- The paper introduces a representation-centric framework that enforces semantic alignment between references and targets using Semantic Correspondence Attention Loss and Multi-Reference Disentanglement Loss.
- It employs a meticulously constructed SemAlign-MS dataset and a diffusion transformer backbone to enhance identity preservation and compositional fidelity across subjects.
- Experimental results demonstrate significant improvements in CLIP-I, CLIP-T, and DINO metrics, confirming its superior performance in maintaining semantic coherence over baselines.
MOSAIC: Multi-Subject Personalized Generation via Correspondence-Aware Alignment and Disentanglement
Introduction and Motivation
Multi-subject personalized image generation presents substantial challenges in maintaining identity fidelity and semantic coherence, especially as the number of reference subjects increases. Existing approaches—such as MS-Diffusion, SSR-Encoder, DreamO, and XVerse—incorporate spatial layout guidance or architectural constraints to bind subjects to dedicated regions. However, these methods lack explicit optimization for precise multi-subject alignment and effective disentanglement at the representation level, resulting in identity blending and attribute leakage, particularly when handling more than three subjects.
MOSAIC introduces a representation-centric framework that directly addresses these deficiencies by enforcing explicit semantic correspondence and orthogonal feature disentanglement. The core insight is that multi-subject generation requires precise semantic alignment at the representation level, ensuring that each region in the generated image attends to the correct part of each reference subject. This is operationalized through two novel loss functions: Semantic Correspondence Attention Loss (SCAL) and Multi-Reference Disentanglement Loss (MDL).
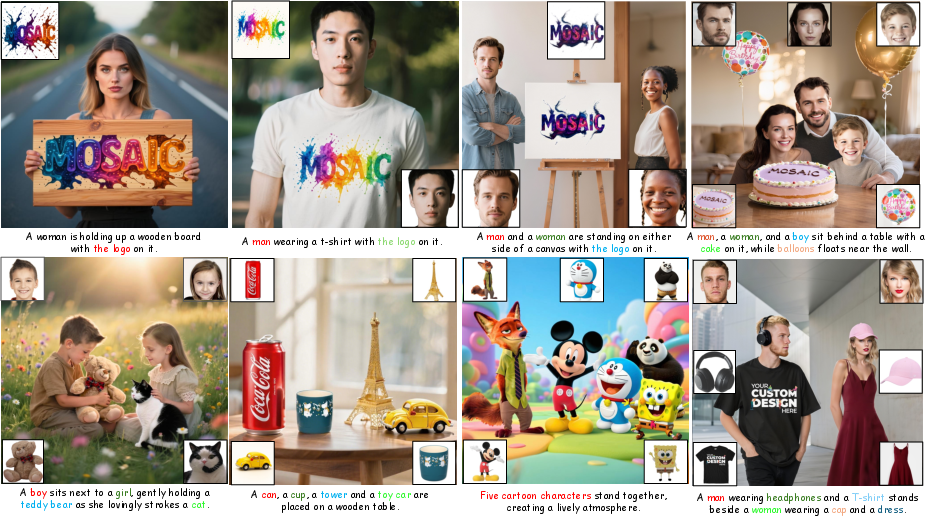
Figure 1: MOSAIC demonstrates capabilities in both single-subject and multi-subject driven generation tasks.
SemAlign-MS: Dataset Construction for Semantic Correspondence
A critical contribution of MOSAIC is the SemAlign-MS dataset, which provides fine-grained semantic correspondences between multiple reference subjects and target images. The dataset is constructed via a five-stage pipeline:
- Prompt Generation: GPT-4o is used to generate diverse multi-subject prompts.
- Image Synthesis: State-of-the-art T2I models synthesize images from prompts.
- Automated Filtering: Images are filtered for quality, subject clarity, and compositional coherence.
- Segmentation: Lang-SAM segments subjects for precise identification.
- Viewpoint Correction: FLUX Kontext ensures diversity in viewpoints and poses.
Semantic point correspondences are established between each target and reference image, with disjointness constraints to prevent ambiguous supervision. The resulting dataset comprises 1.2M high-quality image pairs with validated semantic correspondences.
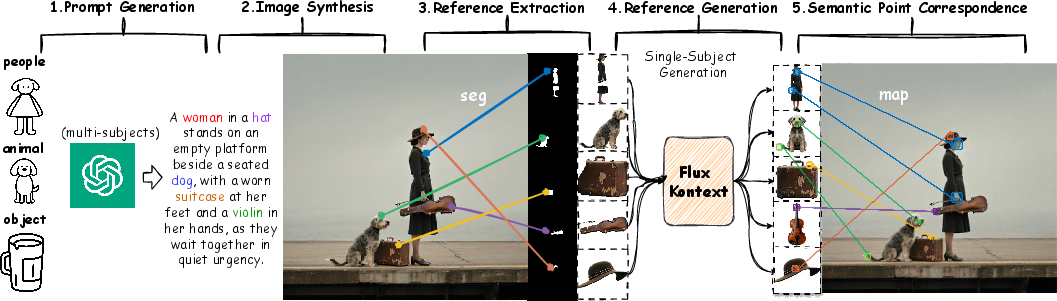
Figure 2: SemAlign-MS Dataset Construction Pipeline for generating high-quality multi-reference training data with validated semantic correspondences.
MOSAIC Framework: Architecture and Optimization
Architecture
MOSAIC leverages a diffusion transformer backbone (FLUX-1.0-DEV) with LoRA augmentation for reference processing. Reference latents are concatenated and processed jointly, enabling multi-modal attention computation. Modified Rotary Position Embeddings (RoPE) with distinct frequency bases are applied for spatial disentanglement.
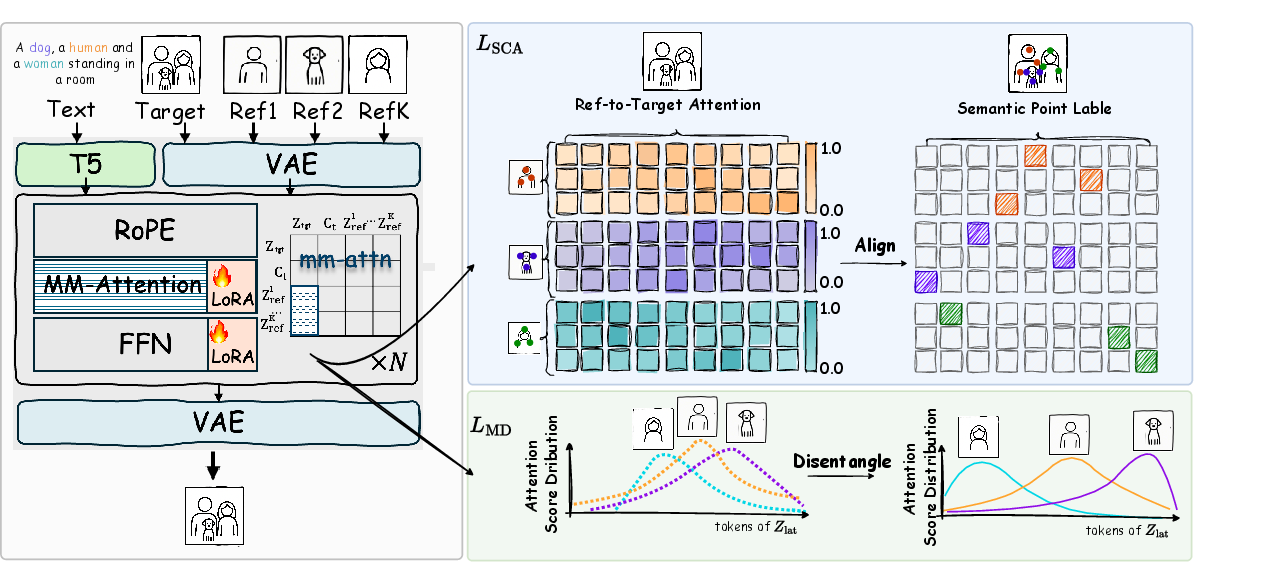
Figure 3: Overview of MOSAIC Framework, highlighting Semantic Correspondence Attention Loss and Multi-Reference Disentanglement Loss.
Semantic Correspondence Attention Loss (SCAL)
SCAL enforces point-wise semantic alignment by supervising the reference-to-target attention matrix. For each annotated correspondence (u,v), cross-entropy loss is applied to the attention score Aref→tgt[u,v], averaged across all DiT blocks. This mechanism ensures that each reference token attends precisely to its designated region in the target latent, preserving fine-grained details and local structure.
Multi-Reference Disentanglement Loss (MDL)
MDL maximizes the divergence between attention distributions of different references using symmetric KL regularization. For each reference, attention patterns at correspondence locations are aggregated and normalized. The loss penalizes overlap in attention regions, pushing each subject into orthogonal representational subspaces and mitigating cross-subject feature interference.
The overall training objective is:
L=Ldiff+αLSCA+βLMD
where Ldiff is the flow-matching loss, and α, β are balancing factors.
Experimental Results
Quantitative Evaluation
MOSAIC is evaluated on DreamBench and XVerseBench, outperforming all baselines in both single- and multi-subject scenarios. On DreamBench, MOSAIC achieves 84.30 (CLIP-I), 31.64 (CLIP-T), and 77.40 (DINO) in single-subject settings, and 76.30 (CLIP-I), 32.40 (CLIP-T), and 56.83 (DINO) in multi-subject settings, with consistent margins over the next-best methods. On XVerseBench, MOSAIC attains the highest overall average score (76.04), with strong identity preservation (ID-Sim: 81.98/69.90) and perceptual similarity (IP-Sim: 80.92/74.27).
Qualitative Analysis
MOSAIC demonstrates superior appearance consistency and scalability in multi-subject generation. Competing methods exhibit object omission, duplication, and identity confusion as subject count increases, while MOSAIC maintains fidelity and compositional coherence even with four or more subjects.

Figure 4: Qualitative comparison on single and multi-subject driven generation. MOSAIC preserves identity and compositional integrity where other methods degrade.
Ablation Studies
Ablation experiments confirm the necessity of both SCAL and MDL. Adding SCAL improves CLIP-I from 73.45 to 75.89 and DINO from 52.03 to 55.99. Incorporating MDL further boosts CLIP-I to 76.30 and DINO to 56.83. Visualizations show progressive improvement in attention alignment and disentanglement, with the full MOSAIC model achieving precise semantic mapping and effective separation of subject features.


Figure 5: Ablation study of MOSAIC, illustrating the impact of SCAL and MDL on compositional fidelity and attention alignment.
Implementation Details
- Base Model: FLUX-1.0-DEV
- LoRA Rank: 128
- Optimizer: AdamW, learning rate 1e-4
- Training Steps: 100K, batch size 1 per GPU
- Loss Weights: α=0.4, β=0.6
- Plug-and-Play Design: MOSAIC can be integrated into existing diffusion frameworks with minimal architectural changes.
Implications and Future Directions
MOSAIC establishes a new paradigm for multi-subject personalized generation by directly supervising semantic correspondence and enforcing disentanglement at the representation level. The approach scales robustly to complex compositions with four or more subjects, a regime where prior methods fail. The release of SemAlign-MS will facilitate further research in controllable generation and semantic correspondence modeling.
Potential future directions include:
- Extending correspondence-aware supervision to video and 3D generation tasks.
- Investigating more efficient annotation strategies for semantic correspondences.
- Exploring adaptive disentanglement mechanisms for dynamic subject counts.
Conclusion
MOSAIC advances multi-subject personalized image generation by introducing explicit semantic correspondence supervision and orthogonal feature disentanglement. The framework achieves state-of-the-art performance in both identity fidelity and semantic consistency, with robust scalability to complex multi-subject scenarios. The SemAlign-MS dataset provides a valuable resource for future research, and the methodology sets a precedent for representation-centric optimization in controllable generative modeling.

