- The paper introduces a task-centric instruction augmentation framework that decomposes instructions into query and constraint elements to improve data diversity and alignment.
- It employs a BFS-based exploration of the constraint space to systematically generate high-quality instruction-response pairs validated across multiple LLMs.
- Empirical results demonstrate significant performance gains on proprietary meeting AI tasks and public benchmarks, ensuring robust real-world deployment.
Task-Centric Instruction Augmentation for Instruction Finetuning
Introduction
The paper introduces Task-Centric Instruction Augmentation (TCIA), a systematic framework for generating diverse, high-quality, and task-relevant instructions to improve supervised fine-tuning (SFT) of LLMs. Unlike prior instruction augmentation methods that often suffer from diversity collapse and task drift, TCIA explicitly maintains both diversity and task alignment by decomposing instructions into a structured query-constraint space and leveraging a breadth-first search (BFS) over this space. The approach is empirically validated on challenging, real-world meeting AI tasks, demonstrating significant improvements over both open- and closed-source baselines, while preserving generalization on public LLM benchmarks.
TCIA Framework
TCIA is a multi-stage pipeline designed to generate instruction-response pairs that are both diverse and closely aligned with a target task. The framework consists of six key steps:
- Instruction State Decomposition: Each instruction is parsed into a base query and a set of explicit constraints, enabling fine-grained control and interpretability.
- Instruction Database Construction and Retrieval: A large, semantically organized database of decomposed instructions is built (primarily from Tulu-3), supporting efficient retrieval of task- and constraint-level analogs.
- Breadth-First Search (BFS) for Augmentation: BFS systematically explores the space of constraint combinations via add, remove, and replace operations, guided by semantic similarity.
- Conversion Back to Natural Language: Augmented query-constraint states are translated back into natural language instructions using LLMs, with iterative critique and refinement to ensure constraint fidelity.
- Instruction Validation and Context Integration: LLM-based validation filters out instructions that are invalid or inconsistent, and real-world context is integrated as needed.
- Response Generation and Data Quality Filtering: Candidate responses are generated using a pool of strong LLMs, and a multi-dimensional LLM-as-a-judge protocol selects the highest-quality instruction-response pairs for SFT.
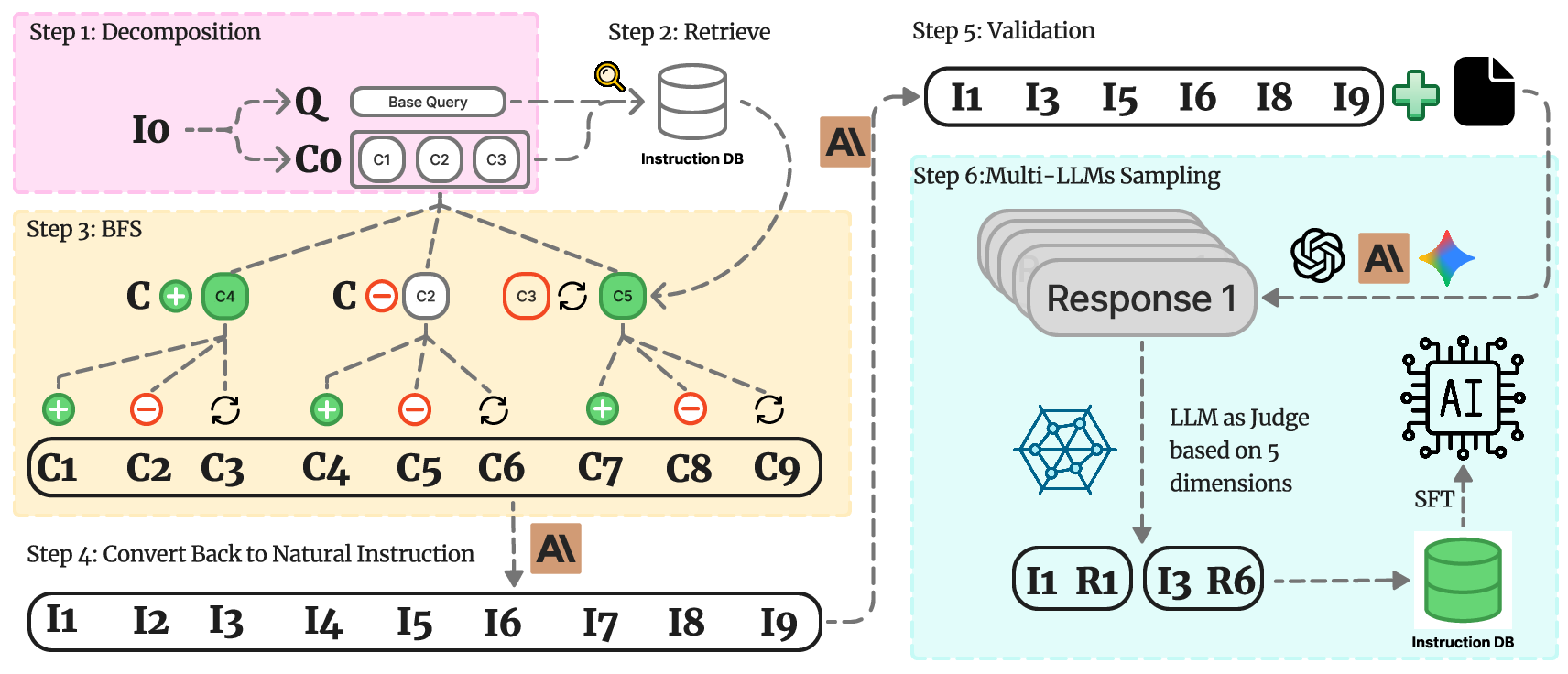
Figure 1: The TCIA framework, illustrating the six-stage pipeline from decomposition to data quality filtering.
This structured approach enables TCIA to generate a large, diverse, and high-quality set of task-specific instructions, which are then used to fine-tune LLMs for robust, real-world performance.
Instruction Diversity and Task Fidelity
A central claim of the paper is that TCIA sustains high instruction diversity and task fidelity across multiple augmentation hops, in contrast to prior methods such as WizardLM, which rapidly converge to repetitive templates and suffer from task drift.
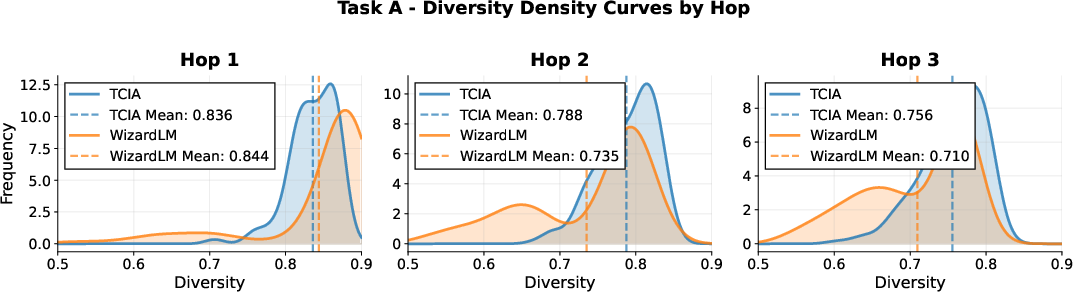
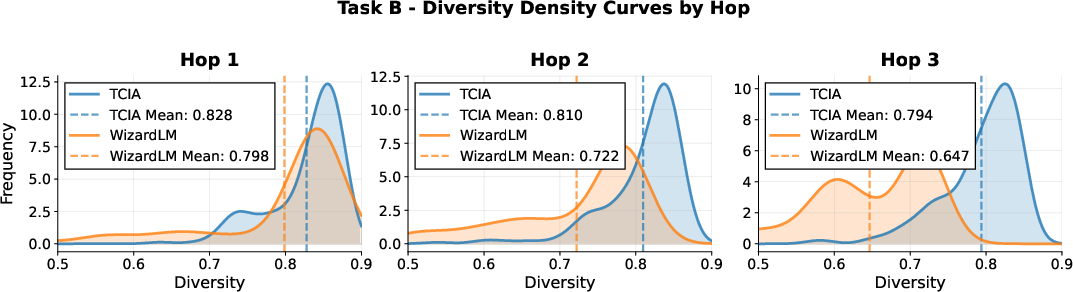
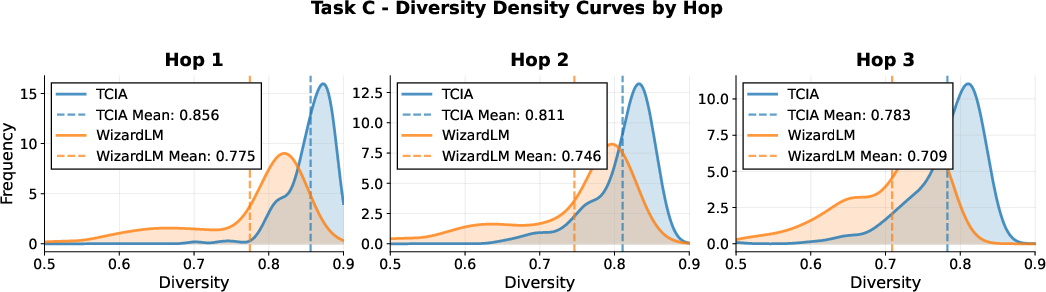
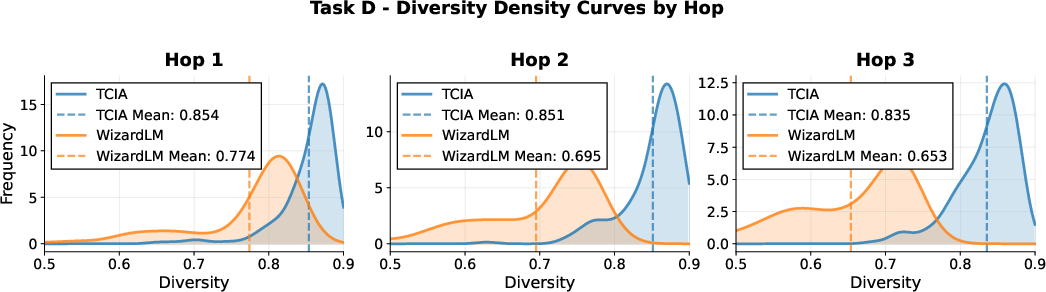
Figure 2: Diversity density plots for TCIA and WizardLM across four in-house tasks and multiple hops, showing TCIA's sustained diversity.
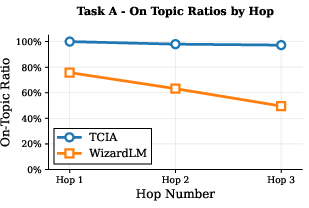
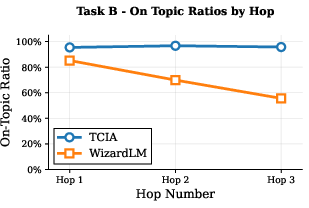
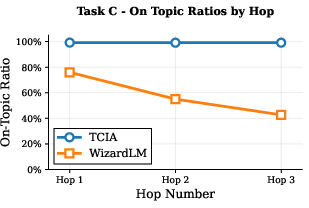
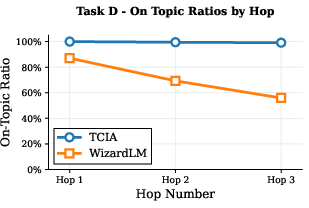
Figure 3: On-task ratio of generated instructions by TCIA and WizardLM, demonstrating TCIA's superior task fidelity across hops.
Quantitatively, TCIA maintains a mean diversity of ~0.8 (1 - cosine similarity) even after three hops, while WizardLM's diversity drops below 0.65 for some tasks. On-task ratio for TCIA remains near 100% across hops, whereas WizardLM's ratio degrades to as low as 40% for certain tasks. These results are corroborated by qualitative examples, where TCIA-generated constraints remain precise and relevant, while WizardLM outputs become formulaic and off-task.
Robustness to Evolving Constraints
TCIA-trained models exhibit strong generalization to unseen constraints, a critical property for real-world deployment where user requirements frequently change. For example, on a representative in-house task, TCIA achieves a 99.2% pass rate for "output in a numbered list" (unseen during training), compared to 98.4% for WizardLM and 0% for the fixed-instruction baseline. Similar trends hold for other constraint types, with TCIA consistently outperforming alternatives.
On four proprietary meeting AI tasks, TCIA delivers an average 8.7% improvement over the fixed-instruction baseline and a 3% improvement over WizardLM. Notably, TCIA also outperforms GPT-4o, a leading closed-source model, by 2.7% on average, with especially strong gains on the most challenging tasks.
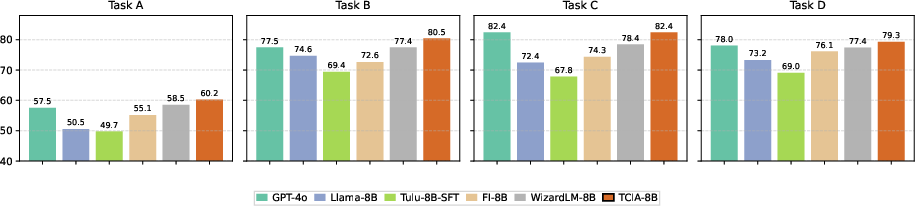
Figure 4: Model performance on four internal tasks, with TCIA surpassing both open- and closed-source baselines.
These results highlight the practical value of TCIA for organizations seeking to deploy LLMs in specialized, high-stakes domains.
Generalization to Public Benchmarks
A potential concern with aggressive task-centric adaptation is catastrophic forgetting or loss of generality. However, TCIA-trained models match or exceed the performance of WizardLM and the fixed-instruction baseline on a suite of public LLM benchmarks, including IF-Eval, Info-Bench, GPQA, BBH, and MMLU-Pro. For instance, TCIA achieves 81.26 on Info-Bench and 34.99 on MMLU-Pro, outperforming Tulu-8B-SFT and WizardLM-8B on these metrics. This demonstrates that TCIA's gains in task-specific performance do not come at the expense of general instruction-following ability.
Implementation Considerations
Computational Requirements
- Decomposition and BFS: The decomposition step is LLM-inference heavy but parallelizable. BFS over the constraint space is combinatorially complex but tractable with appropriate limits (e.g., K=2,700, m=10, k=2,000).
- Semantic Retrieval: Embedding-based retrieval (e.g., all-mpnet-base-v2) is efficient and scales well with large instruction databases.
- Response Generation and Filtering: Multi-model response generation and LLM-as-a-judge filtering are resource-intensive but can be distributed.
Data Quality
- Validation: LLM-based validation and critique/refinement loops are essential for ensuring constraint fidelity and logical consistency.
- Filtering: Multi-dimensional scoring (quality, helpfulness, instruction following, uncertainty, truthfulness) ensures only robust examples are retained.
Scaling and Adaptation
- Task Transfer: The framework is agnostic to the underlying task, provided a suitable seed instruction and context are available.
- Multimodal Extension: While the current implementation is text-centric, the decomposition and augmentation principles are extensible to multimodal settings.
Implications and Future Directions
TCIA provides a principled approach to instruction augmentation that balances diversity, task alignment, and data quality. Its empirical success on both proprietary and public benchmarks suggests broad applicability for organizations seeking to deploy LLMs in specialized domains without sacrificing generality. The explicit query-constraint decomposition also opens avenues for more interpretable and controllable instruction generation, as well as for advanced curriculum learning and automated prompt engineering.
Future work could explore:
- Multi-turn and dialogue-based augmentation for conversational agents.
- Automated ambiguity resolution and prompt refinement for underspecified instructions.
- Integration with retrieval-augmented generation and knowledge-grounded augmentation.
- Extension to multimodal and cross-lingual instruction spaces.
Conclusion
TCIA establishes a robust, scalable, and effective paradigm for task-centric instruction augmentation. By decomposing instructions, leveraging semantically organized databases, and systematically exploring the constraint space, TCIA generates high-quality, diverse, and task-relevant data for SFT. The resulting models achieve state-of-the-art performance on specialized tasks and maintain strong generalization, making TCIA a practical solution for real-world LLM deployment and adaptation.