- The paper presents a novel RL framework (GRPO) that trains multimodal LLMs to iteratively select and reason with external visual tools.
- It demonstrates significant improvements, with up to 9.44% gain on CV-Bench, outperforming instruct-tuned, text-only, and commercial models.
- The study underlines the need for balanced tool usage and robust error handling to overcome challenges like tool misinterpretation and human bias in data.
Introduction
The paper "Reinforced Visual Perception with Tools" (ReVPT) (2509.01656) presents a reinforcement learning (RL) framework for training multimodal LLMs (MLLMs) to reason with and utilize external visual tools. The motivation stems from the limitations of supervised finetuning (SFT) approaches, which require expensive data curation, aggressive filtering, and exhibit poor generalization to unseen tools or tasks. ReVPT leverages RL—specifically, Group Relative Policy Optimization (GRPO)—to enable adaptive, exploratory tool selection and reasoning, thereby enhancing perception-centric capabilities in MLLMs.
ReVPT is a two-stage training pipeline. The first stage, "cold-start," uses SFT on synthetic tool-use trajectories to bootstrap the model's ability to invoke tools. The second stage applies GRPO-based RL, allowing the model to interact with a tool environment and optimize its policy for tool selection and reasoning.
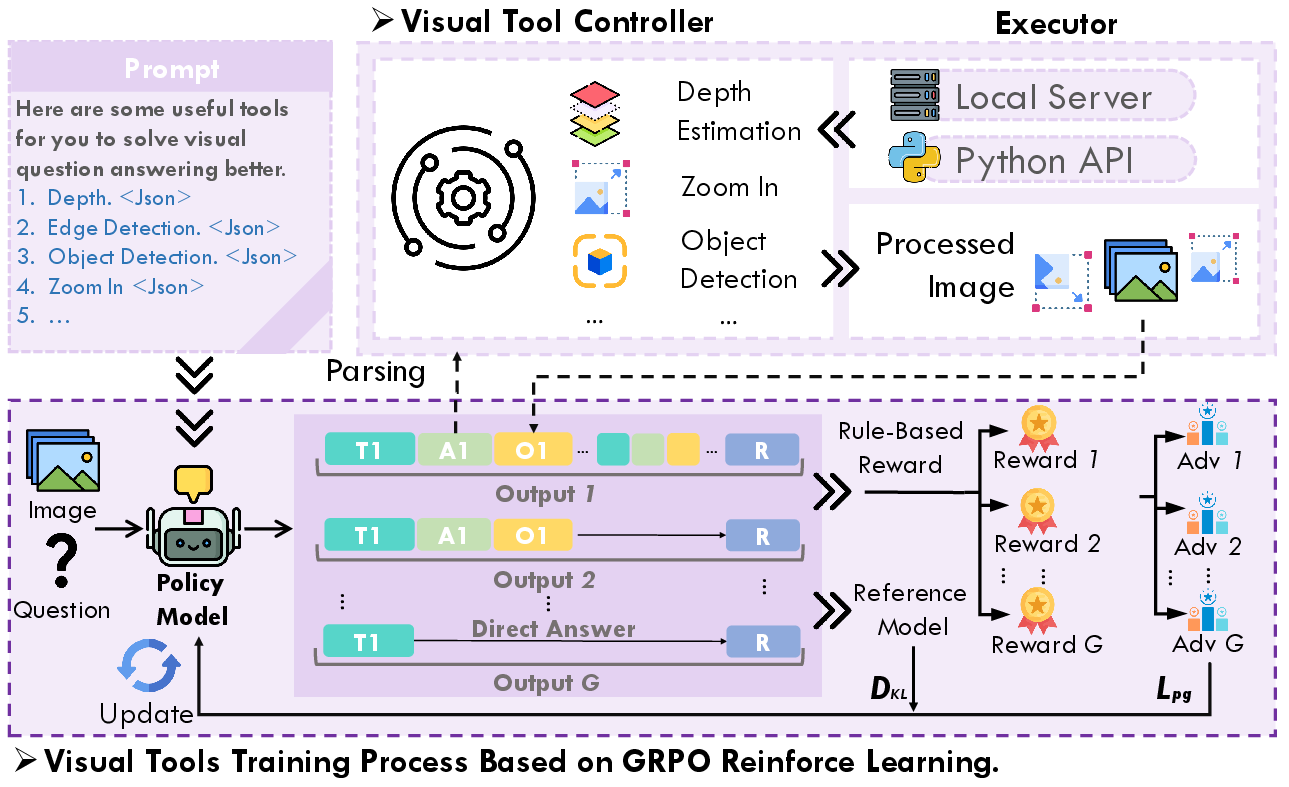
Figure 1: The ReVPT pipeline: model-generated tool requests are managed by a Tool Controller, which deploys visual tool services and feeds outputs back to the LVLM for iterative reasoning via K-turn rollouts.
The tool suite comprises four high-impact visual tools: object detection, zoom-in, edge detection, and depth estimation. These tools are invoked as part of the model's reasoning chain, with outputs fed back for further analysis. The RL reward is binary, based on correctness and format adherence, leveraging ground-truth data for reliable evaluation and avoiding reward hacking.
Experimental Results
ReVPT is evaluated on Qwen2.5-VL-3B and Qwen2.5-VL-7B models across multiple perception-heavy benchmarks (CV-Bench, BLINK, MMVP, MMStar, BLINK-Hard). The results demonstrate that ReVPT models consistently outperform both instruct-tuned and text-only RL baselines, with ReVPT-3B and ReVPT-7B achieving 9.03% and 9.44% improvements on CV-Bench over instruct models.
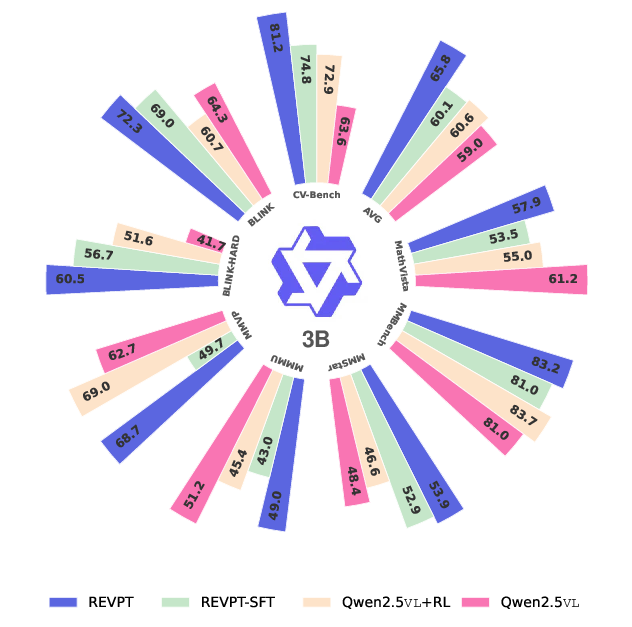
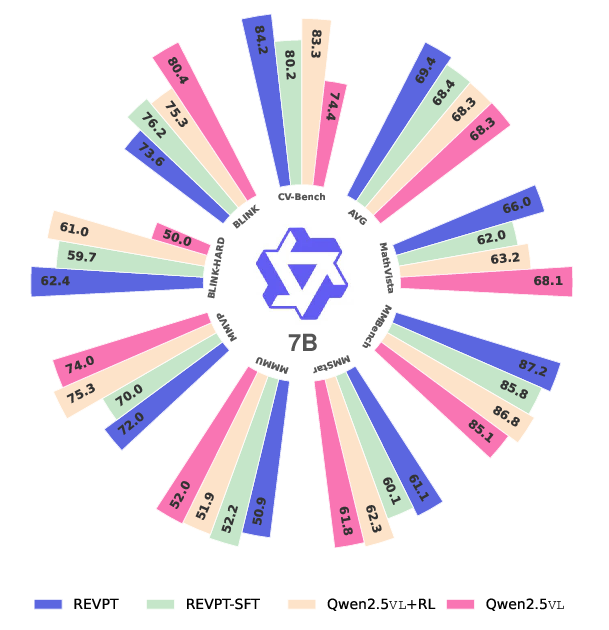
Figure 2: ReVPT-3B and 7B outperform instruct and text-only GRPO counterparts on perception-centric tasks while maintaining strong general capabilities.
Notably, ReVPT models surpass commercial models (GPT-4.1, Gemini-2.0-Flash) on challenging BLINK-Depth and Relation subsets, indicating that RL-driven tool-use can unlock latent perception capabilities inaccessible via SFT or text-only RL.

Figure 3: Step-by-step visual reasoning breakdowns for challenging examples, illustrating ReVPT's superior tool-use and reasoning compared to GPT-4.1.
Data Construction and Training Dynamics
High-quality, verified data is essential for effective RL training. The cold-start phase uses GPT-4.1 to synthesize tool-augmented reasoning traces, which are filtered for correctness. RL training is performed on questions that base models answer incorrectly, incentivizing exploration and adaptation.
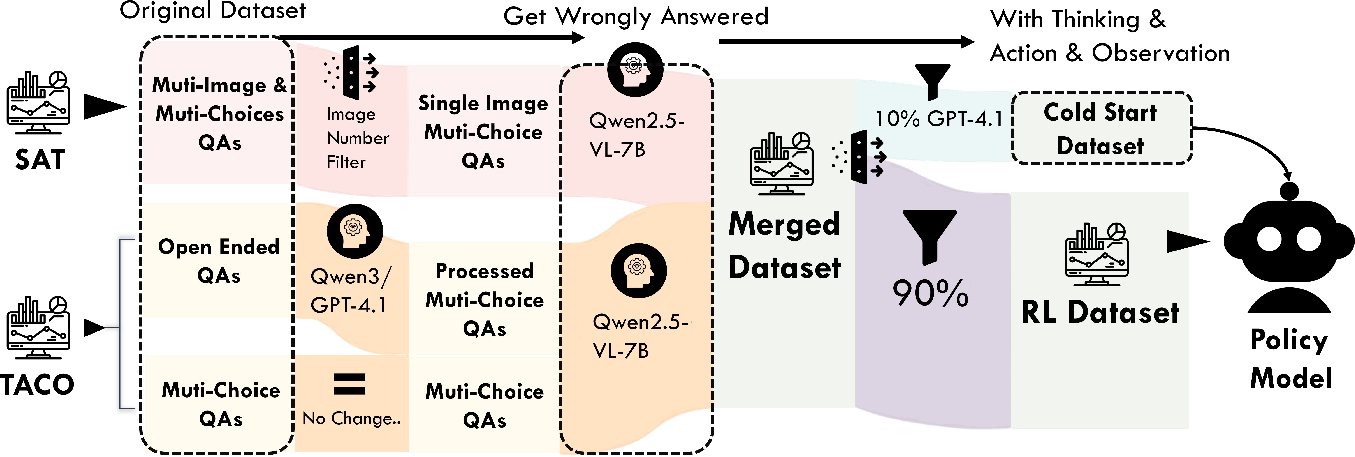
Figure 4: Data pipeline for reinforced visual tool-usage training, including transformation to MCQA format and filtering for question difficulty.
Tool usage analysis reveals a bias toward object detection and depth estimation, attributed to cold-start data construction. RL training shifts tool selection strategies, increasing accuracy on perception tasks.
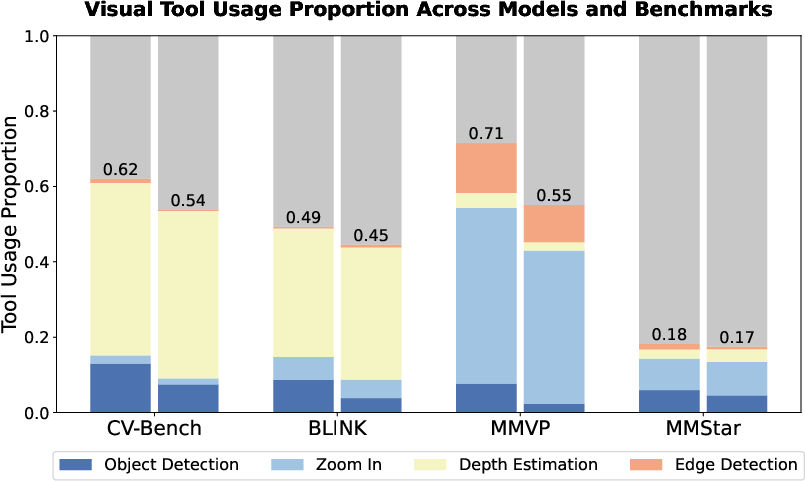
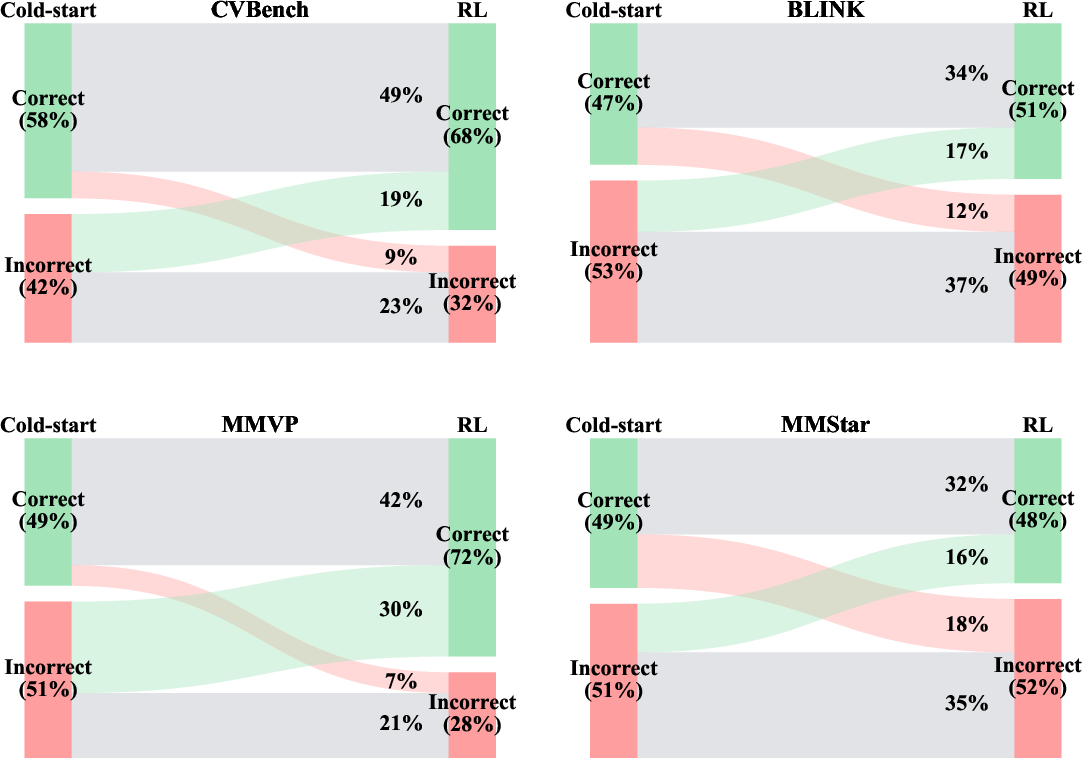
Figure 5: Tool utilization bias after cold-start, with object detection and depth estimation favored over zoom and edge detection.
Ablation and Failure Analysis
Ablation studies confirm that both tool-use data and general data are necessary to preserve general capabilities while enabling effective tool usage. Removing key tools (object detection, depth estimation) degrades performance, underscoring their importance.
Failure modes are analyzed, including incorrect tool outputs, misinterpretation of tool results, inappropriate tool usage, and selection of unhelpful tools. These cases highlight the limitations of current tool integration and the need for improved tool reliability and model-tool alignment.
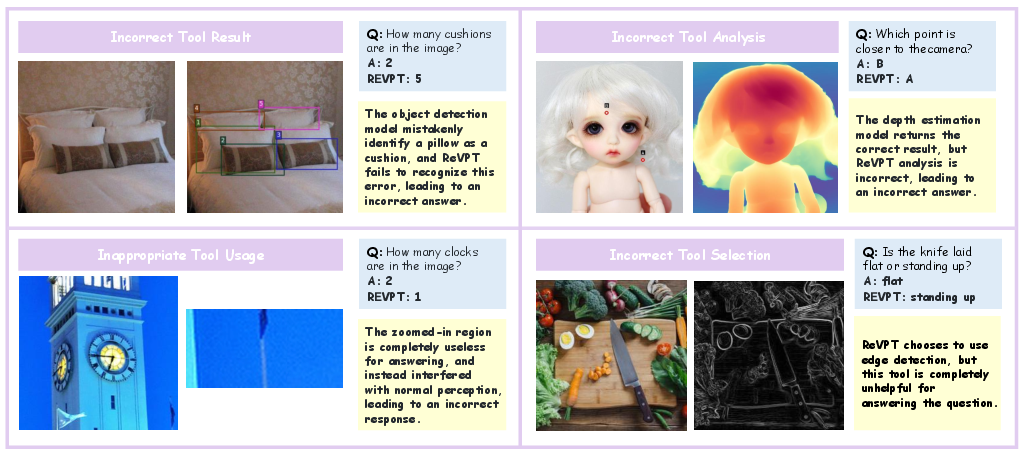
Figure 6: Case studies of ReVPT failure modes: incorrect tool output, misinterpretation, inappropriate usage, and unhelpful tool selection.
Discussion: Implications and Future Directions
The utility of visual tools is non-monotonic with model scale. Smaller models benefit substantially from tool integration, while larger models exhibit diminishing returns due to stronger native perception. However, advanced models may leverage dynamic code generation for sophisticated multi-step reasoning, suggesting evolving roles for tool integration.
Tool selection fundamentally constrains downstream performance. Cold-start phases require commitment to a specific tool repertoire, and proficiency across diverse tools demands comprehensive, balanced training datasets. The development of richer, more diverse data ecosystems is critical for advancing visual tool learning.
Human Bias and Autonomous Discovery
Current training paradigms inject human biases via synthetic demonstrations in cold-start phases. As models scale, autonomous discovery of tool-use strategies should be prioritized, but practical limitations necessitate initial human guidance. Future work should address computational scaling challenges and minimize human-centric bias in tool-use learning.
The paper provides detailed case studies illustrating both successful tool usage and failure cases. For example, edge detection and zoom-in tools are used to localize objects and refine bounding boxes, while object detection and depth estimation facilitate counting and spatial reasoning. Errors arise from flawed tool outputs and model misinterpretation, emphasizing the need for robust tool integration and error handling.


Figure 7: Edge Detection tool used for spatial localization.


Figure 8: Zoom In tool used for bounding box refinement.


Figure 9: Object Detection tool used for counting objects.


Figure 10: Depth Estimation tool used for spatial reasoning.


Figure 11: Model misunderstanding of Object Detection results.


Figure 12: Model misunderstanding of Depth Estimation results.

Figure 13: Flawed Object Detection results leading to reasoning errors.
Conclusion
ReVPT demonstrates that RL-driven tool-use training can substantially enhance perception-centric capabilities in MLLMs, outperforming SFT and text-only RL baselines and even commercial models on challenging benchmarks. The framework's modularity, reliance on verified rewards, and open-source release position it as a valuable resource for the community. Future research should focus on scaling tool repertoires, minimizing human bias, and developing robust, autonomous tool-use strategies to further advance multimodal reasoning in AI systems.