- The paper introduces GeoArena, a dynamic, privacy-preserving benchmark that uses human pairwise evaluations to compare LVLM geolocalization outputs.
- It employs rigorous ranking methods, combining Elo and Bradley-Terry models, to assess 17 diverse vision-language models in real-world conditions.
- Benchmark results and case studies highlight that model scaling and alignment are crucial for improved geolocalization performance, informing future research.
Motivation and Limitations of Existing Geolocalization Benchmarks
Image geolocalization, the task of predicting the geographic location of an image captured anywhere on Earth, presents substantial challenges due to global visual diversity and the need for fine-grained spatial reasoning. Existing evaluation methodologies for geolocalization models, particularly those leveraging LVLMs, suffer from two critical limitations: (1) data leakage, as static test datasets are often included in model pretraining corpora, and (2) reliance on GPS-based metrics, which ignore the reasoning process and raise privacy concerns due to the need for exact user-level location data.
GeoArena is introduced to address these issues by providing a dynamic, privacy-preserving, and human-centered benchmarking platform. The platform enables the collection of in-the-wild images and leverages pairwise human judgments to evaluate model outputs, thus mitigating data leakage and aligning evaluation with real-world user expectations.
GeoArena is an interactive online platform that allows users to upload images and prompts for geolocalization. The interface consists of an input component for image and prompt submission and a voting component for pairwise model output comparison. Users vote on which model response better aligns with their expectations, with options for left, right, or tie. Model identities are revealed post-voting to maintain impartiality.
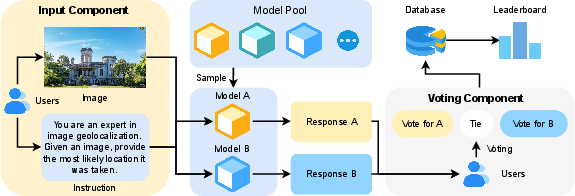
Figure 1: Overview of GeoArena, illustrating the user workflow from image upload to pairwise model output voting.
Each voting event records the compared models, the winning model, the prompt, the image, the generated responses, and the timestamp. All data are anonymized and stored in structured formats to facilitate downstream analysis and leaderboard generation while preserving user privacy.
Model Coverage and Ranking Methodology
GeoArena benchmarks a diverse set of 17 LVLMs, including proprietary models (e.g., Gemini-2.5, GPT-4o, Claude Opus) and open-source models (e.g., Qwen2.5-VL, Gemma-3, Llama-4). This broad coverage enables comprehensive evaluation across architectures and training paradigms.
Model ranking is computed using a combination of Elo and Bradley-Terry (BT) models. The BT model estimates latent strength parameters for each model based on pairwise comparison outcomes, with a linear transformation to align scores with the Elo scale. Bootstrap procedures are employed to estimate confidence intervals, ensuring statistical robustness and interpretability of the rankings.
Dataset Release: GeoArena-1K
GeoArena-1K, the first human preference dataset for LVLMs in image geolocalization, is released as part of this work. It contains user-uploaded images, prompts, pairwise model responses, model identities, and human voting outcomes. Annotation of the dataset reveals that 94.2% of images are outdoor scenes, 45.2% contain recognizable text, and 15.8% feature landmarks, providing a heterogeneous and realistic evaluation corpus.
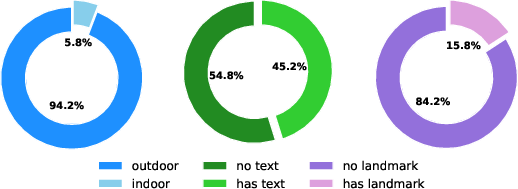
Figure 2: Composition of Image Features in GeoArena-1K Dataset, showing distributions of indoor/outdoor, text presence, and landmark presence.
Benchmark Results and Comparative Analysis
GeoArena's leaderboard demonstrates clear stratification among models. Gemini-2.5-pro achieves the highest Elo rating (1319.7), followed by Gemini-2.5-flash (1206.5), with open-source models such as Qwen2.5-VL-72B-Instruct (1094.5) and Gemma-3-12B-it (1086.5) closing the gap. Lower-capacity models (e.g., GPT-4.1-nano, GPT-4o-mini) exhibit significant performance degradation, underscoring the difficulty of the task and the importance of model scale and alignment.
Pairwise win-rate analysis reveals that frontier models consistently dominate across families, while mid-scale and lower-capacity models show predictable performance scaling. Family-specific trends indicate that both parameter count and post-training alignment are critical for competitive geolocalization.
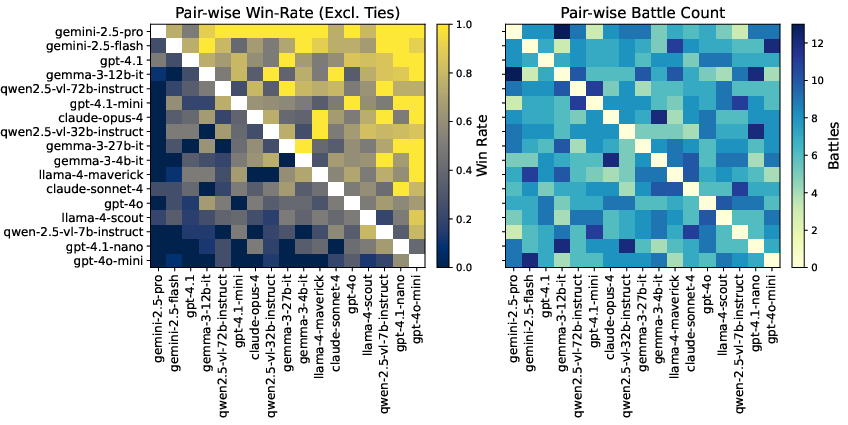
Figure 3: Pair-wise Performance Comparison of Models, visualizing win-rates and battle counts across the leaderboard.
Human Preference and Style Feature Analysis
GeoArena incorporates style feature analysis to disentangle the influence of response formatting from intrinsic model capability. Regression analysis shows that response length has the strongest positive correlation with user preference (β=0.526), followed by lists count and GPS output ratio. Headers and emphasis markers do not contribute positively, suggesting that substantive content is favored over superficial formatting.
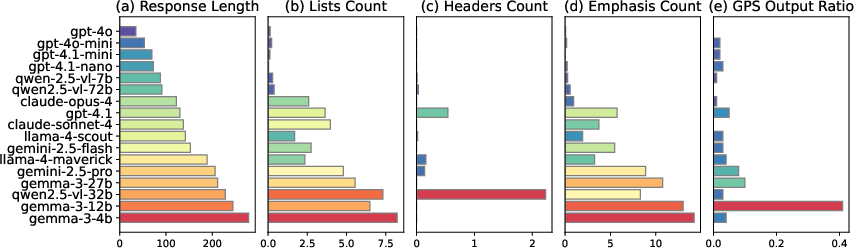
Figure 4: Distribution of Style Features in Model Outputs, highlighting variation in response length, structure, and GPS prediction frequency.
LVLM Alignment with Human Judgment
An alignment study comparing LVLM judgments with human annotations on sampled response pairs reveals that Gemini-2.5-Pro achieves 65.8% agreement with human preferences, while Qwen2.5-VL-72B-Instruct achieves 46.7%. This indicates that top proprietary models are more closely aligned with human evaluators, but significant gaps remain, motivating further research into robust LLM-based evaluators for multimodal tasks.
Case Studies and Qualitative Insights
Case studies illustrate the qualitative differences between strong and weak models. For example, in identifying the Ngātoroirangi Māori Rock Carvings, Gemini-2.5-Pro provides comprehensive reasoning and cultural context, while GPT-4o-mini offers only a brief description. Additional cases, such as identifying Percé Rock, Olympic Park Beijing, and a golf course in Fiji, demonstrate the platform's ability to challenge models across diverse scenarios.
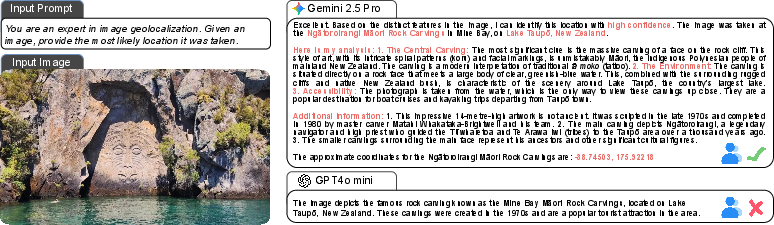
Figure 5: Example of geolocalization: identifying the Ngātoroirangi Māori Rock Carvings, showcasing differences in reasoning depth and factual accuracy.

Figure 6: Case Study: Images Where Strong Models Excel but Weaker Models Fail, highlighting the importance of fine-grained reasoning.

Figure 7: Additional Case Study: Identifying the Percé Rock, demonstrating recognition of unique geological formations.
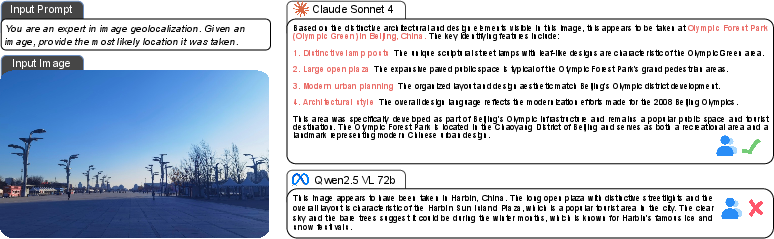
Figure 8: Additional Case Study: Identifying the Olympic Park, Beijing, illustrating proficiency in modern landmark identification.

Figure 9: Additional Case Study: Identifying the Golf Course in Fiji, emphasizing inference based on environmental context.
Implications and Future Directions
GeoArena establishes a new paradigm for benchmarking LVLMs in geolocalization, emphasizing dynamic, privacy-preserving, and human-centered evaluation. The platform's robust ranking methodology, comprehensive model coverage, and release of the GeoArena-1K dataset provide valuable resources for research in reward modeling, geographic foundation models, and multimodal alignment.
The strong performance of proprietary models and the rapid progress of open-source systems suggest that scaling, alignment, and reasoning quality are key drivers of geolocalization capability. The observed gaps in LVLM-human alignment highlight the need for improved evaluators and more nuanced reward modeling. Future work should focus on expanding evaluation to harder cases, enhancing model robustness, and developing more faithful automated judges for multimodal tasks.
Conclusion
GeoArena offers a scalable, interpretable, and user-aligned framework for benchmarking LVLMs on worldwide image geolocalization. By integrating in-the-wild data collection, pairwise human preference evaluation, and rigorous statistical ranking, the platform overcomes the limitations of static benchmarks and provides actionable insights for model development and deployment in geospatial AI. The release of GeoArena-1K and the demonstrated discriminative power of the leaderboard position GeoArena as a foundational resource for advancing research in multimodal geolocalization and human-centered AI evaluation.

