- The paper introduces BM-CL, a two-stage framework that reconceptualizes bias mitigation as a continual learning problem to preserve advantaged group performance while boosting disadvantaged group accuracy.
- It integrates established continual learning regularizers like Learning without Forgetting and Elastic Weight Consolidation to combat catastrophic forgetting during bias mitigation.
- Empirical results on datasets such as Waterbirds, CelebA, and CheXpert demonstrate BM-CL’s effectiveness in reducing group disparities with minimal best-group degradation.
Introduction
The persistent challenge of group-level disparities in machine learning models, particularly the "leveling-down effect" where improvements for disadvantaged groups come at the expense of advantaged groups, has motivated the development of new fairness interventions. The BM-CL (Bias Mitigation through Continual Learning) framework reconceptualizes bias mitigation as a continual learning (CL) problem, leveraging established CL techniques—Learning without Forgetting (LwF) and Elastic Weight Consolidation (EWC)—to address catastrophic forgetting of advantaged group performance during fairness optimization. This essay provides a technical analysis of BM-CL, its implementation, empirical results, and implications for future research in fair machine learning.
BM-CL Framework: Continual Learning for Fairness
BM-CL is structured as a two-stage training process:
- Stage 1: Baseline Training via ERM The model is trained using empirical risk minimization (ERM) on the full dataset. After this phase, group-wise accuracies are computed, and groups are partitioned into best-performing (Gbest) and worst-performing (Gworst) subsets based on a balanced accuracy threshold.
- Stage 2: Fine-tuning with Bias Mitigation and CL Regularization The model is fine-tuned using a bias mitigation method (e.g., GroupDRO, ReSample), with an added CL regularizer to preserve performance on Gbest. The overall loss is:
LBM-CL(θ)=LBM(θ)+λLCL(θ)
where LBM is the bias mitigation loss, LCL is the CL regularization term, and λ controls the regularization strength.

Figure 1: Overview of the BM-CL framework, illustrating the two-stage process: initial ERM training and subsequent fine-tuning with bias mitigation and continual learning regularization.
Continual Learning Regularizers
Implements knowledge distillation by minimizing the KL divergence between the current and previous model outputs for samples in Gbest, thus preserving their predictive distributions.
- Elastic Weight Consolidation (EWC):
Penalizes changes to parameters critical for Gbest by weighting the squared difference between current and previous parameters with the Fisher information matrix.
This modular approach allows BM-CL to be combined with any bias mitigation method and any CL regularizer, making it extensible to a wide range of fairness interventions.
Experimental Protocol
Datasets
BM-CL was evaluated on three datasets with distinct bias characteristics:
- Waterbirds: Simulates spurious correlations between bird type and background.
- CelebA: Contains spurious correlations between hair color and gender.
- CheXpert: Medical imaging dataset with demographic imbalance (age groups).
All experiments used a ResNet-50 backbone, with hyperparameters tuned for each dataset. Performance was assessed using global accuracy, balanced accuracy, best- and worst-group accuracies, and disparity metrics.
Empirical Results
BM-CL consistently achieved the lowest leveling-down effect—i.e., minimal degradation in best-group accuracy—while delivering competitive or superior improvements in worst-group accuracy compared to state-of-the-art bias mitigation methods.
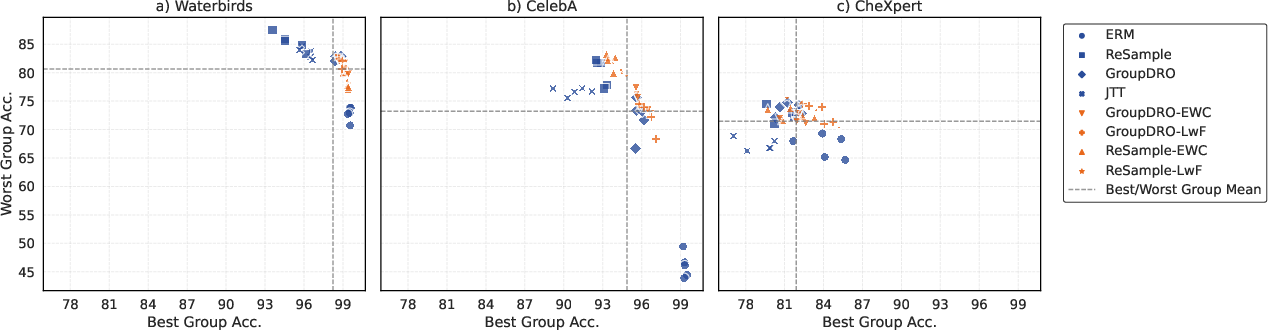
Figure 2: Scatter plot comparing best- and worst-group accuracies across datasets and methods. BM-CL variants (orange) cluster in the upper-right, indicating strong performance for both groups.
Waterbirds
- ERM: High best-group accuracy (99.5%) but low worst-group accuracy (72.8%).
- GroupDRO/ReSample: Improved worst-group accuracy (up to 85.5%) but with notable best-group degradation.
- BM-CL (LwF/EWC): Maintained best-group accuracy (99.0–99.3%) with improved worst-group accuracy (up to 81.6%), minimizing the leveling-down effect.
CelebA
- ERM: Large disparity (best: 99.3%, worst: 46.1%).
- BM-CL (ReSample-EWC): Achieved 93.6% best-group and 82.2% worst-group accuracy, outperforming ReSample alone in both metrics.
CheXpert
- ERM: Substantial group disparity (best: 84.1%, worst: 67.1%).
- BM-CL (GroupDRO-LwF): Achieved 83.6% best-group and 73.0% worst-group accuracy, with the smallest best-group degradation among all methods.
Training Dynamics
BM-CL's two-stage process was visualized on Waterbirds, showing that after initial ERM training, fine-tuning with BM-CL improved worst-group accuracy without significant loss for the best group.
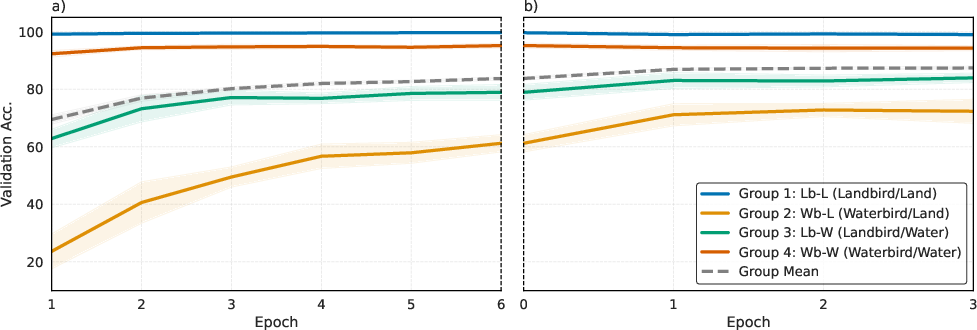
Figure 3: Validation accuracy during BM-CL training on Waterbirds. Stage 1 (ERM) rapidly fits advantaged groups; Stage 2 (BM-CL) improves disadvantaged groups while preserving advantaged group performance.
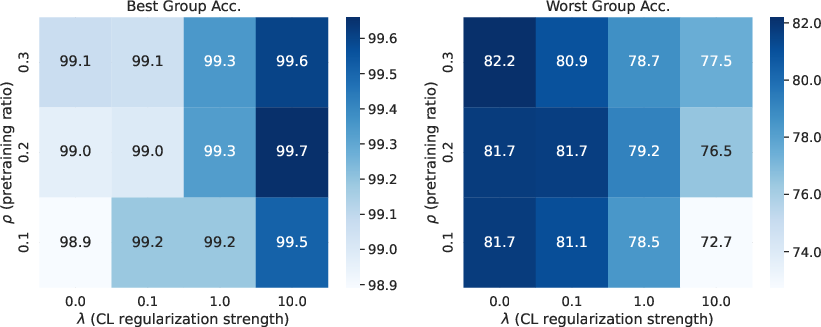
Hyperparameter Sensitivity
An ablation study on the pretraining ratio (ρ) and CL regularization strength (λ) revealed:
Implementation Considerations
LwF is more efficient than EWC, as it only requires storing previous outputs rather than computing the Fisher information matrix.
BM-CL can be integrated with any bias mitigation method and CL regularizer, facilitating adaptation to new domains or fairness definitions.
The two-stage process is compatible with large-scale datasets and deep architectures, as demonstrated with ResNet-50 on ImageNet-scale data.
Theoretical and Practical Implications
BM-CL reframes fairness interventions as a stability-plasticity trade-off, analogous to continual learning. This perspective enables the application of a broad range of CL techniques to fairness problems, potentially leading to more robust and equitable models. The empirical results support the claim that positive-sum fairness—improving disadvantaged groups without sacrificing advantaged groups—is achievable with this approach.
Notably, BM-CL challenges the prevailing assumption that fairness necessarily entails a trade-off with overall or advantaged group performance. The framework's extensibility suggests future research directions, including:
- Exploring alternative CL regularizers (e.g., memory-based, parameter isolation).
- Extending to multi-class, multi-label, or regression settings.
- Integrating with causal inference frameworks for bias mitigation.
Conclusion
BM-CL provides a principled, modular approach to bias mitigation by leveraging continual learning to address catastrophic forgetting of advantaged group performance. Empirical evidence demonstrates that BM-CL achieves strong worst-group improvements while minimizing the leveling-down effect, outperforming conventional bias mitigation methods. This work establishes a foundation for future research at the intersection of fairness and continual learning, with significant implications for the development of equitable and reliable machine learning systems.