- The paper demonstrates that LLM token-level perplexity reliably mirrors human EEG responses to confusing code.
- It employs statistical tests on 72 trials with 24 programmers to validate correlations between perplexity spikes and FRP amplitude.
- The method automatically detects confusing code regions, recovering 64% of annotated patterns and revealing novel segments for tooling improvements.
Alignment of Human and LLM Confusion in Program Comprehension
Introduction
This paper investigates the alignment between human programmers and LLMs in their responses to confusing code constructs, specifically focusing on "atoms of confusion"—small, syntactically and semantically valid code patterns known to impair human comprehension. The study operationalizes human confusion using neurophysiological measures (EEG-based fixation-related potentials, FRPs) and LLM confusion using token-level perplexity. The central hypothesis is that LLMs and humans are similarly confused by the same code regions, and that LLM perplexity can serve as a proxy for human cognitive difficulty in program comprehension.
Background
Atoms of confusion have been extensively studied and are empirically validated triggers of human confusion in code across multiple languages. Neurophysiological correlates, particularly late frontal positivity in EEG signals, have been established as robust indicators of cognitive load and confusion during code comprehension. Perplexity, a standard metric in NLP, quantifies model uncertainty and has been shown to correlate with human reading times and error rates in both natural language and source code.
Methodology
The study leverages a dataset of EEG recordings from 24 programmers, each exposed to 72 code comprehension trials containing either confusing or clean code snippets. Human confusion is measured via FRP amplitude at the Fz electrode in the 400–800 ms post-fixation window. LLM confusion is quantified using token-level perplexity from Qwen2.5-Coder-32B, selected for its state-of-the-art performance on Java tasks. The analysis includes:
- Token-level and region-level perplexity computation for both entire snippets and predefined areas of interest (AOIs, i.e., atoms of confusion).
- Statistical comparison of perplexity between clean and confusing code using Wilcoxon signed-rank tests.
- Correlation analysis between maximum AOI-level perplexity and FRP amplitude using Spearman’s rank correlation.
- Data-driven detection of regions of confusion via prominence-based peak detection in perplexity, followed by syntactic expansion and filtering.
Results
Effect of Atoms of Confusion on LLM Perplexity
Confusing code snippets containing atoms of confusion consistently trigger spikes in LLM perplexity, both at the snippet and AOI levels. Maximum AOI-level perplexity provides the most targeted and robust signal for model confusion, with statistically significant differences between clean and confusing variants (r=0.45 for AOI-level maximum perplexity).
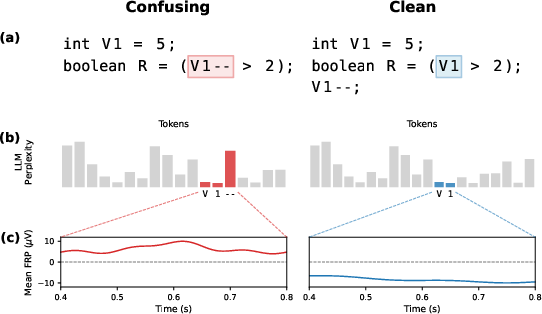
Figure 1: The confusing code snippet (red highlight) elicits increased LLM perplexity and higher EEG FRP amplitude compared to its clean counterpart.
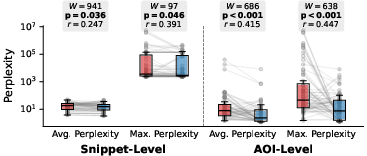
Figure 2: Statistically significant differences in snippet-level and AOI-level perplexity metrics between confusing and clean code variants.
Correlation Between LLM Perplexity and Human Neurophysiological Responses
There is a strong, statistically significant positive correlation between maximum AOI-level LLM perplexity and FRP amplitude in confusing code (ρ=0.47, p<0.001), but not in clean code (ρ=0.05, p=0.664). This demonstrates spatial and amplitude alignment between LLM and human confusion.
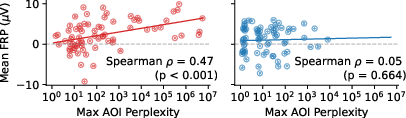
Figure 3: Correlation between maximum AOI-level LLM perplexity and normalized mean FRP amplitude for confusing (left) and clean (right) code variants.
Data-Driven Detection of Confusing Code Regions
A fully automatic, perplexity-based method detects regions of confusion in code by identifying local maxima in token-level perplexity and expanding them syntactically. This approach recovers 64% of manually annotated atoms of confusion and identifies additional regions not captured by manual annotation. Detected regions show positive correlations with FRP amplitude, even in clean code, suggesting that confusion is a continuous spectrum rather than a binary property.

Figure 4: UpSet plot showing overlap between manually annotated atoms of confusion and automatically detected regions of confusion.
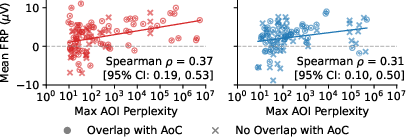
Figure 5: Correlation between maximum AOI-level LLM perplexity and normalized mean FRP amplitude in automatically detected regions, distinguishing overlap with known atoms versus novel regions.
Discussion
The findings establish that LLM perplexity is a reliable, fine-grained proxy for human confusion in program comprehension, especially when localized to specific code regions. The alignment between LLM and human confusion is robust for known confusing constructs and extends to novel regions detected by data-driven methods. This supports the use of LLMs as surrogate models for human program comprehension and opens avenues for scalable, neurophysiologically grounded detection of cognitively demanding code.
Practical Implications
- Tooling: Perplexity-based confusion detection can be integrated into developer tools and educational environments to flag or refactor confusing code, improving code review and learning outcomes.
- Human-AI Collaboration: LLMs can be tuned to better align with human cognitive patterns, enhancing their utility as programming assistants.
- Scalability: The approach is computationally efficient and does not require manual annotation, making it suitable for large codebases.
Theoretical Implications
- Surrogate Modeling: LLMs can serve as computational models for human program comprehension, enabling hypothesis generation and experimental design in cognitive studies.
- Continuous Spectrum of Confusion: The results challenge the binary classification of code as "confusing" or "clean," advocating for a spectrum-based approach informed by both model and human responses.
Limitations and Future Directions
- Generalizability: The study focuses on Java and intermediate programmers; future work should validate findings across languages, model architectures, and programmer expertise.
- Model Size and Alignment: Larger models may diverge from human processing patterns; identifying optimal model sizes for alignment remains an open question.
- Contextual Factors: Incorporating programmer experience and broader code context could further refine confusion detection.
Conclusion
This study demonstrates a strong alignment between LLM perplexity and human neurophysiological responses to confusing code, establishing LLMs as viable surrogate models for human program comprehension. The data-driven, perplexity-based approach enables scalable detection of cognitively demanding code regions, with implications for both research and practice in software engineering and human-AI collaboration. Future work should extend these findings to diverse programming contexts and further integrate neurophysiological signals into LLM evaluation and development.