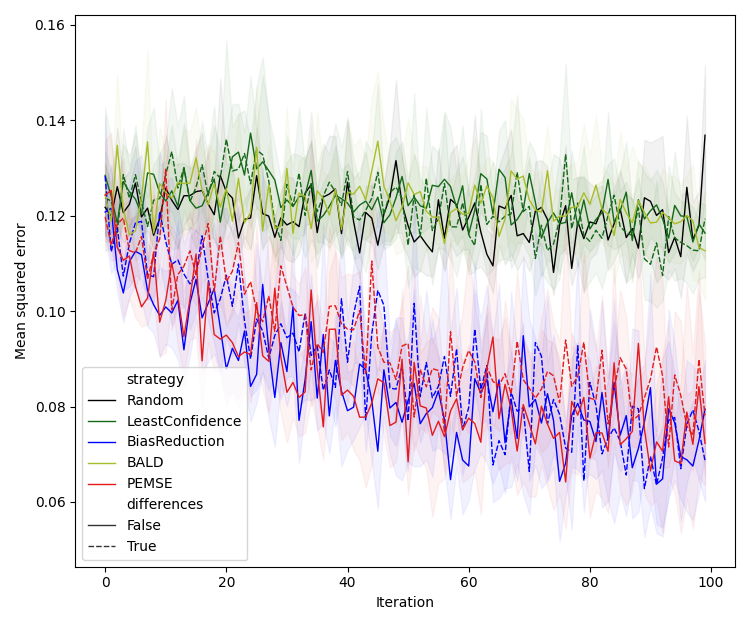
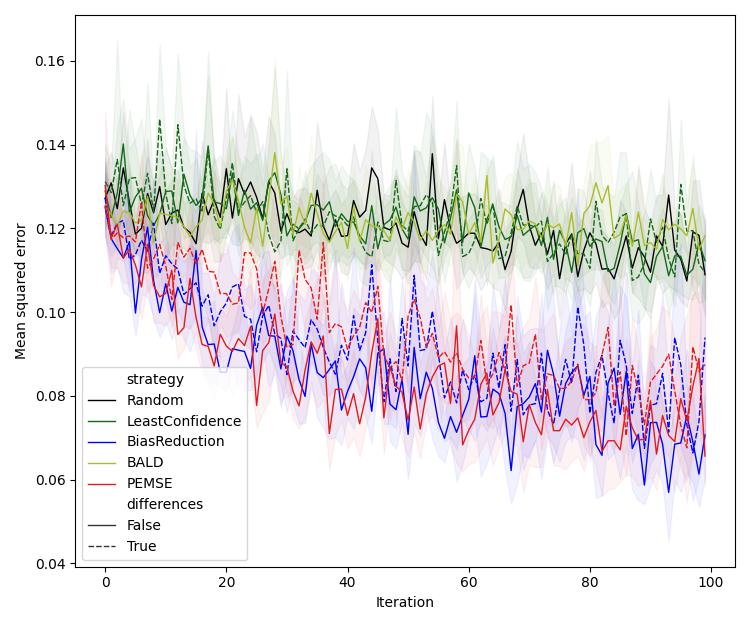
This paper addresses the challenge of active learning (AL) in real-world experimental settings characterized by heteroskedastic and correlated aleatoric uncertainty, particularly in batched data acquisition scenarios. The authors propose a suite of methods that leverage the bias–variance tradeoff to directly target the reduction of bias between experimental rounds, introducing a novel cobias–covariance relationship for more effective batch selection. The approach is motivated by the limitations of canonical AL strategies (e.g., Least Confidence, BALD) in noisy, correlated environments, and is demonstrated to outperform these baselines in synthetic benchmarks.
The central insight is that the expected mean squared error (EMSE) between a model’s predictive distribution and the ground-truth process can be decomposed into epistemic uncertainty (model variance), bias squared, and aleatoric uncertainty. By focusing on the bias term and its dynamics across rounds, the authors develop acquisition functions that prioritize regions where model predictions are rapidly improving, and introduce quadratic estimators to exploit historical data more efficiently.
Figure 1: Schematic illustrating the relationship between predictive distributions, noisy oracle realizations, and the evolution of bias and uncertainty across experimental rounds.
Mathematical Framework
Problem Formulation
Let X denote the state space, Y the random variable representing noisy observations, and Fk the distribution of functions (e.g., deep ensemble) trained on data up to round k. The observed label at x is y∼Y(x)=μY(x)+W(x), where W(x) is a heteroskedastic noise term. The bias at round k is defined as δk(x)=μFk(x)−μY(x).
The pointwise expected mean squared error (PEMSE) at x is:
where σFk2(x) is epistemic uncertainty, δk2(x) is bias squared, and σY2(x) is aleatoric uncertainty.
Acquisition Functions
The authors propose several acquisition functions, including:
Least Confidence (LC):σFk2(x)
Bias Reduction (BR):δk2(x)
PEMSE:σFk2(x)+δk2(x)
Difference-based:κ(gk)(x)=gk−1(x)−gk(x), targeting regions with rapid reduction in uncertainty or bias.
These functions are adapted for three problem types:
Type I: Noiseless systems (W≡0)
Type II: Uncorrelated noise
Type III: Correlated noise (batched settings)
Cobias–Covariance Tradeoff and Quadratic Estimation
A key contribution is the generalization of the bias–variance tradeoff to pairs of points, yielding the cobias–covariance relationship:
k(x,x∗)=σFk(x,x∗)+δk(x)δk(x∗)+σY(x,x∗)
This enables the construction of the matrix Ω(k) over discretized X, with the cobias matrix Δk=δkδk⊺ (rank-1), and covariance matrices for model and noise.
Quadratic estimation is performed via a symmetric neural network Q(x,x∗)=ψ(x)⊺ψ(x∗), leveraging the low-rank structure for stable matrix completion. This approach is shown to be more robust than direct estimation, especially in low-data regimes and for batch selection.
Batch Selection via Eigendecomposition
Batch selection is formulated as an eigendecomposition problem on Ω(k) (or its difference between rounds for difference-based methods). The top m eigenvectors identify principal directions of uncertainty/bias, and the corresponding indices are selected for labeling. This method naturally accounts for correlated noise and ensures diversity in batch selection.
Numerical Experiments
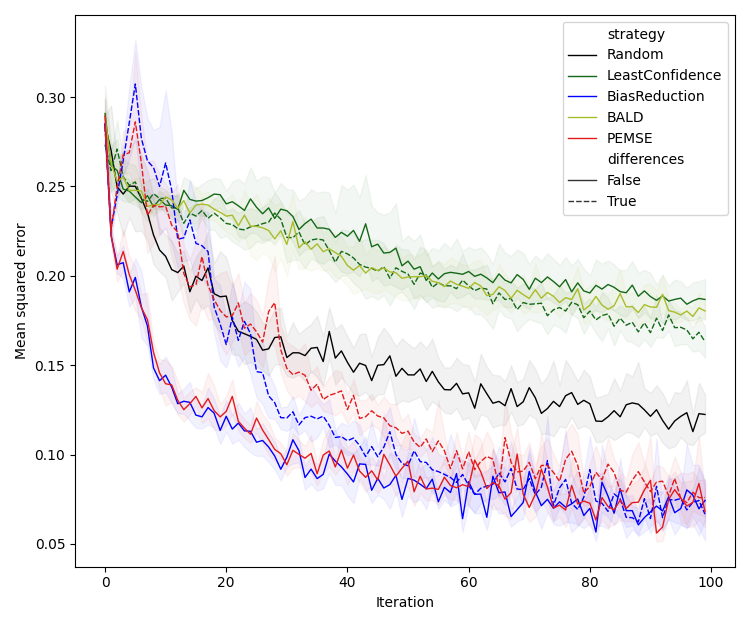
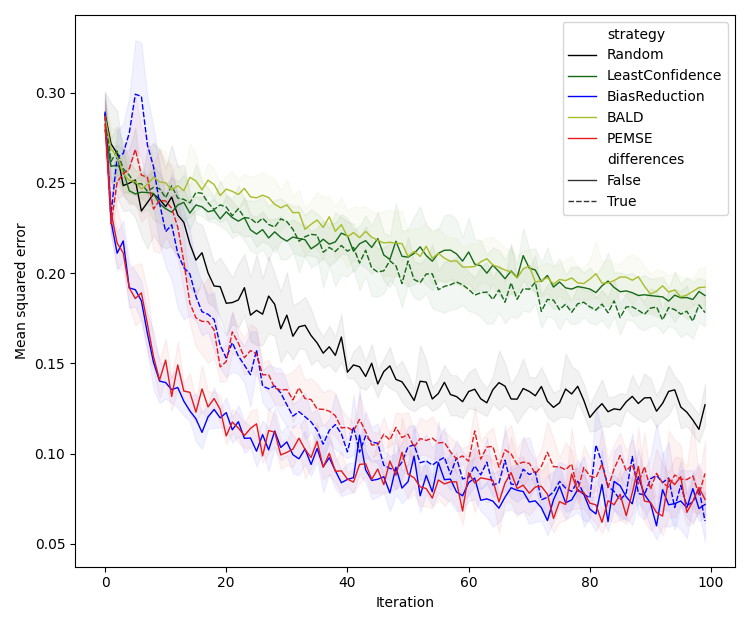
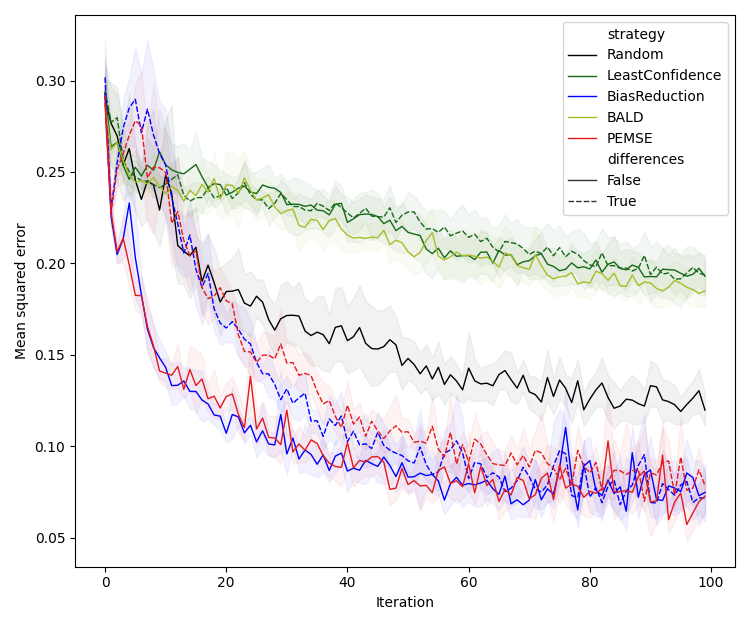
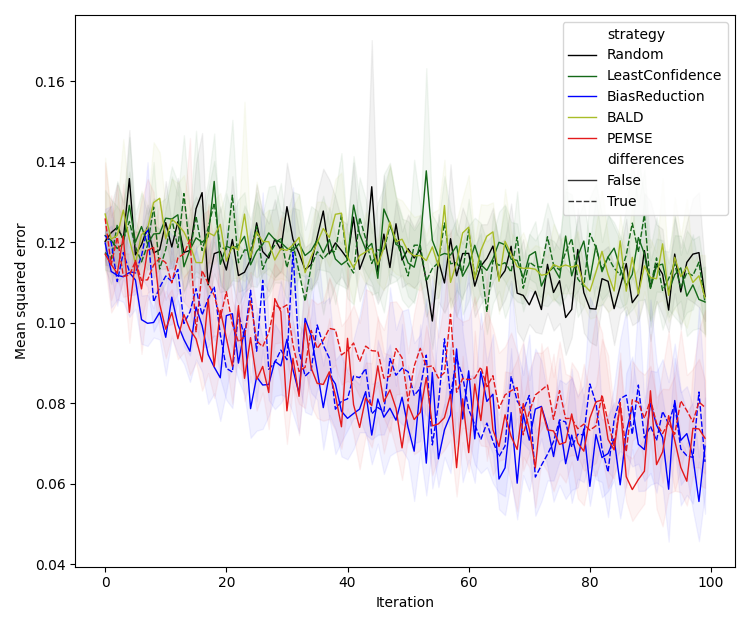
Experiments are conducted on a 2D synthetic system with varying noise structures (Type I/II/III), comparing the proposed methods against LC, BALD, and random selection. Models are deep ensembles of neural networks, and bias estimation is performed via Gaussian processes (direct) or symmetric neural networks (quadratic).
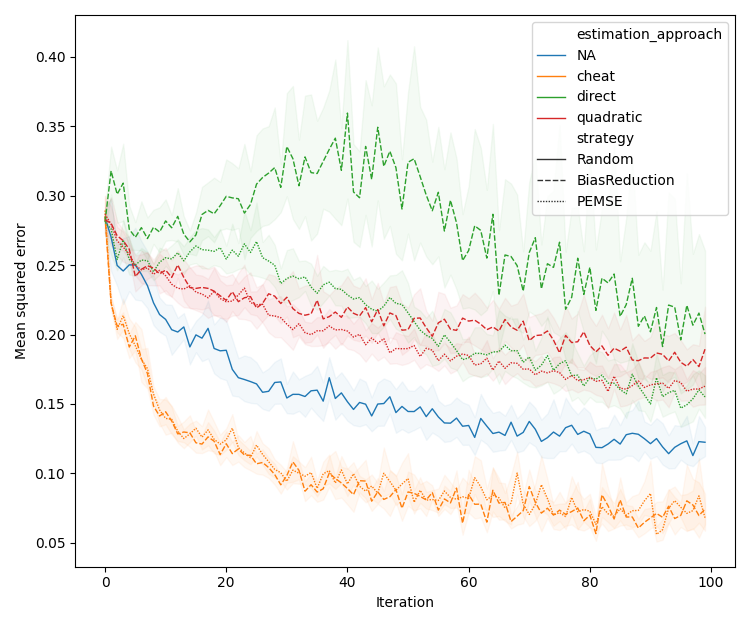
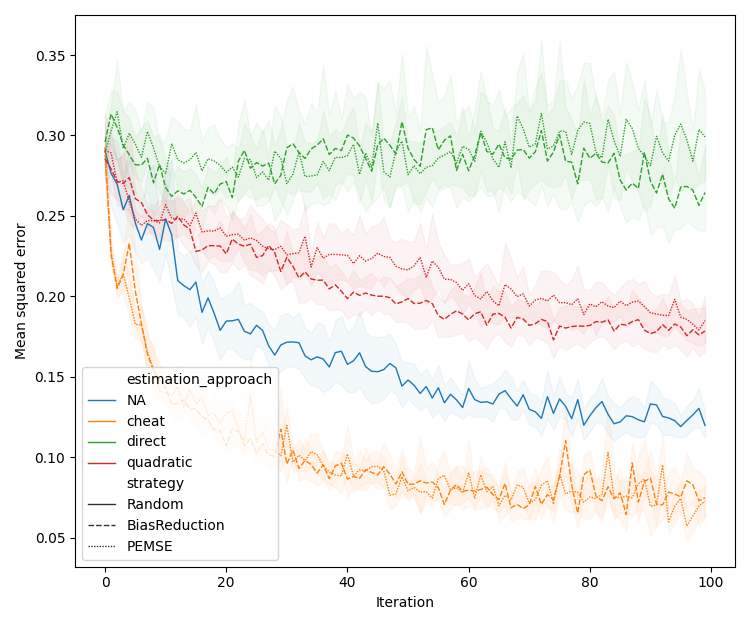
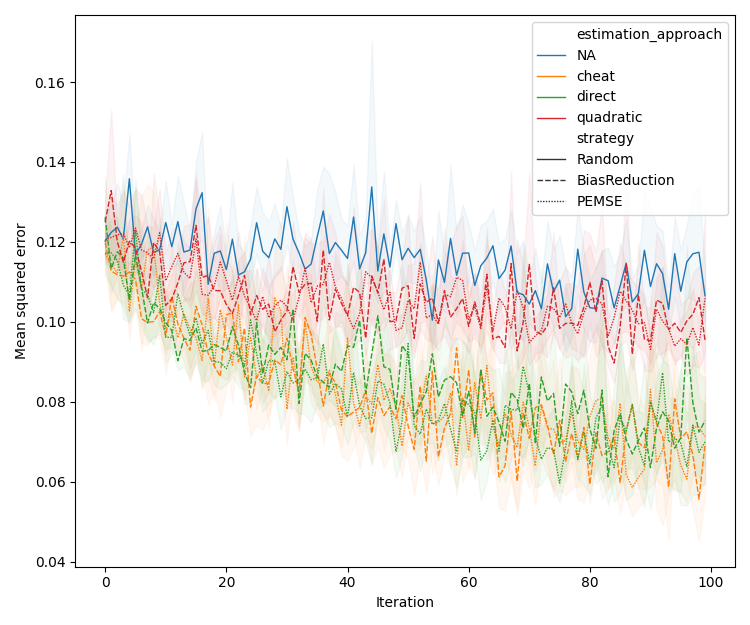
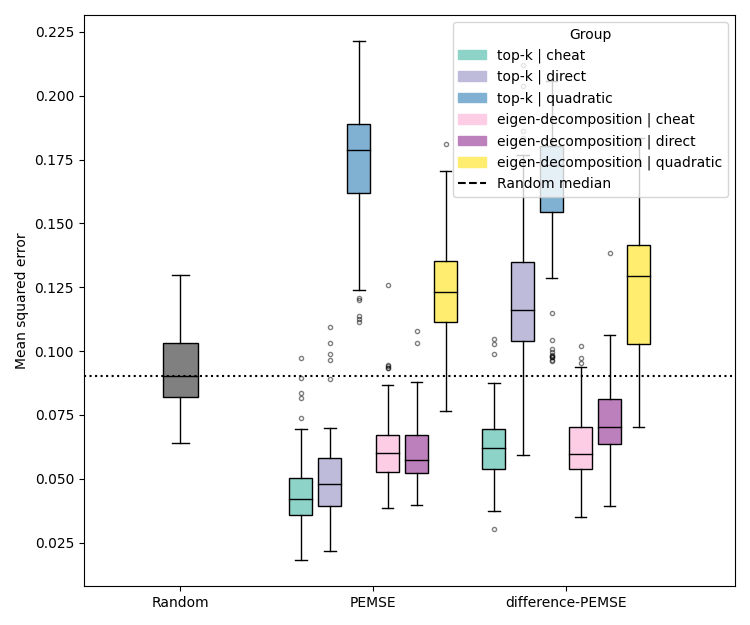
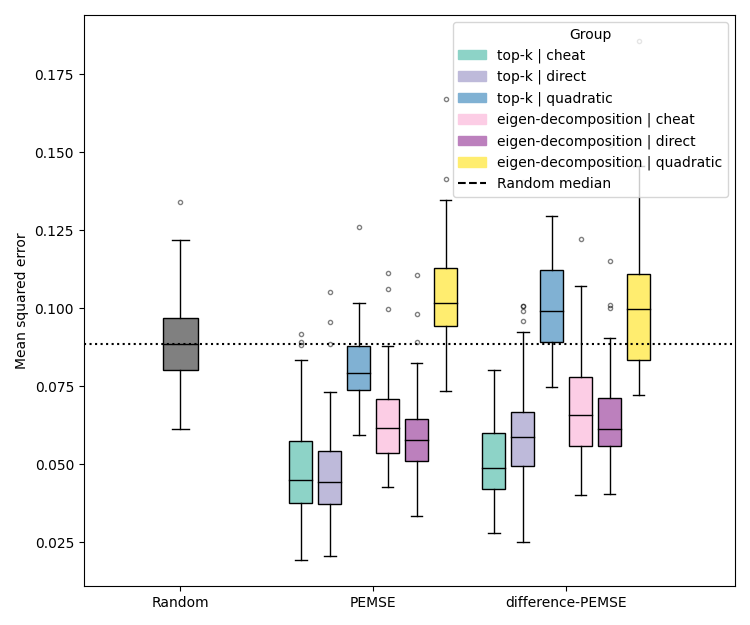
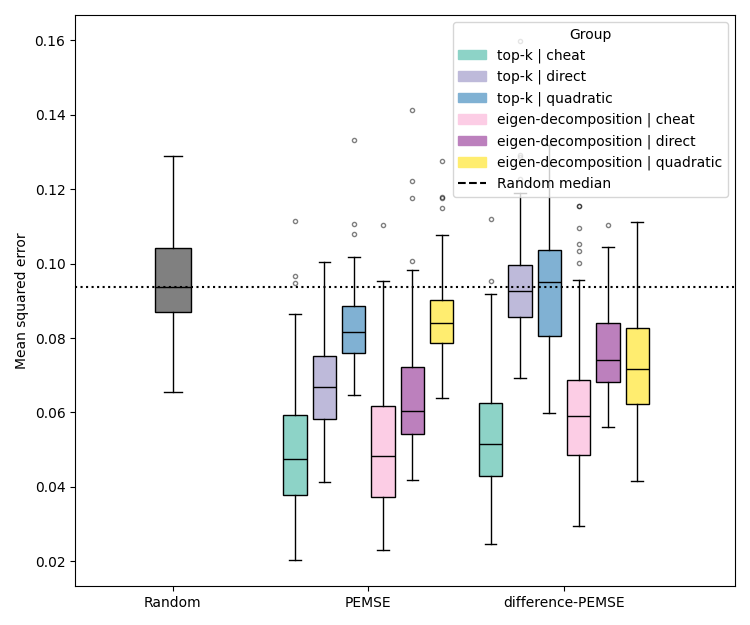
Figure 2: Performance comparison of BR and PEMSE acquisition functions using direct and quadratic estimation of the cobias matrix across problem types and initializations.
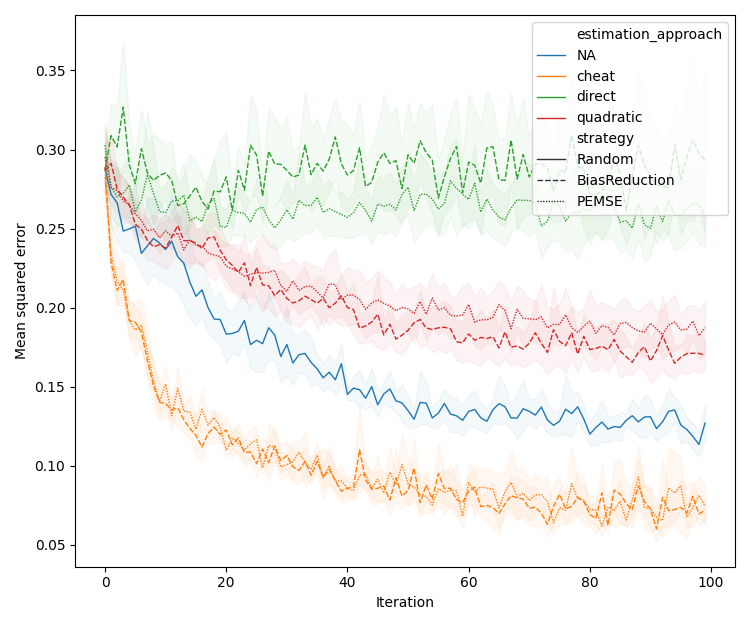
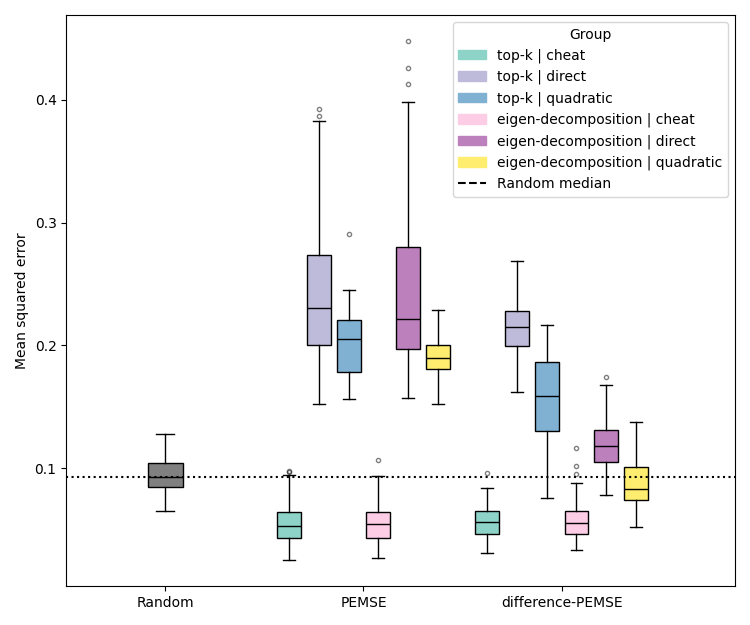
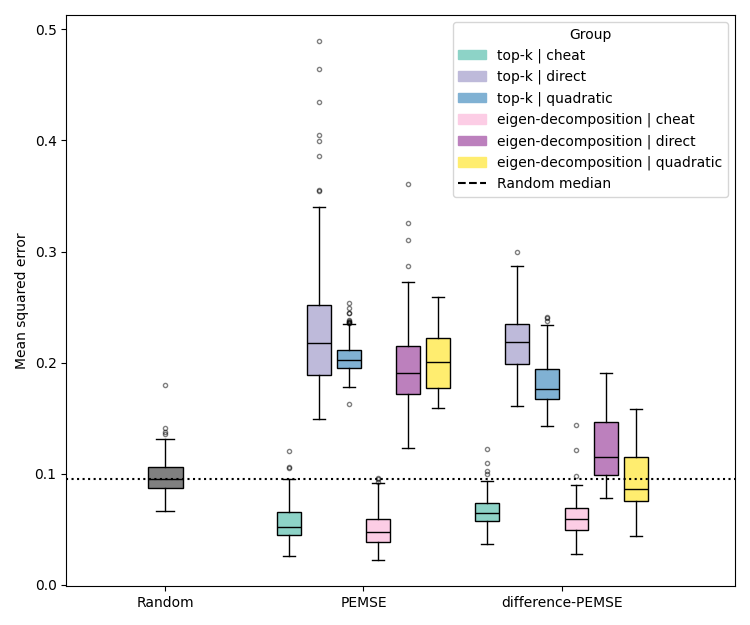
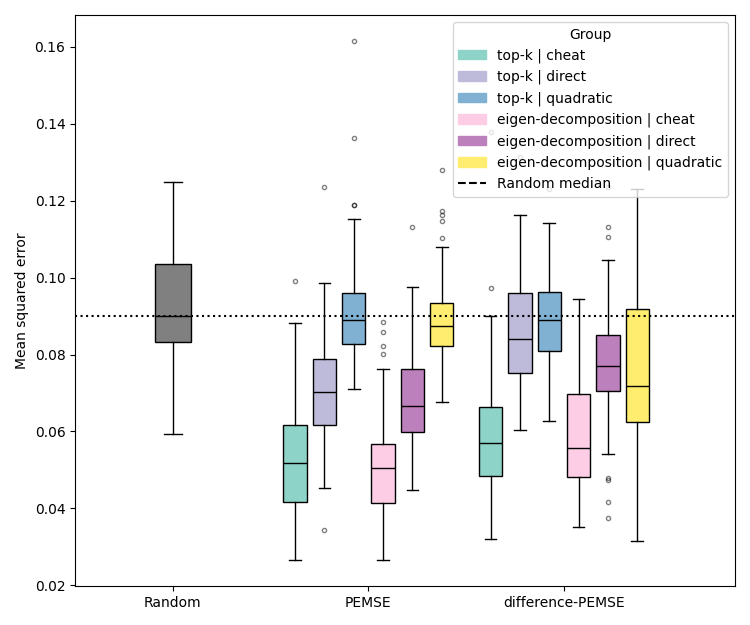
Quadratic estimation consistently outperforms direct estimation in low-data regimes, particularly for Type II/III problems. Difference-based methods with eigendecomposition provide further gains in batch settings, especially when aleatoric noise is correlated.
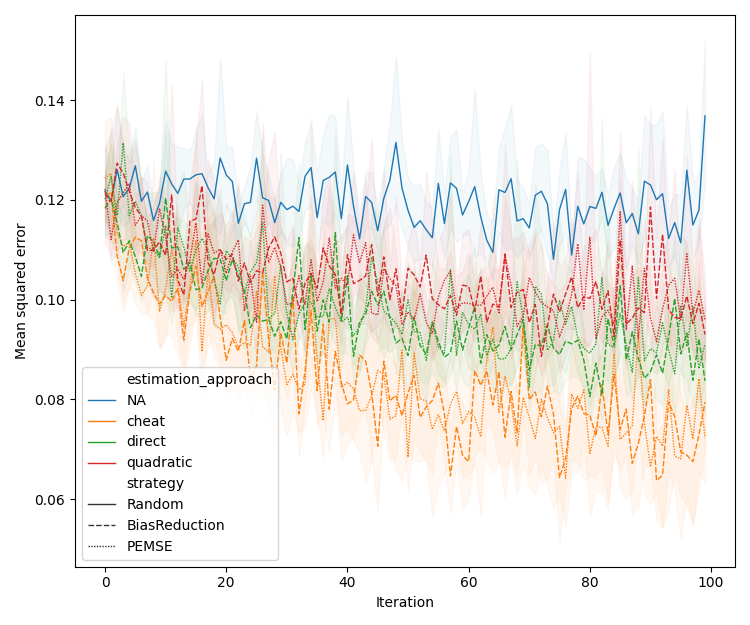
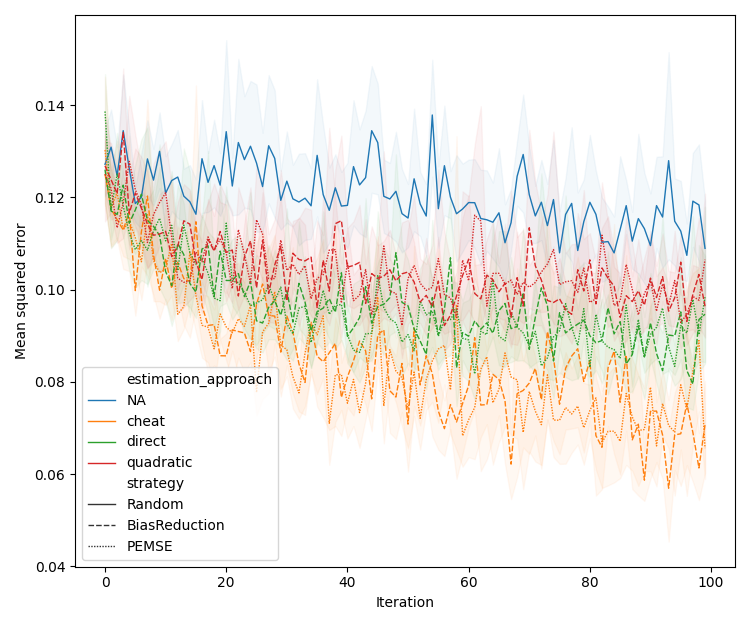
Figure 3: Assessment of PEMSE and difference-PEMSE acquisition functions with various cobias estimation methods, highlighting the superiority of quadratic estimation in batched, noisy scenarios.
Implementation Considerations
Model Requirements: Deep ensembles are used for predictive distributions; quadratic estimation requires a symmetric neural network for matrix completion.
Computational Complexity: Eigendecomposition scales with the number of candidate points; quadratic estimation is more stable but requires additional training.
Batching: The eigendecomposition approach is essential for correlated noise scenarios; top-k selection is less effective.
Bias Estimation: Quadratic estimation is preferred in low-data regimes and for batch selection; direct estimation may suffice with abundant data.
Implications and Future Directions
The proposed framework provides a principled mechanism for AL in settings with complex noise structures, outperforming canonical methods in synthetic benchmarks. The cobias–covariance relationship and quadratic estimation open avenues for more efficient use of historical data and robust batch selection. Extensions to other loss functions (e.g., Bregman divergences) and classification tasks are suggested, though the symmetry requirement may limit applicability.
Theoretical implications include a shift from Bayesian/information-theoretic approaches to function analysis, with potential for integration. Practically, the method is well-suited for lab-in-the-loop systems in life sciences, where replicates and batch effects are prevalent.
Conclusion
This work introduces a novel bias–variance-driven active learning strategy that leverages a cobias–covariance tradeoff and quadratic estimation for robust batch selection in noisy, correlated environments. The approach demonstrates superior performance over standard AL methods, particularly in low-data and batched settings, and provides a mathematically grounded framework for future extensions in both regression and potentially classification domains.