- The paper demonstrates that distilled pretraining improves test-time scaling by learning high-entropy distributions with fewer data samples.
- The paper shows that DPT impairs in-context learning by weakening induction heads through noisy soft labels.
- The paper provides practical guidelines like token routing and teacher selection to balance diversity in generation with contextual fidelity.
Distilled Pretraining: Trade-offs in Data, In-Context Learning, and Test-Time Scaling
Introduction
This paper presents a comprehensive analysis of distilled pretraining (DPT) in LLMs, focusing on its effects beyond classical statistical modeling. The authors systematically investigate DPT in regimes where teacher and student models are trained on identical data (IsoData), and examine its impact on two critical modern LLM capabilities: in-context learning (ICL) and test-time scaling (TTS). The work provides both empirical and theoretical insights, including controlled bigram model experiments, and offers practical guidelines for practitioners.
Distillation Beyond Data Augmentation
A central question addressed is whether the empirical gains from DPT are solely attributable to the teacher's exposure to more data, or if DPT confers unique benefits even when teacher and student see the same data. IsoData experiments (Figure 1) demonstrate that DPT yields consistent improvements on standard language modeling tasks, even when both models are trained on the same 1T tokens.
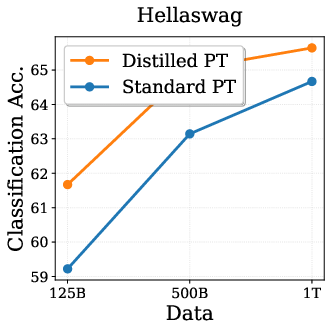
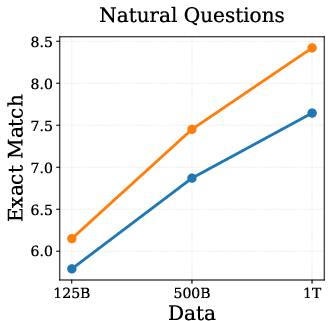
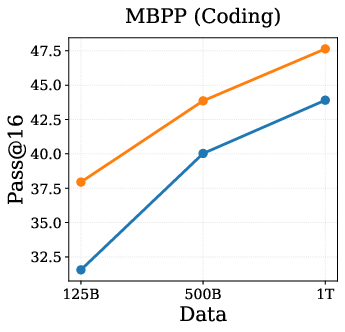
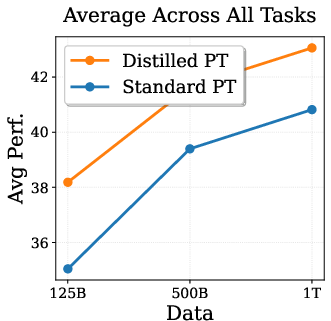
Figure 1: IsoData Distillation: DPT outperforms standard pretraining on standard tasks even when teacher and student see identical data.
Theoretical analyses suggest that these gains are not explained by sample complexity or optimization speedups, but rather by implicit regularization effects that act through the singular spectrum of learned representations. This finding is robust to compute-matched conditions and highlights the relevance of DPT as LLMs approach the data wall.
Trade-off: In-Context Learning vs. Test-Time Scaling
Distillation Impairs In-Context Learning
Empirical results show that DPT impairs ICL, especially in the IsoData regime. As training data increases, the advantage of DPT over standard pretraining diminishes and eventually reverses on ICL tasks such as context-based QA, needle-in-haystack, and counterfactual QA (Figure 2).
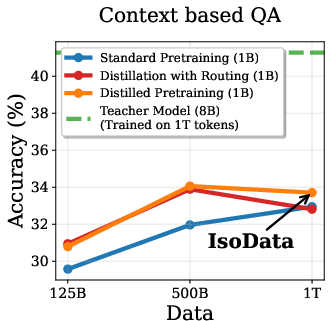
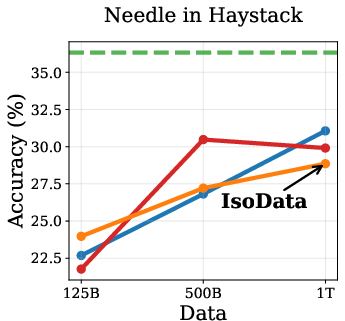
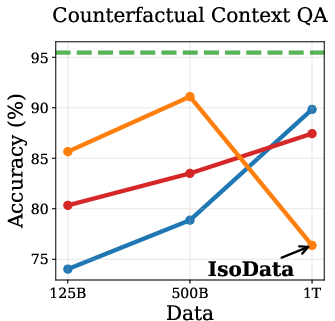
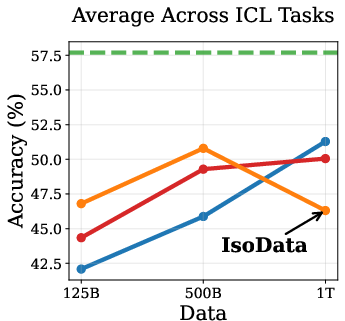
Figure 2: Token Routing: Mitigating the Drop in In-Context Learning. DPT underperforms on ICL tasks as data increases, but token routing partially mitigates this.
This degradation is attributed to the weakening of induction heads—transformer circuits responsible for copying tokens from context. Induction tasks rely on low-entropy mappings, where soft labels from imperfect teachers introduce noise, hindering the learning of deterministic copying behavior.
Distillation Enhances Test-Time Scaling and Diversity
Conversely, DPT markedly improves TTS, as measured by pass@k metrics on reasoning and coding benchmarks (GSM8k, MATH, MBPP). DPT-trained models exhibit higher generation diversity, outperforming standard pretraining even when the latter is trained on twice the data (Figure 3).
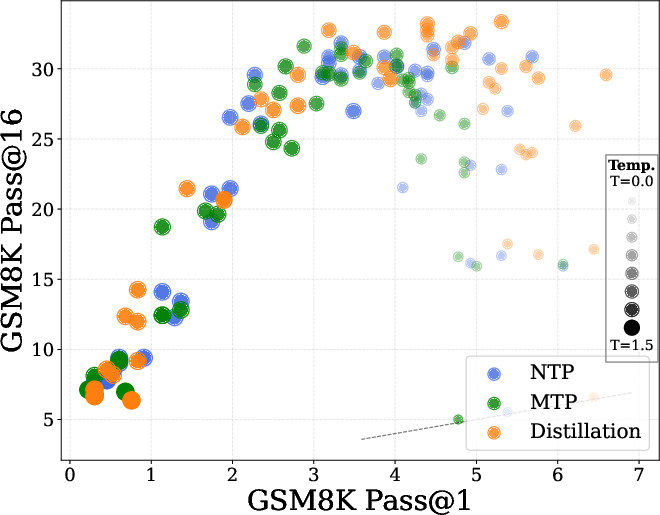
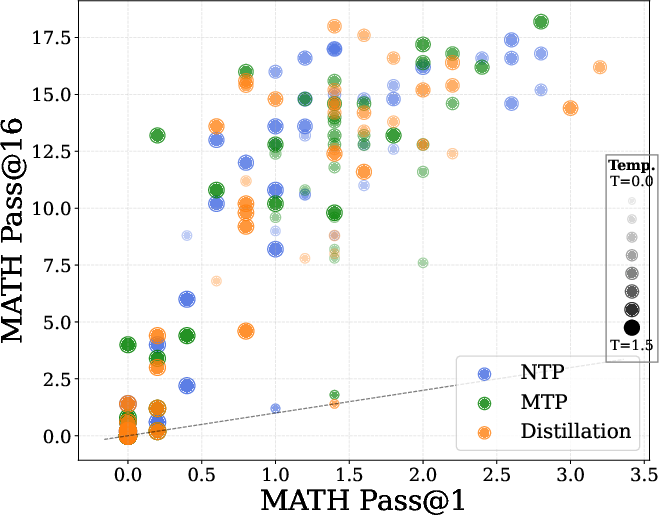
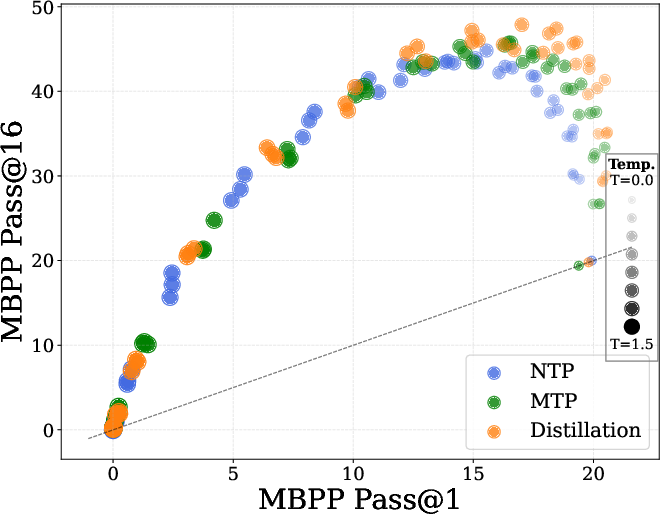
Figure 3: NTP vs MTP vs Distillation: DPT yields superior pass@k curves, indicating enhanced diversity and TTS, even in data-matched regimes.
The mechanism is formalized in a bigram sandbox, where DPT accelerates learning of high-entropy rows (prompts with multiple plausible completions), but offers no advantage for low-entropy rows (deterministic transitions). Sample complexity analysis confirms that DPT requires fewer samples to approximate high-entropy distributions.
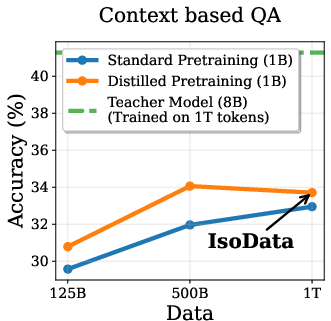
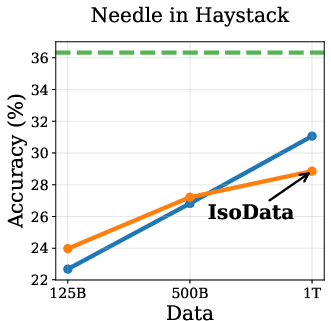
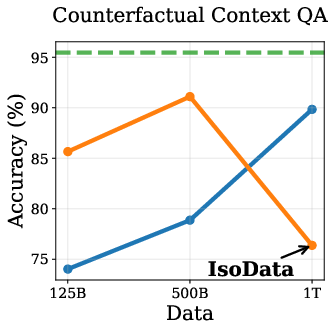
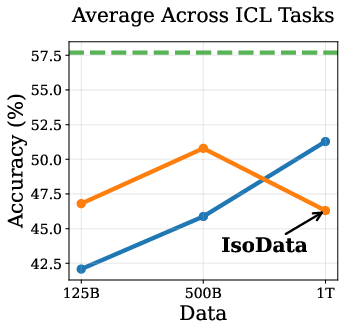
Figure 4: Bigram model analysis: DPT accelerates learning of high-entropy rows, but not low-entropy (induction head) rows.
Theoretical Insights: Generalized Bayes Optimality for Pass@k
The paper provides a formal derivation showing that the Bayes optimal classifier for pass@1 is suboptimal for pass@k when k>1. Instead, optimal pass@k requires accurate estimation of the full conditional distribution, not just correct ranking. DPT-trained models better approximate these distributions, especially in high-entropy settings, explaining their superior TTS performance.
Practical Guidelines for Distilled Pretraining
Token Routing
To mitigate the drop in ICL, the authors propose token routing: skipping the distillation loss on the lowest-entropy tokens and using only ground-truth supervision. This strategy partially restores ICL performance without sacrificing standard task accuracy (Figure 5).
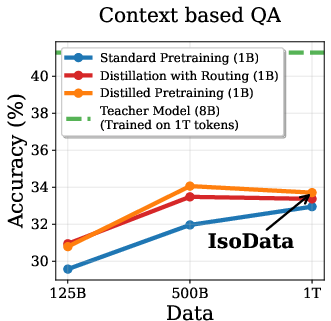
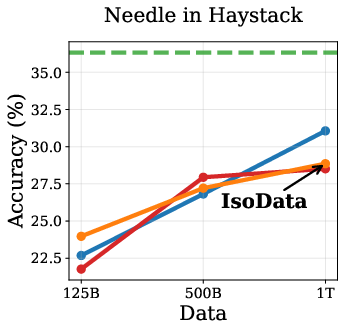
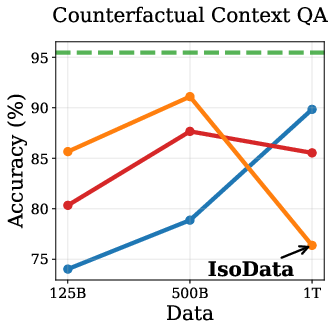
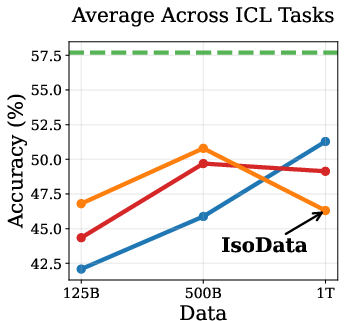
Figure 5: Token Routing: Skipping distillation on low-entropy tokens improves ICL without hurting standard tasks.
Multi-Token Prediction vs. Distillation
Comparisons between next-token prediction (NTP), multi-token prediction (MTP), and DPT reveal that DPT generally yields higher diversity and TTS, even when teacher and student are data-matched. In real-world scenarios, where teachers have seen more data, DPT's advantage is expected to be larger.
Teacher Selection
Empirical results indicate that RL-trained teachers produce superior students compared to base or instruction-tuned teachers, even on general language modeling tasks (Figure 6). This contradicts common practice and suggests that teacher strength outweighs alignment with the pretraining objective.
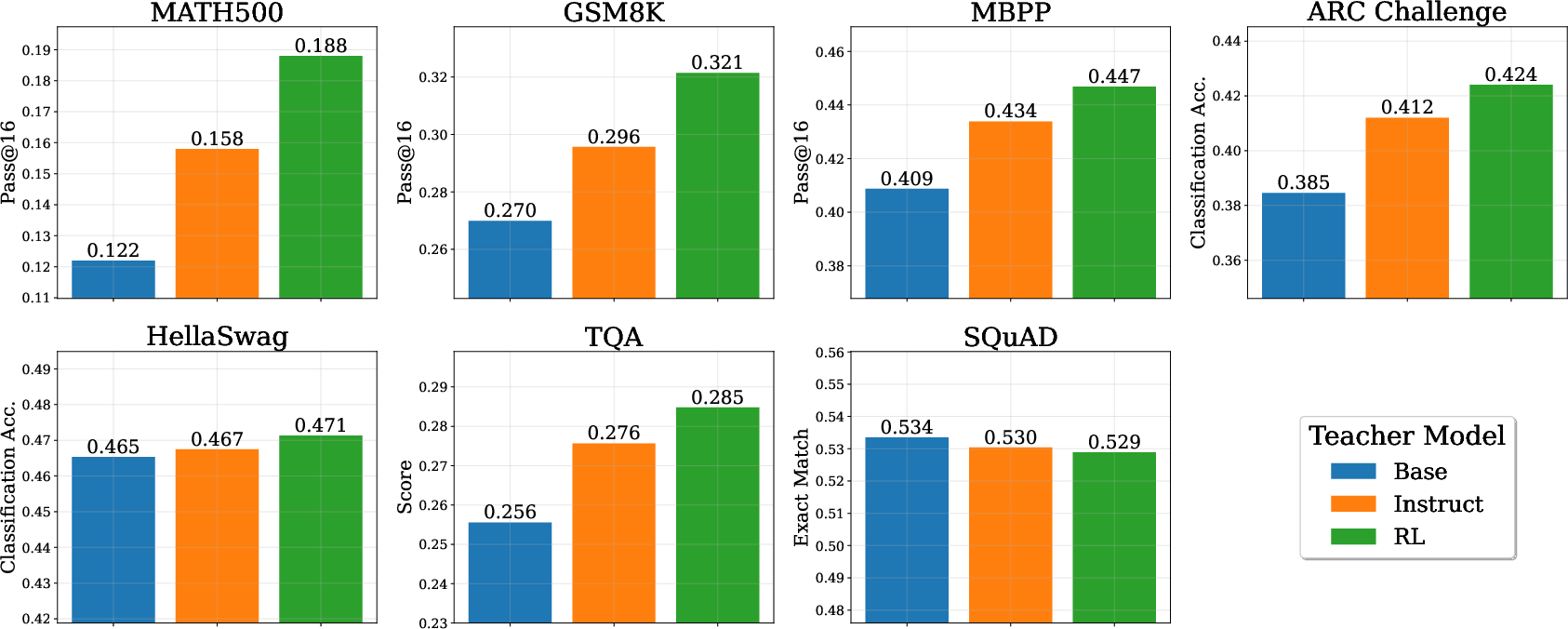
Figure 6: RL-trained teachers yield the best distilled students across diverse benchmarks.
Top-k Sampling Distillation
Sparse soft label distillation (top-k sampling) is shown to outperform standard pretraining, with larger k generally yielding better results, though no clear winner among k>1.
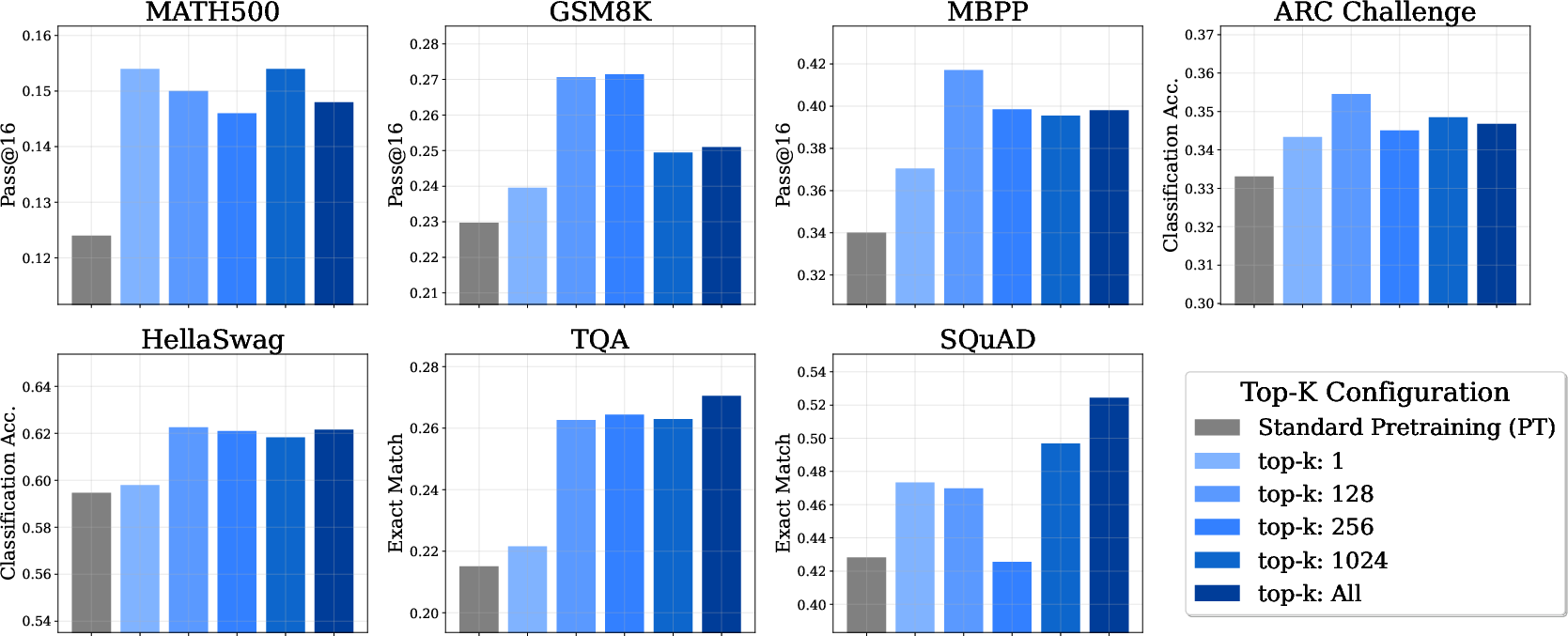
Figure 7: Top-k sampling distillation: Larger k improves performance, but gains saturate.
Implications and Future Directions
The findings have significant implications for LLM development as models approach the data wall. DPT offers foundational improvements in generation diversity and TTS, which are critical for open-ended reasoning and verifier-driven inference. The trade-off with ICL necessitates nuanced strategies such as token routing and careful teacher selection. Theoretical results motivate further research into regularization effects and optimal distribution estimation for pass@k.
Future work should explore integration of DPT with multi-token and future-aware pretraining, as well as dataset curation specifically optimized for distillation. The alignment of pretraining and post-training distillation phases using the same teacher model is another promising direction.
Conclusion
This paper provides a rigorous analysis of distilled pretraining in LLMs, elucidating its benefits and trade-offs in data-constrained regimes. DPT enhances test-time scaling and diversity, but impairs in-context learning due to weakened induction head formation. Theoretical and empirical results converge to inform practical guidelines, including token routing and teacher selection. As LLMs continue to scale, these insights will be instrumental in designing models that balance diversity, efficiency, and adaptability.

