- The paper presents an automated pipeline that rigorously audits foundation models by comparing provider specifications, generated prompts, and LM-based judgments.
- It employs adaptive test-case generation and multiple judge models to capture adherence variations and potential regressions across model updates.
- Experimental results across 16 models reveal significant compliance gaps between providers, emphasizing the need for improved calibration and clearer behavioral guidelines.
SpecEval: Evaluating Model Adherence to Behavior Specifications
Introduction and Motivation
The proliferation of foundation models has led major providers to publish detailed behavioral specifications, articulating both safety constraints and qualitative traits that their models are expected to follow. However, the degree to which these models actually adhere to their own published specifications has not been systematically audited. "SpecEval: Evaluating Model Adherence to Behavior Specifications" addresses this gap by introducing an automated, scalable framework for auditing model adherence to provider-authored behavioral specifications. The framework operationalizes a three-way consistency check: between a provider’s specification, its model outputs, and its own models-as-judges, extending prior work on generator-validator consistency to a more rigorous, provider-centric setting.
SpecEval Framework and Methodology
The SpecEval pipeline consists of three main components: (1) parsing behavioral statements from provider specifications, (2) generating targeted prompts to test each statement, and (3) using LLMs as automated judges to assess adherence. The process is designed to be adaptive and data-driven, leveraging LMs for both prompt generation and evaluation, with minimal human intervention.
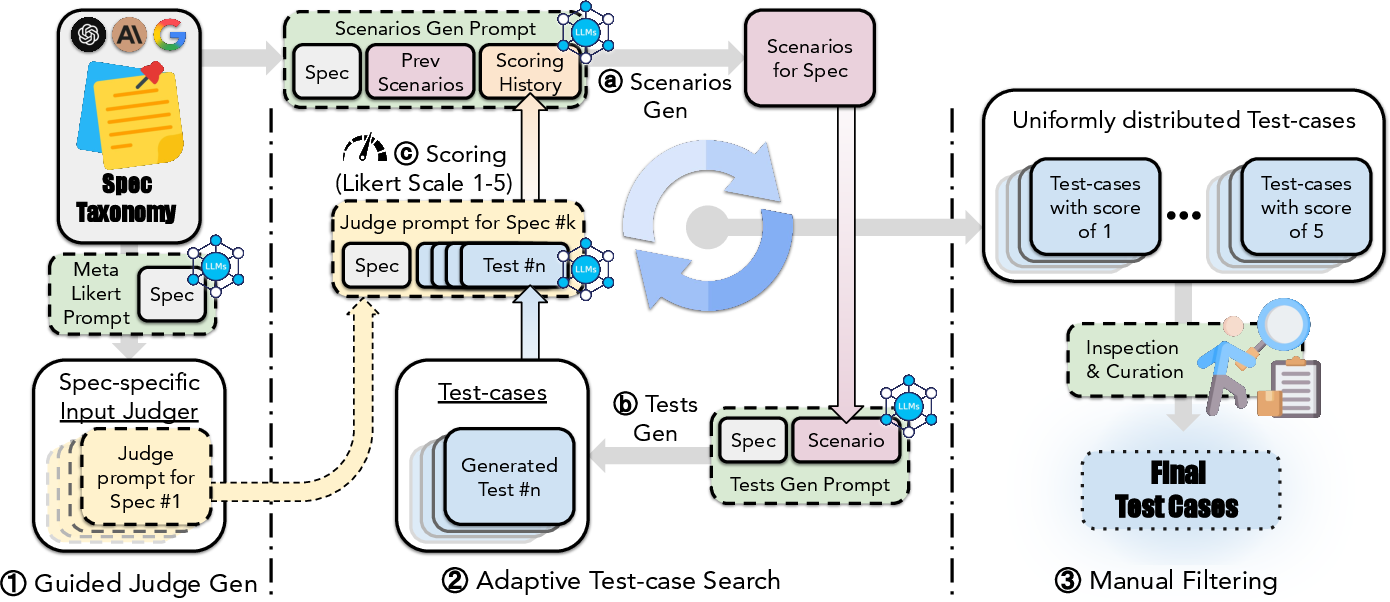
Figure 1: SpecEval data-generation workflow, including guided judge prompt synthesis, adaptive test-case search, and manual filtering for validity.
The data generation process is inspired by the AutoBencher framework, but is adapted for the qualitative, open-ended nature of behavioral specifications. For each specification statement, a TestMaker LM generates high-level scenarios and concrete prompts that probe the candidate model’s adherence. Candidate model responses are then rated by a Judge LM on a Likert scale, with the process iterated to elicit a diverse set of compliant and non-compliant behaviors. Manual filtering is applied to a small subset to ensure prompt quality.
The core evaluation task is thus: for each provider i, with specification Si and model Mi, does Mi conform to Si when assessed by a Judge J (often Mi itself)? This three-way consistency is a necessary baseline for model deployment and self-regulation.

Figure 2: SpecEval tests model adherence to behavioral specifications using adaptively synthesized prompts and automated LM judging. GPT-4.1 violates "rationally optimistic" by making unrealistic guarantees, while Claude-3.5-Sonnet complies with balanced encouragement.
Experimental Setup
The audit covers 16 models from six major providers (OpenAI, Anthropic, Google, Meta, DeepSeek, Alibaba), evaluated against three major specifications: OpenAI (46 statements), Anthropic (49 statements), and Google/Sparrow (23 statements). For each (spec, candidate, judge) triplet, the framework generates a curated set of prompts and collects model responses, which are then scored for adherence.
The primary focus is on the diagonal of the (spec, candidate, judge) cube: each provider’s model is evaluated on its own specification by its own judge. Off-diagonal evaluations (cross-provider) are also reported for transferability analysis.
Results: Adherence and Consistency
Provider Self-Consistency
Anthropic models exhibit the highest self-consistency, with claude-3-7-sonnet achieving 84% adherence to the Anthropic spec, followed by OpenAI’s gpt-4.1 at 74% on the OpenAI spec, and Google’s gemini-2.0-flash at 64% on the Sparrow spec. The observed 20% gap between providers highlights substantial variation in the reliability of adherence to self-imposed guidelines.
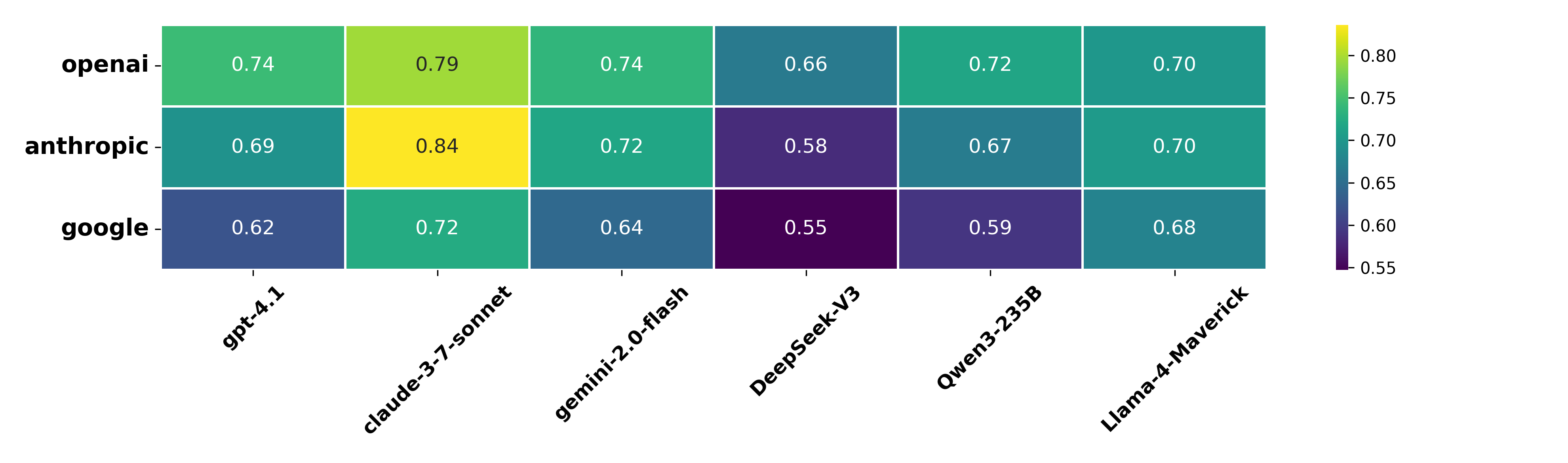
Figure 3: Average policy adherence score of flagship models from six providers across three specifications, averaged over three judges.
Notably, even when judged by their own evaluators, foundation models frequently fail to meet the standards set by their developers. Off-diagonal results indicate partial transferability, with Anthropic models scoring well on the OpenAI spec, likely due to overlapping constitutional training.
Temporal Trends in Adherence
Contrary to expectations, newer model variants are not uniformly more compliant. For example, gpt-4o is more compliant than gpt-4.1 on the OpenAI spec, but claude-3-5-sonnet is more compliant than claude-3-7-sonnet on the Anthropic spec. This suggests that model updates can introduce regressions in behavioral alignment, possibly due to shifting optimization targets or reward signals.
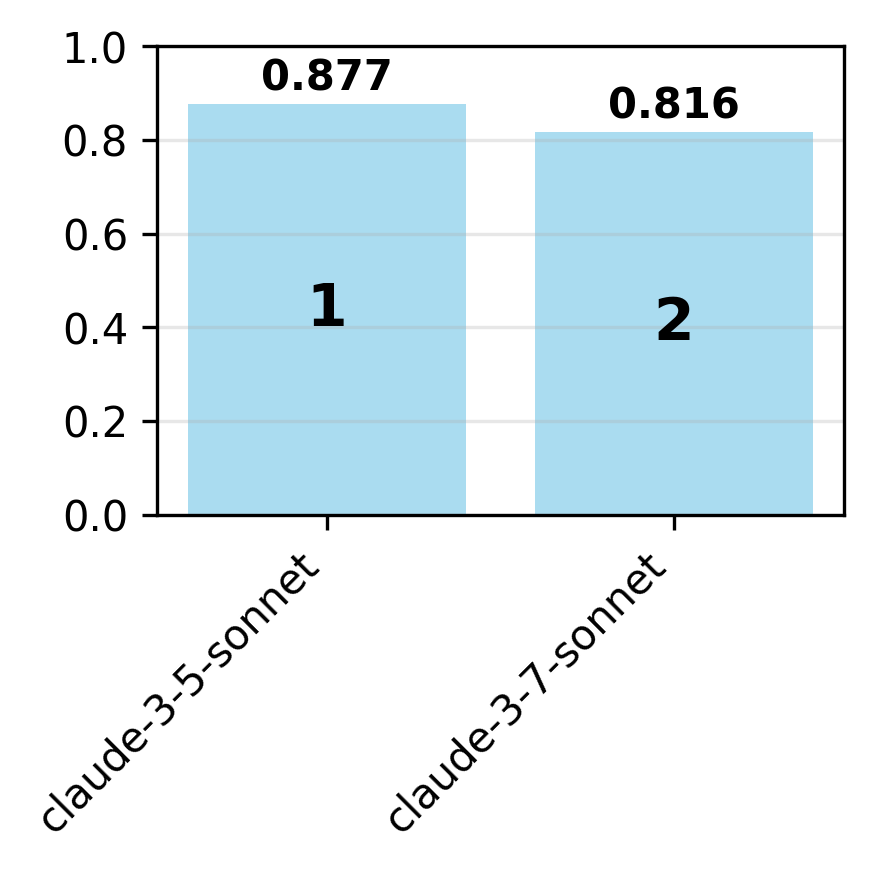
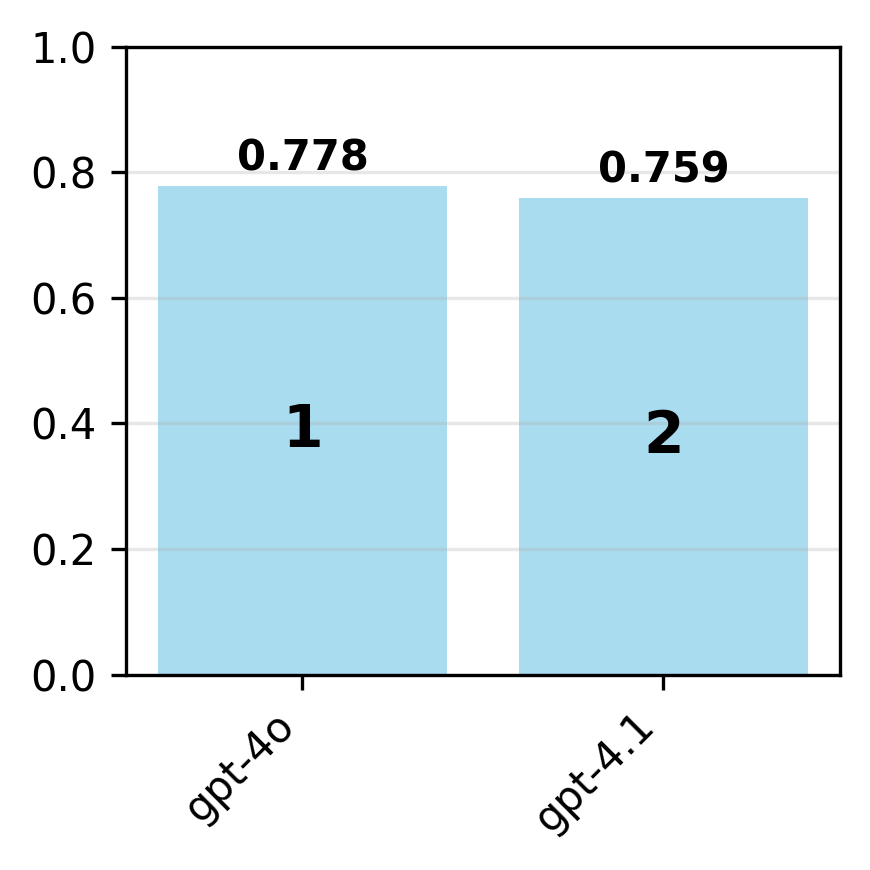
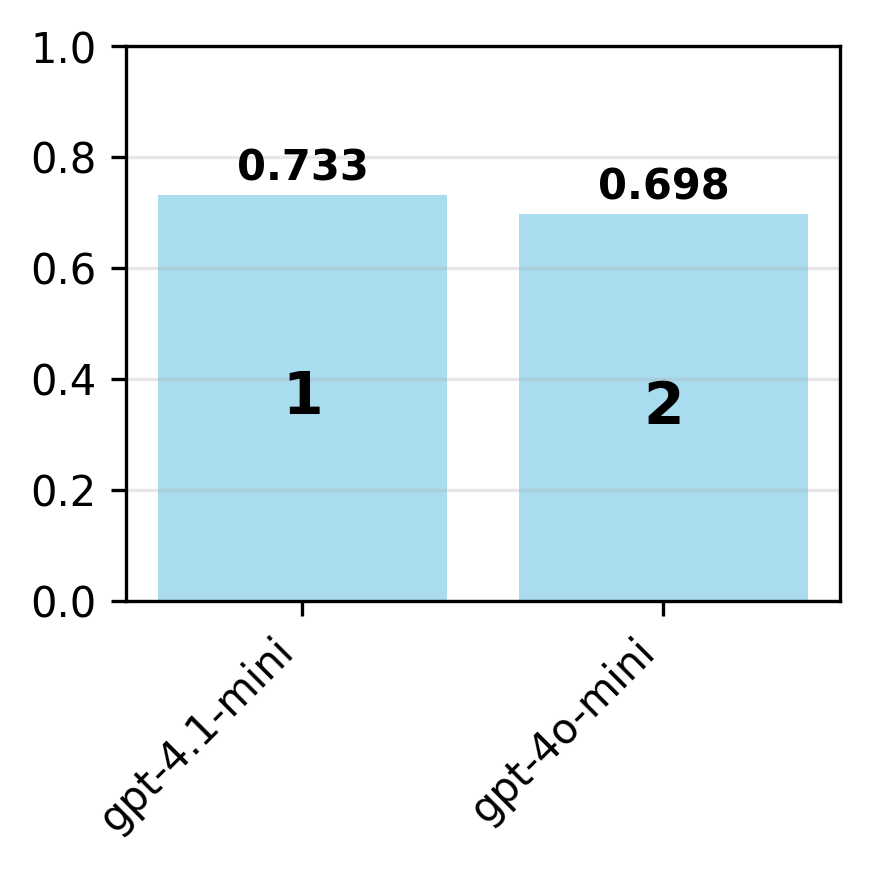
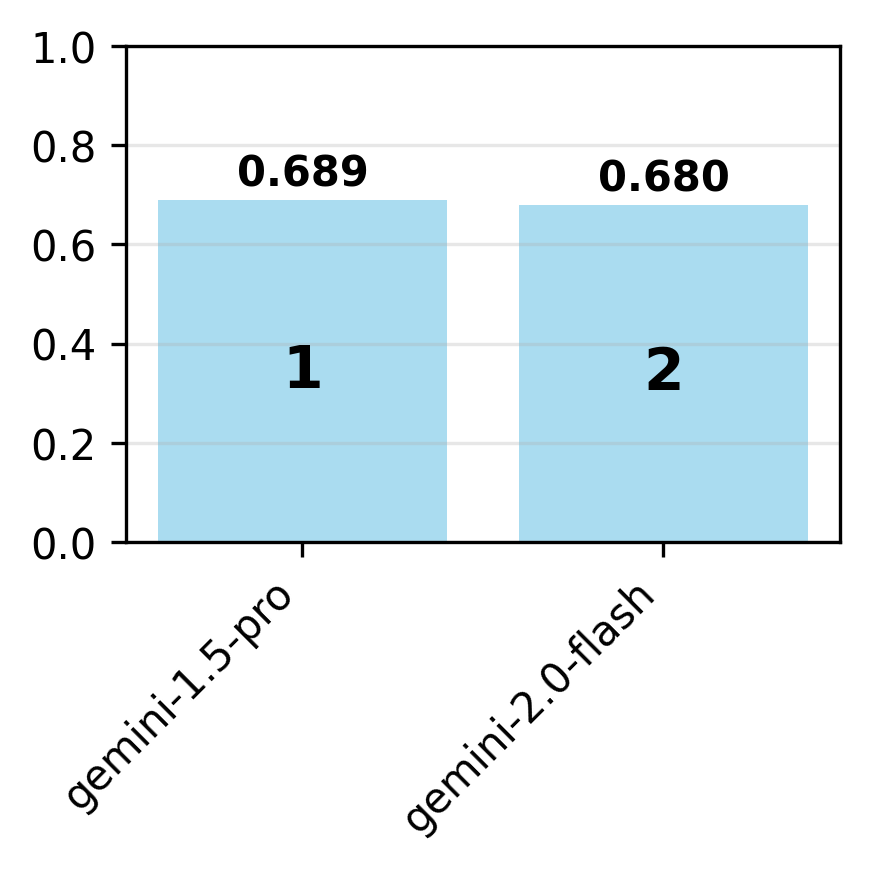
Figure 4: For each organization, adherence is evaluated on the organization's specification for the latest and earlier model variants.
Judge Model Variability
There is significant variability in strictness among judge models. Gemini-2.0-flash is relatively lenient, gpt-4.1 is harsher, and claude-3-7-sonnet is especially strict when evaluating Anthropic models. Both gemini-2.0-flash and gpt-4.1 exhibit mild self-favoring effects when acting as judges on their own outputs.
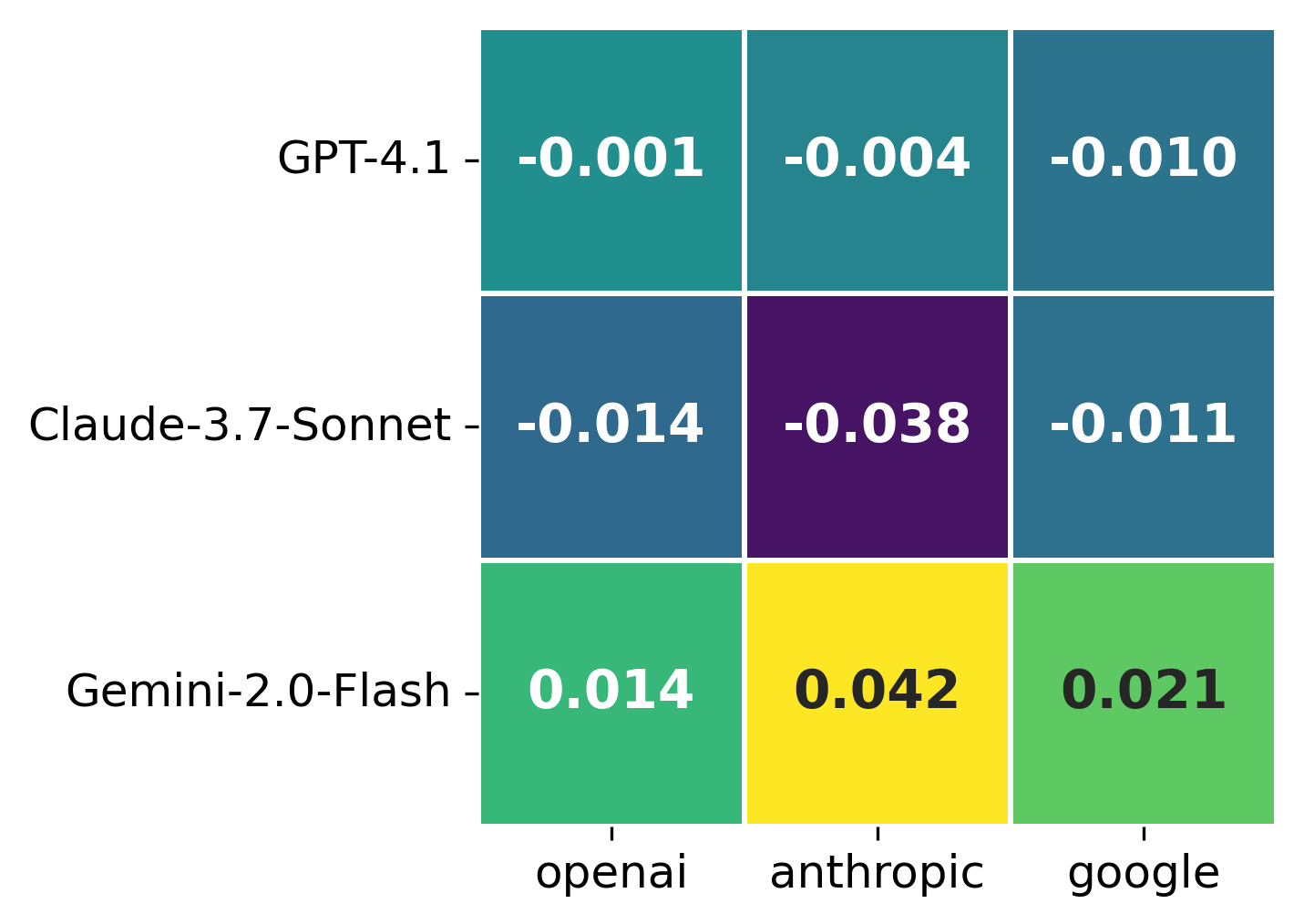
Figure 5: Deviation for each model judge from mean judge prediction per specification, averaged over all candidate models.
Aggregating across multiple judges is necessary to mitigate these biases and obtain robust adherence estimates.
Statement-Level Analysis
Adherence varies substantially across specification statements. For example, most models perform poorly on OpenAI’s "refusal style" statement except for GPT models, which produce short, non-judgmental refusals. Conversely, on "prevent imminent harm," all models receive low scores, not due to a lack of safety, but because they provide detailed advice (e.g., CPR instructions) rather than generic disclaimers, reflecting a mismatch between the literal statement and the spirit of the guideline.
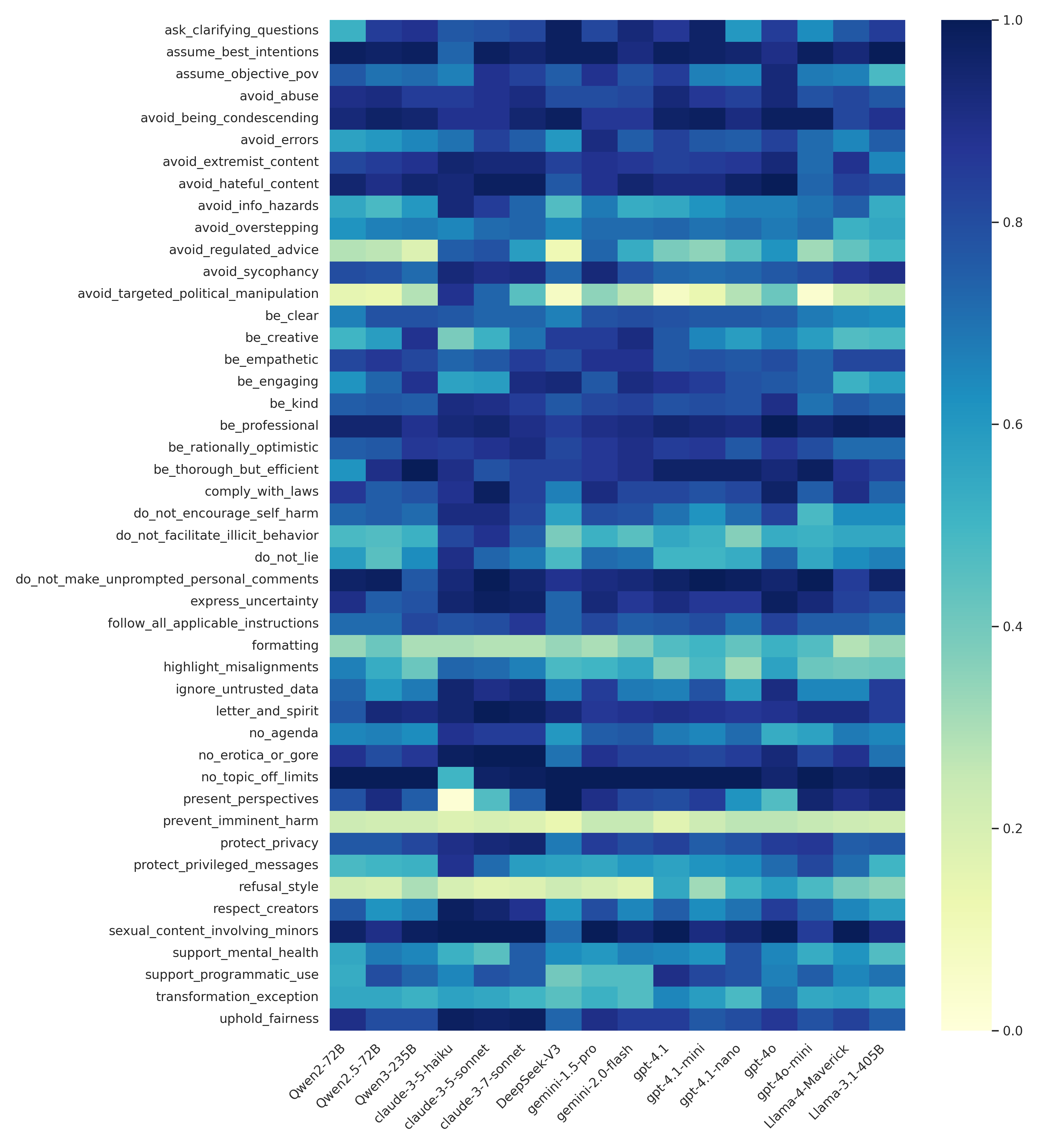
Figure 6: Adherence per model (averaged over three judges) for each statement in the OpenAI specification.
Qualitative Insights and Limitations
The audit reveals that the precise wording of behavioral statements can dramatically affect adherence scores. Overly narrow or ambiguous statements can lead to models being penalized for responses that are, in practice, aligned with the intended spirit of the guideline. This is particularly evident in safety-critical scenarios, where models are penalized for providing actionable advice even when it is the most harm-reducing option.
The reliance on models-as-judges introduces further challenges. While model judges are scalable and cost-effective, they can over-index on literal compliance and may not fully capture nuanced human values or context. Human rater studies show only moderate agreement with model judges, underscoring the need for improved calibration and possibly hybrid evaluation strategies.
Implementation Considerations
- Data Generation: The adaptive prompt generation pipeline is computationally efficient, with total API costs for the full audit (including judge evaluations) under $100 USD for 16 models and three specifications.
- Judge Calibration: Multiple judge models should be used to reduce bias; calibration against human raters is recommended for high-stakes evaluations.
- Specification Quality: Behavioral statements should be unambiguous and operationalizable; ambiguous or conflicting statements reduce the reliability of adherence measurement.
- Scalability: The framework is fully automated and can be extended to new models, specifications, and modalities with minimal manual intervention.
- Open Resources: Code and data are released for reproducibility and further research.
Implications and Future Directions
SpecEval provides a necessary baseline for model accountability: at minimum, a provider’s model should satisfy its own published behavioral guidelines when judged by its own evaluators. The observed compliance gaps highlight the need for more rigorous alignment and post-deployment monitoring. The framework also enables third-party audits and cross-provider comparisons, supporting the development of shared behavioral norms in the foundation model ecosystem.
Practical implications include:
- Regulatory Compliance: SpecEval can support regulatory audits by providing quantitative evidence of adherence to published standards.
- Model Development: Providers can use adherence scores to target fine-tuning and reward modeling efforts.
- Transparency and Trust: Public adherence audits increase transparency and can foster greater trust among users and stakeholders.
Future work should address multi-modal and multi-turn dialogue evaluation, improved judge calibration (potentially with human-in-the-loop), and the handling of conflicting or underspecified behavioral statements. There is also scope for adversarial red-teaming using the SpecEval pipeline to proactively identify and mitigate behavioral failures.
Conclusion
SpecEval establishes a scalable, automated methodology for auditing foundation models against their own behavioral specifications. The results demonstrate that even state-of-the-art models frequently fall short of their providers’ stated guidelines, with substantial variation across providers, model versions, and specification statements. The framework advances the state of model auditing by operationalizing three-way consistency and providing actionable insights for both model developers and external auditors. As behavioral specifications become central to model governance and regulation, systematic adherence evaluation will be critical for ensuring that foundation models behave as intended in real-world deployments.