- The paper introduces a causally-grounded framework that leverages Future-Token Encoding and Precursor Influence to differentiate planning from improvisation in LLMs.
- It employs a semi-automated pipeline combining circuit discovery, FTE filtering, and negative steering to reveal detailed planning dynamics across code and poem generation tasks.
- Instruction tuning in Gemma-2-2B refines plan selection by suppressing incorrect future tokens, thereby improving task performance and output consistency.
Detecting and Characterizing Planning in LLMs
Introduction
This paper presents a formal, causally-grounded framework for detecting and characterizing planning in LLMs. The authors address a central question in mechanistic interpretability: do LLMs generate outputs by improvising token-by-token, or do they plan ahead by selecting future target tokens and steering intermediate generations toward those goals? Prior work has demonstrated planning in specific models and tasks, but lacked generalizable, scalable criteria. This work introduces two operational criteria—Future-Token Encoding (FTE) and Precursor Influence (PI)—and a semi-automated annotation pipeline for robustly distinguishing planning from improvisation across models and tasks. The framework is applied to both base and instruction-tuned Gemma-2-2B models on code generation (MBPP) and poem generation tasks, revealing nuanced patterns of planning and improvisation.
The authors formalize planning in LLMs using sparse autoencoder (SAE) latents as interpretable representations. Planning is defined as the presence of a latent feature at an earlier position that (1) linearly encodes a future token (FTE) and (2) causally influences the generation of intermediate tokens leading to that future token (PI). The detection pipeline consists of:
- Circuit Discovery: Isolate the minimal set of SAE latents responsible for predicting the next token.
- FTE Filtering: Identify latents whose logit lens projections rank a future token highly.
- Cluster-Level PI Check: Negatively steer clusters of FTE latents and observe if the future token is removed and intermediate tokens are perturbed.
- Earliest-Moment Search: Locate the earliest position where PI is satisfied.
- Improvisation Check: Label features as improvisation if they only influence the next token, not earlier positions.
This pipeline reduces the search space by several orders of magnitude, enabling scalable analysis across prompts and models.
Empirical Findings: Planning vs. Improvisation
Poem Generation
Applying the pipeline to the rhyming couplet task previously studied in Claude 3.5 Haiku, the authors find that Gemma-2-2B Instruct solves the task via improvisation, with no evidence of planning signals. Unlike Haiku, which stores candidate rhyme words in advance, Gemma's SAE latents for the rhyme word "habit" only become causally relevant at the final token. Negative steering does not affect intermediate tokens, supporting the improvisation hypothesis.
Code Generation (MBPP)
On MBPP tasks, Gemma-2-2B Instruct exhibits both planning and improvisation, sometimes switching strategies within a single task or across successive token predictions. Case studies demonstrate clear planning signals:
- Sorting Tuples: The model plans for the future token "1" in the lambda function key, and suppressing this plan causes the model to terminate the function prematurely.
- Tetrahedral Number: Planning for the token "2" in the closed-form formula is evident; suppressing this plan reverts the model to a recursive solution.
- Maximum Number from Digits: Planning for "sort" is necessary for correct output; steering away from this plan leads to failure.
(Figure 1)
Figure 1: Planning detection in MBPP tasks, showing how suppressing planning features alters the model's trajectory and output.
Edge Cases
The pipeline identifies ambiguous cases ("can't say") where planning cannot be conclusively determined, such as when the future token overlaps with the prompt or steering leads to out-of-distribution outputs.
Instruction Tuning and Planning Behavior
Comparative analysis between base and instruction-tuned models reveals that instruction tuning refines existing planning behaviors rather than creating them. Both models are capable of planning, but the base model often plans toward incorrect or competing targets, resulting in lower pass rates on planning tasks (54% vs. 100% for Instruct). Suppressing incorrect plans in the base model can recover correct solutions, indicating that instruction tuning improves plan selection and specificity.
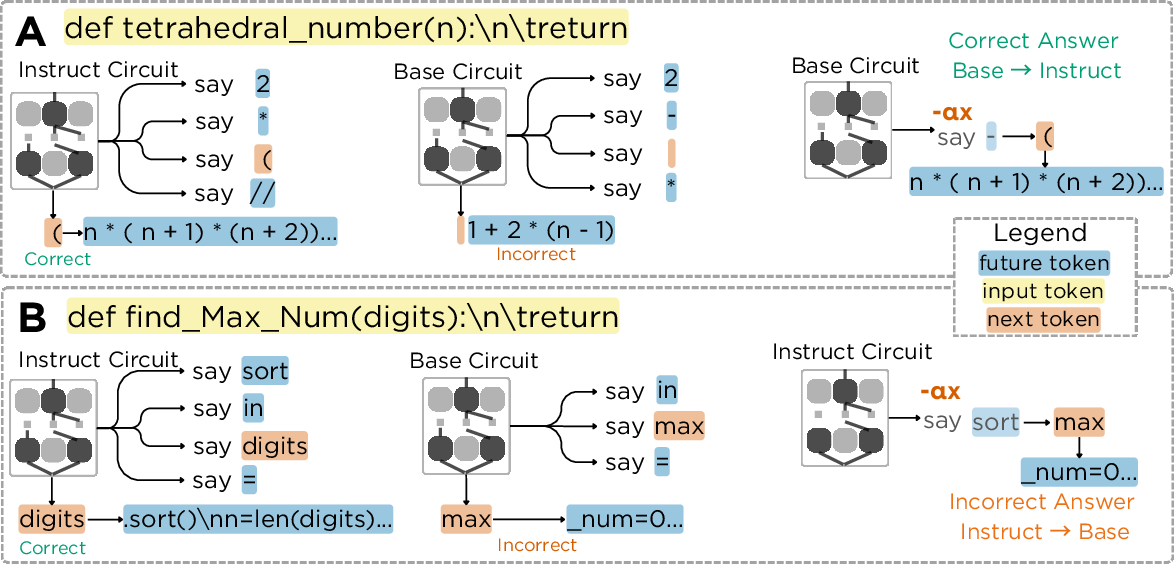
Figure 2: Instruction tuning refines plan selection, resolving competing plans and improving task performance.
Implementation and Scaling Considerations
The detection pipeline is implemented using SAEs trained on MLP outputs, with attribution patching and integrated gradients for circuit discovery. The approach is computationally intensive, requiring ~250 GPU-hours for full analysis on Gemma-2-2B. The pipeline is generalizable to other models and SAE types, but scaling to larger models and broader datasets will require further optimization and automation.
Limitations
- SAE Transferability: Using SAEs trained on the base model for the instruction-tuned variant may introduce representational mismatches.
- Polysemantic Latents: Some latents encode multiple unrelated tokens, complicating interpretation.
- Ambiguous Cases: The framework cannot always resolve planning in cases of prompt overlap or degenerate outputs.
- Dataset and Model Scope: Analysis is limited to Gemma-2-2B and MBPP; broader benchmarks and larger models remain to be explored.
Implications and Future Directions
The formalization and scalable detection of planning in LLMs have significant implications for mechanistic interpretability, model controllability, and safety. Understanding when and how models plan can inform the design of more reliable reasoning systems and expose hidden goal-pursuit mechanisms. Future work should focus on:
- Extending detection to larger models and diverse tasks.
- Refining criteria for ambiguous cases.
- Automating online planning detection during generation.
- Investigating the relationship between planning and model scale, architecture, and training objectives.
Conclusion
This work provides a reproducible, general framework for detecting and characterizing planning in LLMs, moving beyond fixed-horizon and task-specific probes. The findings demonstrate that planning is neither universal nor uniformly effective; models may improvise or plan incorrectly, and instruction tuning primarily refines plan selection. The operational pipeline and formal criteria lay the groundwork for systematic mechanistic studies of reasoning in LLMs, with broad implications for interpretability and model design.