- The paper introduces G2T-FM, a framework that repurposes TabPFNv2 through feature augmentation to handle heterogeneous node features in graph tasks.
- Its novel pipeline, including Neighborhood Feature Aggregation (NFA), classic structural features, and PEARL, outperforms traditional GNNs and current GFMs in both classification and regression tasks.
- Experimental evaluations and ablation studies confirm that integrating tabular modeling with graph-specific augmentations leads to improved generalization and robust performance.
Turning Tabular Foundation Models into Graph Foundation Models: A Technical Analysis
Motivation and Problem Statement
The paper addresses the challenge of developing general-purpose Graph Foundation Models (GFMs) capable of handling heterogeneous node features and target spaces across diverse graph domains. Existing GFMs predominantly focus on text-attributed graphs, leveraging pretrained text encoders, or employ dimensionality reduction techniques (e.g., SVD, PCA) to standardize feature spaces. These approaches are limited in their ability to process arbitrary feature types and do not generalize well to graphs with non-textual attributes or regression tasks. The authors propose leveraging advances in Tabular Foundation Models (TFMs), specifically TabPFNv2, to construct a GFM that can process arbitrary node features and targets by transforming graph tasks into tabular ones.
G2T-FM: Architecture and Methodology
The proposed Graph-to-Table Foundation Model (G2T-FM) framework augments node features with graph-derived information and applies a tabular foundation model (TabPFNv2) to the resulting representations. The augmentation pipeline consists of:
- Neighborhood Feature Aggregation (NFA): For each node, numerical features are aggregated over neighbors using mean, max, and min; categorical features are one-hot encoded and averaged. This captures local neighborhood statistics.
- Classic Structure-Based Features (SF): Node degree, PageRank, and the first K Laplacian eigenvectors are computed to encode both local and global structural properties.
- Learnable Structure-Based Encodings (PEARL): Random node initializations are processed by a GNN, repeated M times, and averaged to break structural symmetries and enhance expressivity. Both learnable and non-learnable (random) variants are considered.
The concatenated feature vector is input to TabPFNv2, which operates in both in-context learning (ICL) and finetuning (FT) regimes. The model is designed to satisfy feature permutation invariance, label permutation equivariance, and node permutation equivariance in distribution.
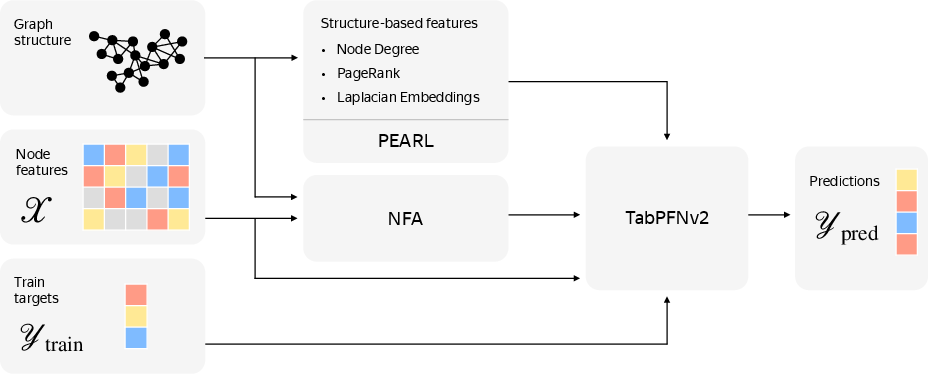
Figure 1: Overview of the proposed G2T-FM, illustrating the augmentation of node features with graph-derived components and subsequent processing by TabPFNv2.
Experimental Evaluation
Datasets and Protocol
Experiments are conducted on two collections: (1) graphs with tabular (non-textual) node features from the GraphLand benchmark, and (2) classical graph benchmarks with text-derived node features. Both regression and classification tasks are considered, with standardized splits (10% train, 10% validation, 80% test) and transductive evaluation. TabPFNv2 constraints limit experiments to datasets with ≤10 classes and ≤10,000 training samples.
Baselines
Comparisons are made against:
- Well-tuned GNNs (GCN, GraphSAGE, GAT, GT) with residual connections, layer normalization, and MLP blocks.
- LightGBM+NFA (gradient-boosted trees with neighborhood aggregation).
- Publicly available GFMs (AnyGraph, OpenGraph, TS-GNN, GCOPE) in ICL and FT regimes.
Results
- Existing GFMs underperform relative to well-tuned GNNs across both tabular and text-based datasets, except for isolated cases (e.g., TS-GNN on amazon-ratings).
- G2T-FM (ICL) matches or exceeds GNNs on tabular datasets, with superior average rank and strong performance on specific datasets (e.g., tolokers-2, artnet-views).
- G2T-FM (FT) consistently outperforms GNNs after finetuning, demonstrating positive transfer from pretraining and robustness across both tabular and text-based datasets.
- Ablation studies confirm the necessity of all augmentation components (NFA, SF, PEARL), with performance drops observed upon removal. Enhanced baselines (GNNs/LightGBM with identical augmented features) do not close the gap to G2T-FM, indicating the synergy between the TabPFNv2 backbone and graph-to-tabular augmentation.
Implementation Considerations
- Computational Requirements: TabPFNv2 imposes limits on class count and training set size; PCA is used to mitigate OOM errors on high-dimensional datasets.
- Finetuning: Full model finetuning is preferred over parameter-efficient methods, with grid search over learning rates.
- PEARL Integration: For GNNs, PEARL outputs are concatenated with node features and trained end-to-end; for LightGBM, random PEARL outputs are used due to lack of differentiability.
- Symmetry Enforcement: Label shuffling is employed to ensure label permutation equivariance during multiclass classification.
Theoretical and Practical Implications
The study demonstrates that tabular foundation models can be effectively repurposed for graph machine learning, overcoming limitations of existing GFMs in handling arbitrary feature and target spaces. The G2T-FM framework provides a simple yet powerful baseline, outperforming both traditional GNNs and current GFMs in standard (non-few-shot) settings. This suggests that the core challenges in GFM design—feature heterogeneity and target generalization—can be addressed by leveraging advances in tabular modeling and appropriate graph-to-tabular transformations.
Future Directions
- Scalability: Extending G2T-FM to handle larger graphs and more classes by integrating scalable TFMs or optimizing the augmentation pipeline.
- Graph-Specific Augmentations: Incorporating more sophisticated aggregation mechanisms (e.g., multi-hop, learnable aggregations) and cross-graph pretraining to enhance structural representation.
- Generalization Across Modalities: Exploring the application of tabular foundation models to other data modalities (e.g., time series, multimodal graphs).
- Benchmarking: Establishing standardized evaluation protocols for GFMs that reflect real-world graph heterogeneity and avoid misleading "zero-shot" terminology.
Conclusion
The paper provides a rigorous framework for transforming tabular foundation models into graph foundation models via feature augmentation and demonstrates strong empirical performance across diverse graph tasks. The results highlight the limitations of current GFMs and the potential of tabular models as a backbone for generalizable, robust graph learning. The approach sets a new baseline for GFMs and opens avenues for future research in scalable, modality-agnostic foundation models for graph-structured data.

