- The paper introduces Tinker, a framework that removes per-scene optimization by leveraging pretrained diffusion models for multi-view consistent 3D editing.
- It employs a dual-module pipeline with a referring multi-view editor and a depth-conditioned scene completion model to propagate edits across views.
- Experimental results demonstrate improved semantic alignment, cross-view consistency, and finer detail preservation in one-shot and few-shot editing scenarios.
Introduction and Motivation
The paper introduces Tinker, a framework for high-fidelity 3D scene editing that operates in both one-shot and few-shot regimes, eliminating the need for per-scene optimization. Tinker leverages the latent 3D awareness of large-scale pretrained diffusion models, specifically repurposing them for multi-view consistent editing. The approach is motivated by the limitations of prior 3D editing pipelines, which require labor-intensive per-scene fine-tuning to ensure multi-view consistency or to generate sufficient edited views for downstream 3D Gaussian Splatting (3DGS) or Neural Radiance Field (NeRF) optimization. Tinker addresses these bottlenecks by introducing a data pipeline and model architecture that generalize across scenes and styles, enabling robust, multi-view consistent edits from as few as one or two images.

Figure 1: Compared with prior 3D editing approaches, Tinker removes the necessity of labor-intensive per-scene fine-tuning, supports both object-level and scene-level 3D editing, and achieves high-quality results in few-shot and one-shot settings.
Methodology
Multi-View Consistent Editing Pipeline
Tinker’s pipeline consists of two core components:
- Referring Multi-View Editor: This module enables reference-driven edits that remain coherent across all viewpoints. The model is fine-tuned using a novel dataset where an unedited image is concatenated with an edited image from a different view, and the model learns to propagate the editing intent across views. The fine-tuning employs LoRA adaptation on the FLUX Kontext foundation model, with strict filtering of training samples based on DINOv2 feature similarity to ensure both edit strength and inter-view consistency.
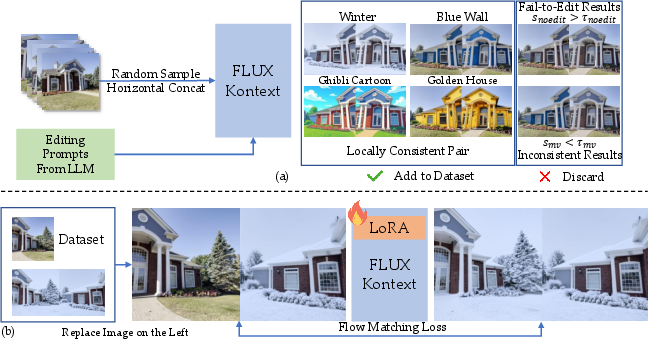
Figure 2: The base FLUX Kontext model generates consistent image pairs, which are filtered and used to fine-tune the model for referring-based editing via LoRA.
- Any-View-to-Video Synthesizer (Scene Completion Model): Built on WAN2.1, this module leverages spatial-temporal priors from video diffusion to perform high-quality scene completion and novel-view generation from sparse inputs. The model is conditioned on depth maps (rather than ray maps), which encode both geometric and camera pose constraints, and reference views. The training objective is formulated as a flow matching loss between noisy latent tokens and target video frames, with positional embeddings aligning reference views to target frames.

Figure 3: The Scene Completion Model is built on WAN2.1, using depth and reference view tokens with shared positional embeddings to guide flow matching loss for video reconstruction.
Editing Process
The editing workflow is as follows:
- Render a few videos from the original 3DGS and select sparse views.
- Edit these views using the multi-view consistent image editor.
- Estimate depth maps for the rendered video.
- Use the scene completion model to generate edited images for all other views, leveraging depth and reference views.
- Optimize the 3DGS with the generated edited views, without any per-scene fine-tuning.

Figure 4: Overview of the editing process: multi-view consistent editing produces coherent sparse views, depth constraints enable generation of consistent edited images, which are used for 3DGS optimization.
Dataset Construction
A large-scale multi-view consistent editing dataset is synthesized by sampling pairs of views from 3D-aware datasets, generating editing prompts via a multi-modal LLM, and filtering results based on DINOv2 similarity. The dataset covers diverse scenes, weather, lighting, and artistic styles.

Figure 5: Examples from the synthesized multi-view consistent editing dataset, spanning a wide variety of editing types.
Experimental Results
Comparative Evaluation
Tinker is evaluated against state-of-the-art 3D editing methods (DGE, GaussCtrl, TIP-Editor, EditSplat) on Mip-NeRF-360 and IN2N datasets. Metrics include CLIP Text-Image directional similarity, DINO similarity for cross-view consistency, and aesthetic score. Tinker achieves superior results in both one-shot and few-shot settings, with higher semantic alignment, cross-view consistency, and rendering quality. Notably, Tinker operates efficiently on consumer-grade GPUs and does not require per-scene fine-tuning.

Figure 6: Qualitative comparisons of novel views in different methods.
Ablation Studies
- Fine-Tuning for Consistency: Fine-tuning the FLUX Kontext model for multi-view consistency significantly improves DINO similarity (from 0.862 to 0.943) while maintaining text-image alignment and aesthetic quality.
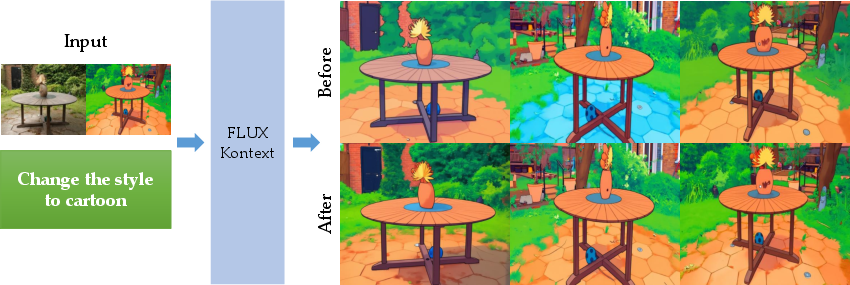
Figure 7: Qualitative comparisons before and after multi-view consistent image editing fine-tuning, showing improved global consistency.
- Image Concatenation: Concatenating more than two images for editing degrades visual quality due to resolution constraints and downsampling. Two-image concatenation yields optimal results.

Figure 8: Effect of the number of horizontally concatenated images on visual quality; two images yield the best results.
- Depth vs. Ray Map Conditioning: Conditioning the scene completion model on depth maps produces superior geometry and detail preservation compared to ray maps or frame interpolation, and supports arbitrary reference views.

Figure 9: Qualitative comparisons of different scene completion methods; depth conditioning achieves superior geometry and detail preservation.
- Comparison with VACE: Tinker demonstrates better multi-view consistency and fine detail preservation than VACE in both depth-guided video generation and mask-based editing.

Figure 10: Comparison with VACE in depth-guided video generation and mask-based editing; Tinker shows superior multi-view consistency and detail preservation.
Applications
- Quality Refinement: Tinker can enhance blurry regions in renderings, recovering sharper structures and finer details.

Figure 11: Tinker refines blurry regions, recovering sharper structures and finer details while maintaining overall consistency.
- Video Reconstruction: Tinker reconstructs high-quality videos from the first frame and depth maps, achieving PSNR 31.869 and SSIM 0.941, outperforming VACE (PSNR 16.635, SSIM 0.331).

Figure 12: High-quality video reconstruction with only the first frame and depth maps as input.
- Test-Time Optimization: Users can iteratively replace low-quality generated views with new ones, improving final 3D editing results.
Implementation Details
- Multi-View Editor: Fine-tuning with LoRA (rank 128) on FLUX Kontext, 30,000 iterations, 4×H100 GPUs, strict DINOv2-based filtering.
- Scene Completion Model: WAN2.1 1.3B backbone, pre-trained on OpenVid-1M, fine-tuned on 3D-centric datasets, 200,000 iterations, 16×H100 GPUs, depth maps from Video Depth Anything.
- 3DGS Optimization: NeRFStudio used for rendering and optimization.
Limitations
- Dataset synthesis via foundation models may introduce fine detail inconsistencies.
- Depth-constrained scene completion cannot handle large geometric deformations.
- Future work should address these limitations and explore more flexible geometric editing.
Conclusion
Tinker presents a scalable, general-purpose framework for multi-view consistent 3D editing from sparse inputs, eliminating the need for per-scene optimization. By bridging advances in 2D diffusion models and 3D scene editing, Tinker enables high-quality object-level and scene-level edits in both one-shot and few-shot settings. The introduction of a large-scale multi-view consistent editing dataset and a unified pipeline for 2D and 3D editing tasks sets a new standard for generalizable, efficient, and user-friendly 3D content creation. The framework’s versatility across editing, video reconstruction, and compression tasks highlights its potential for future research and practical deployment in scalable 3D editing systems.