- The paper introduces an implicit mapping pipeline that integrates instance-level semantic awareness with open-vocabulary understanding across multiple agents.
- It employs a three-module system featuring cross-agent instance alignment and cross rendering supervision to boost both geometric and semantic accuracy.
- Experimental results demonstrate enhanced reconstruction completeness, improved semantic segmentation, and reduced communication costs compared to existing methods.
OpenMulti: Open-Vocabulary Instance-Level Multi-Agent Distributed Implicit Mapping
Introduction and Motivation
OpenMulti addresses critical limitations in multi-agent distributed mapping, notably the absence of instance-level semantic awareness and consistent open-vocabulary scene understanding in existing implicit mapping frameworks. Previous methods tend to rely on explicit map fusion via discrete representations, such as point clouds or voxels, which are burdened by high communication and storage costs and suffer from continuity gaps. Recent works utilizing distributed neural optimization (e.g., parameter sharing in NeRF-based systems) partially alleviate these operational inefficiencies but lack semantic granularity, restricting their utility in robotic perception, navigation, and interaction tasks.
OpenMulti advances the state-of-the-art by introducing an implicit mapping pipeline that is both instance-level and open-vocabulary aware, leveraging agents’ heterogeneous observations for mutually consistent semantics and efficient downstream task facilitation.
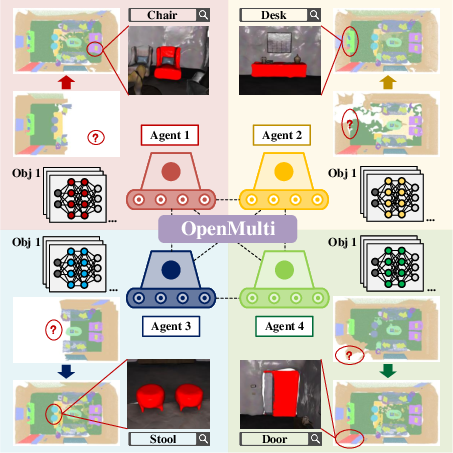
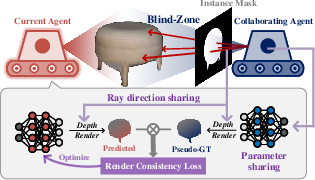
Figure 1: OpenMulti constructs globally consistent, open-vocabulary implicit maps across multiple agents, filling perceptual blind spots and supporting instance retrieval tasks.
System Architecture
The framework is composed of three primary modules:
- Multi-Agent Data Collection and Preprocessing: Each agent acquires RGB-D frames, pose tracks, and instance segmentations using high-performance tools (e.g., CropFormer, OpenObj front-end) and stores semantic features via CLIP and SBERT representations in a codebook for each instance.
- Cross-Agent Instance Alignment: Tackles semantic ambiguity and granularity mismatches across agents. The process constructs an Instance Collaborative Graph through the following steps:
- Downsampled point cloud generation from instance masks and depth maps.
- Spatial consistency assessment via IoU and IoB computations on these point clouds.
- Confidence estimation (location- and occlusion-based) for robust reference selection.
- Propagative graph traversal for mask correction, merging, and semantic unification, ensuring injective cross-agent mappings.
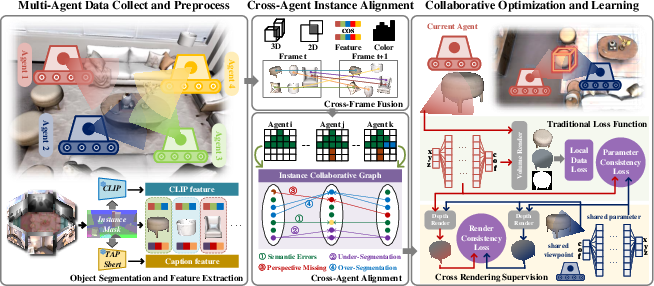
Figure 2: Pipeline overview, highlighting data acquisition, cross-agent semantic unification, and collaborative learning.
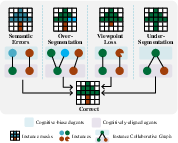
Figure 3: Correction of erroneous instance masks via an intermediate collaborative graph enabling consistent cross-agent instance interpretations.
- Collaborative Optimization and Learning: Each agent maintains per-instance NeRF models (small MLPs) rather than a global network. Optimization incorporates both local data losses and inter-agent losses:
Experimental Results
Comprehensive empirical evaluation demonstrates OpenMulti's superiority in both geometry and semantics across simulated and real-world datasets (Replica, ScanNet). Metrics include 3D Accuracy, Completion, and Completion Ratio, as well as semantic metrics F-mIoU and F-mAcc.
3D Geometric Reconstruction: OpenMulti achieves lower reconstruction errors and higher completeness ratios relative to MACIM, Di-NeRF*, DiNNO-Instance, and DSGD-Instance. Notably, on the completion ratio metric (percentage of reconstructed surface within 5cm of ground truth), OpenMulti yields up to 81.52% vs. 72.92% for Di-NeRF*.

Figure 5: Visual geometric reconstruction comparisons, highlighting OpenMulti’s enhanced accuracy over competing methods.
Zero-Shot 3D Semantic Segmentation: By separating instance-level features and NeRF models, OpenMulti avoids blurred boundaries and under-segmentation observed in single-agent and point-based baselines (LERF, 3D-OVS, ConceptGraph, OpenObj), achieving F-mIoU of 46.18 and F-mAcc of 51.92, outperforming the next-best baseline by over 2 points.

Figure 6: Semantic segmentation results, with OpenMulti preserving fine-grained semantics despite distributed and open-vocabulary constraints.
Ablation and Comparative Studies
Ablations disabling the instance-level mapping or Cross Rendering Supervision degrade both geometric and semantic accuracy and runtime efficiency, substantiating the necessity of both components for robust performance.

Figure 7: Ablation study visualizations: Cross Rendering Supervision and instance-level mapping are both essential for optimal reconstruction fidelity.
Further, OpenMulti demonstrates robustness to communication failures. Simulated reductions in transmission success rates lead to logical drops in completion ratio, yet OpenMulti sustains mapping quality far better than Di-NeRF* (e.g., only a 15.23% decrease at 20% communication rate vs. 39.16% for Di-NeRF*), due to its self-contained instance codebook and one-shot transmission paradigms.

Figure 8: Real-world experiments illustrate OpenMulti’s resilience to communication degradation.
Instance-Level Retrieval
OpenMulti supports open-vocabulary instance retrieval via similarity search across caption and CLIP features stored in the codebooks. This capability is validated qualitatively on diverse scene queries, enabling efficient semantic interaction for downstream applications.

Figure 9: Instance-level retrieval results exhibit robust query performance across various scene objects and attributes.
OpenMulti, compared to centralized and explicit mapping baselines, achieves substantial reductions in communication overhead and optimization runtime. Explicit paradigms scale poorly with increasing scene/agent complexity, whereas OpenMulti offers superior accuracy (geometry and semantics) and instance retrieval functionality with manageable resource footprint. Memory usage grows sub-linearly with instance number due to per-instance model sharing, and overall mapping throughput benefits from distributed computation.
Implications and Future Directions
This framework constitutes a substantial advancement in multi-agent distributed mapping, combining open-vocabulary understanding, instance-level fidelity, and scalable implicit representation. The approach surpasses precedent by delivering globally consistent semantic and geometric maps; supporting high-level robotic tasks such as object navigation, manipulation, and search; and offering resilience to unreliable communication environments.
Potential future extensions include:
- Joint instance-level optimization and pose estimation/multi-agent SLAM integration.
- Extension to dynamic, deformable, or outdoor scenes via multi-modal sensor fusion.
- Online adaptation to novel vocabularies or scene concepts via continual learning.
- Distributed privacy-preserving semantic mapping for decentralized robotic fleets.
Conclusion
OpenMulti delivers an effective, open-vocabulary, instance-level multi-agent distributed implicit mapping solution equipped with robust semantic alignment and geometric rendering mechanisms. Its cross-agent instance alignment and cross rendering supervision modules are crucial for mitigating ambiguity, blind zones, and mapping artifacts. Experimental results confirm performance benefits over state-of-the-art baselines in both geometric and semantic domains, with strong generalization to real-world robotic scenarios and downstream application support.