- The paper presents Droplet3D, a model that leverages video commonsense priors to mitigate 3D data scarcity and enhance generation.
- It introduces the Droplet3D-4M dataset of 4 million 3D models paired with multi-view videos and rich text annotations curated via a multi-stage pipeline.
- Experimental results demonstrate superior spatial consistency and semantic fidelity in 3D reconstruction compared to existing state-of-the-art techniques.
Droplet3D: Leveraging Commonsense Priors from Videos for 3D Generation
Introduction
Droplet3D introduces a paradigm shift in 3D generative modeling by exploiting the rich commonsense priors embedded in large-scale video datasets. The approach addresses the persistent bottleneck of 3D data scarcity by transferring spatial consistency and semantic knowledge from videos to 3D asset generation. The paper presents two main contributions: the Droplet3D-4M dataset, a large-scale multi-view video-text annotated 3D dataset, and the Droplet3D model, a generative framework fine-tuned from a video diffusion backbone to support joint image and dense text conditioning for high-fidelity 3D content creation.
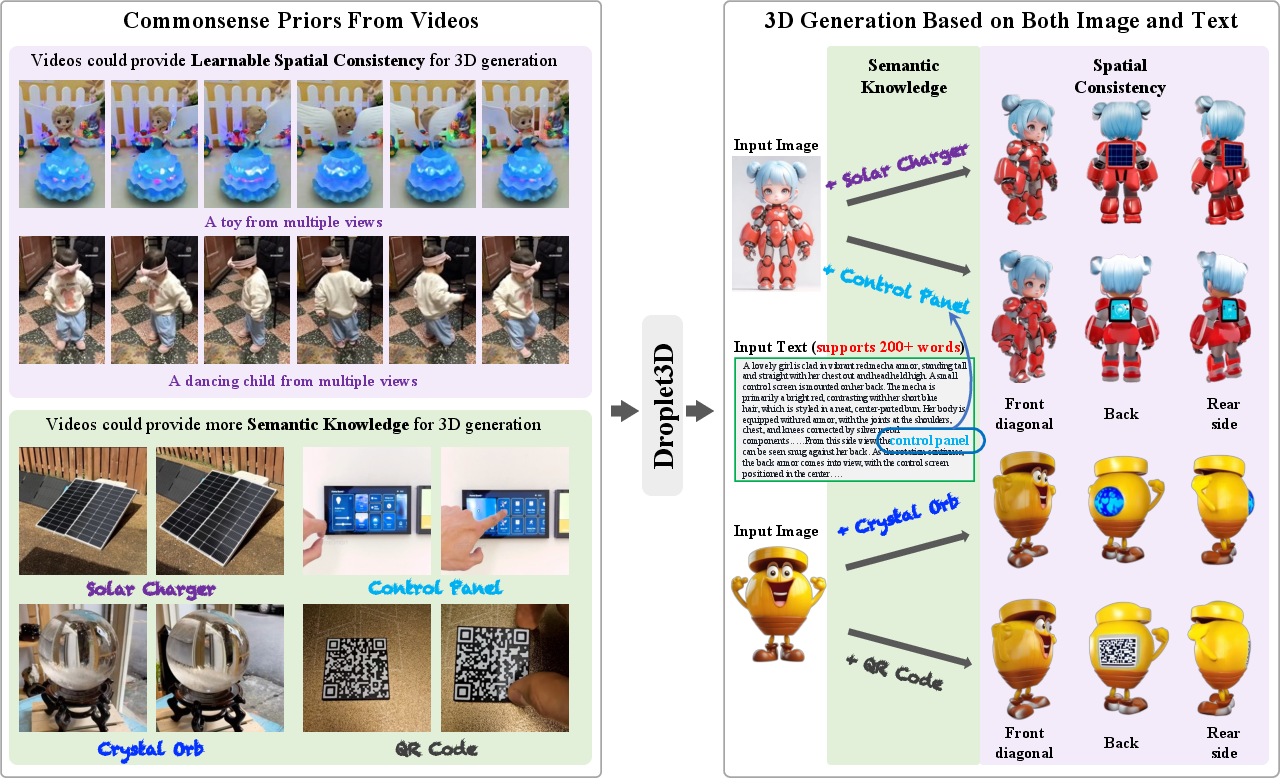
Figure 1: Droplet3D achieves creative 3D content generation based on both image and text input. Commonsense priors including spatial consistency and semantic knowledge facilitate the 3D generation abilities of our method.
Droplet3D-4M Dataset Construction
The Droplet3D-4M dataset comprises 4 million 3D models, each paired with an 85-frame 360° orbital rendered video and a multi-view-level text annotation averaging 260 words. The dataset is curated from Objaverse-XL, with a multi-stage pipeline involving coarse and fine rendering, image quality filtering, and dense caption generation.

Figure 2: A sample from Droplet3D-4M comprises an 85-frame multi-view rendered video and a fine-grained, multi-view-level text annotation.
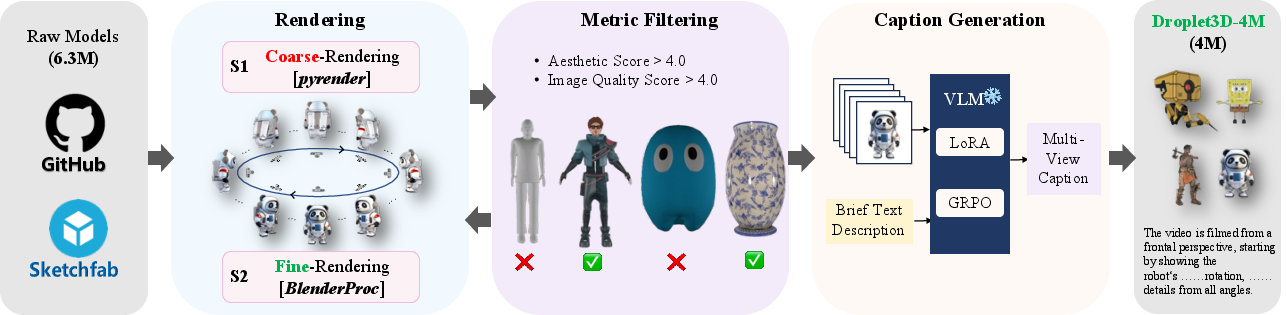
Figure 3: The pipeline we proposed to curate the Droplet3D-4M dataset. The proposed pipeline encompasses three key stages: multi-granularity rendering, filtering, and caption generating.
The rendering process utilizes both PyRender and BlenderProc, with strict geometric normalization and lighting setups to ensure uniformity. Image assessment leverages LAION aesthetics and DOVER-Technical metrics, retaining only samples with scores above 4.0. Caption generation is performed via supervised fine-tuning of multimodal LLMs and further enhanced with GRPO-based reinforcement learning, ensuring multi-view correspondence and semantic richness.

Figure 4: An caption illustration from Droplet3D-4M. Each 3D model is rendered into a multi-view video with detailed, viewpoint-aware captions.
The dataset achieves high standards in both aesthetics and image quality, as evidenced by its score distributions.

Figure 5: The aesthetics distribution and the image quality distribution of Droplet3D-4M. These distributions demonstrate high scores in both metrics.
Droplet3D Model Architecture
Droplet3D is fine-tuned from DropletVideo, a video diffusion model with integral spatio-temporal consistency. The architecture consists of a 3D causal VAE for latent space encoding/decoding and a vision-text modality-expert Transformer for multi-modal fusion. The model supports joint conditioning on an initial image and dense text, enabling granular control over generated content.

Figure 6: Droplet3D Framework: Inheriting spatial-semantic priors from massive videos for high-fidelity 3D generation.
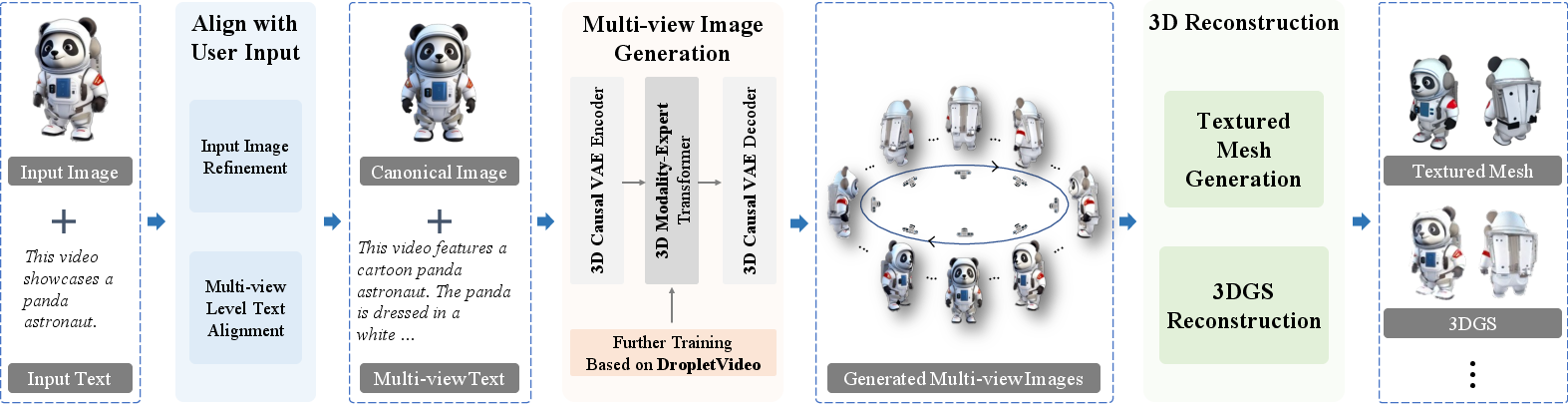
Figure 7: Overview of the Droplet3D Techniques. The pipeline includes input alignment, backbone multi-view generation, and downstream 3D reconstruction.
The backbone leverages 3D positional embeddings and T5-based text encoding, facilitating robust fusion of spatial and semantic priors. The model is further equipped with modules for text rewriting (LoRA-finetuned LLMs) and image canonical view alignment (LoRA-finetuned FLUX.1-Kontext-dev), ensuring user inputs are compatible with the training distribution.
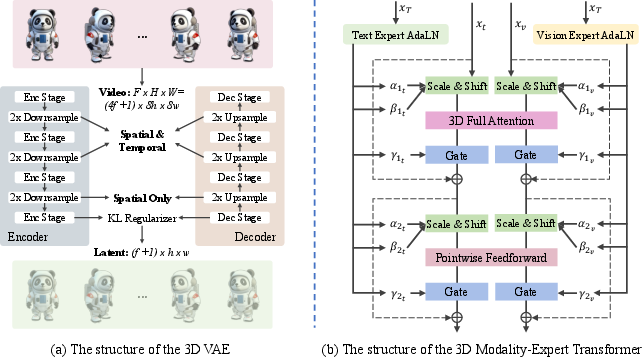
Figure 8: The surrounding multi-view video generation backbone of Droplet3D. It consists of a 3D causal VAE and a vision-text modality-expert Transformer.

Figure 9: An illustration of rewritten samples. Text describing viewpoint changes is highlighted, demonstrating alignment with training captions.
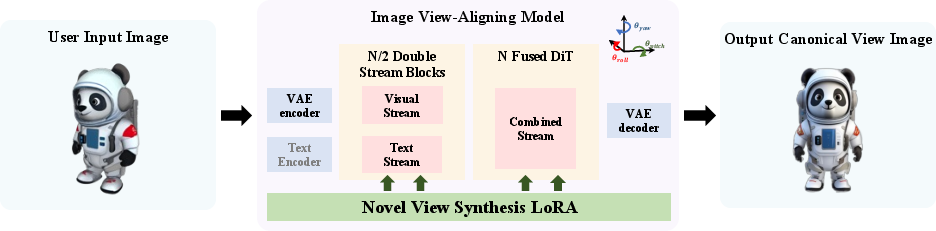
Figure 10: Image alignment module converts users' arbitrary inputs into canonical perspectives.
Experimental Results and Quantitative Evaluation
Droplet3D demonstrates superior performance in TI-to-3D tasks compared to LGM and MVControl, with significant improvements in PSNR, SSIM, LPIPS, MSE, and CLIP-S metrics. The model's ability to maintain spatial consistency and semantic fidelity is attributed to its video-driven backbone and dense multi-modal supervision.

Figure 11: Comparison of generated content from different generative methods supporting simultaneous image and text input. Droplet3D outperforms baselines.
Ablation studies confirm the necessity of continued training on Droplet3D-4M, with Droplet3D outperforming its DropletVideo predecessor in spatial consistency and semantic alignment.

Figure 12: Comparison between Droplet3D and its predecessor, DropletVideo. Droplet3D exhibits enhanced spatial consistency.

Figure 13: Comparison between DropletVideo and other video backbones. DropletVideo demonstrates superior performance in circumnavigation shooting tasks.
Applications and Generalization
Controllable Creativity
Droplet3D supports controllable creativity by conditioning on both image and text, enabling targeted asset generation. The model can synthesize diverse variants of objects based on different textual prompts, demonstrating robust semantic understanding and creative flexibility.

Figure 14: Controllable-Creativity based on the initial image of the Panda Astronaut case and different given texts.

Figure 15: Controllable-Creativity based on the initial image of the Castle case and different given texts.

Figure 16: Controllable-Creativity based on the initial image of the Battle Axe case and different given texts.
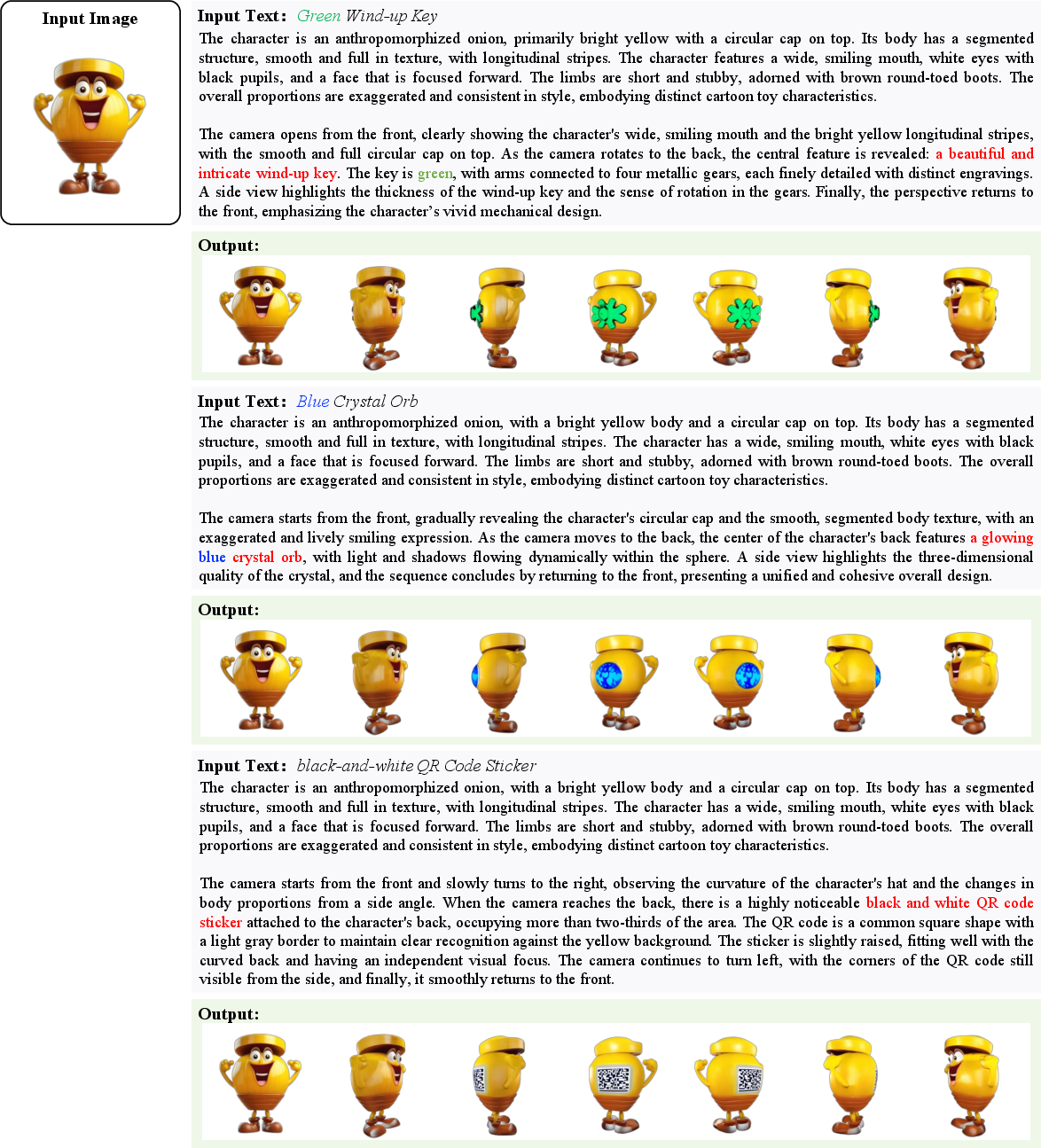
Figure 17: Controllable-Creativity based on the initial image of the Coin Onion case and different given texts.
Droplet3D exhibits strong generalization to stylized inputs, such as sketches and comic-style images, despite the absence of such data in its training set. This capability is likely inherited from the video backbone's broad semantic priors.
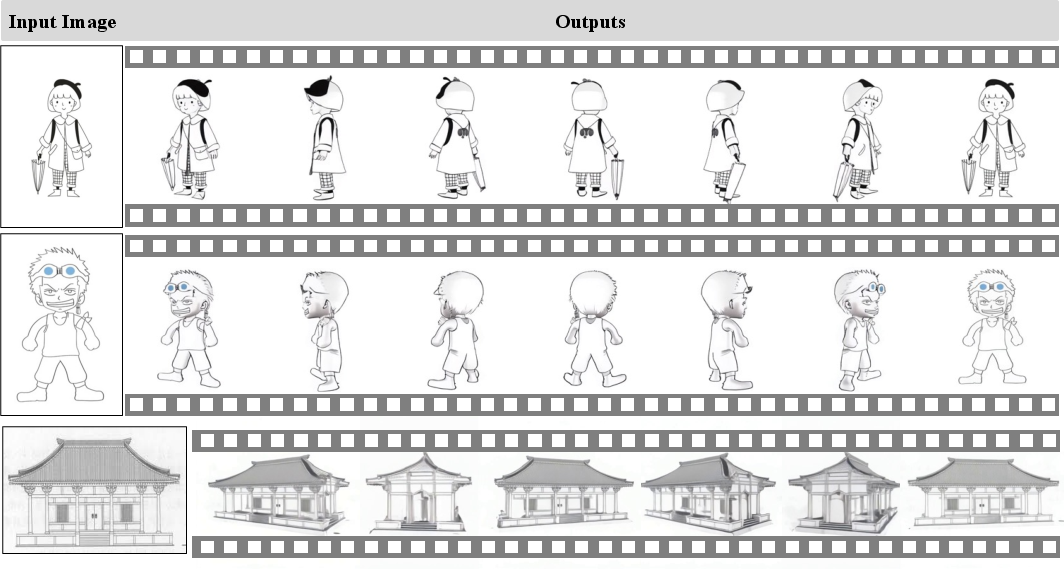
Figure 18: Droplet3D demonstrates its lifting capability on 2D sketch paintings.

Figure 19: Droplet3D demonstrates its lifting capability on 2D images styled as comics paintings.
Downstream 3D Reconstruction
Droplet3D-generated multi-view images can be converted into textured meshes and 3D Gaussian splatting representations using open-source tools (Hunyuan3D-2.0/2.1, native optimization-based approaches), producing production-ready 3D assets with high spatial consistency.

Figure 20: Mesh reconstruction based on content generated by Droplet3D.

Figure 21: 3D Gaussian splatting reconstruction based on content generated by Droplet3D.
Scene-Level Generation
Unlike prevailing object-centric 3D generation methods, Droplet3D demonstrates the ability to lift scene-level content into 3D, a capability not present in its training data but inherited from the video backbone.

Figure 22: Gaussian splatting edition based on scene-level content generated by Droplet3D.
Implementation Considerations
Droplet3D is trained with bfloat16 mixed precision, leveraging DeepSpeed-like optimizations. The model supports 512px resolution and employs classifier-free guidance during inference. The pipeline is modular, with LoRA-finetuned alignment modules for both text and image inputs. Resource requirements are substantial due to the scale of the dataset and model, but the pipeline is open-sourced for reproducibility and further research.
Implications and Future Directions
Droplet3D demonstrates that video-derived commonsense priors can substantially enhance 3D generative modeling, particularly in domains constrained by data scarcity. The approach enables robust multi-modal conditioning, fine-grained control, and generalization to out-of-distribution inputs. The ability to lift both object- and scene-level content, as well as stylized images, suggests promising directions for future research in cross-modal generative modeling, dataset curation, and downstream 3D asset synthesis. Further work may explore scaling to higher resolutions, integrating temporal dynamics, and extending to interactive or real-time 3D content creation.
Conclusion
Droplet3D establishes a new paradigm for 3D generation by leveraging spatial and semantic priors from large-scale video data. The Droplet3D-4M dataset and the Droplet3D model together enable high-fidelity, controllable, and generalizable 3D asset creation from joint image and text inputs. The open-sourcing of the dataset, code, and model weights provides a foundation for continued innovation in 3D generative modeling and its applications across creative, industrial, and research domains.