- The paper presents a novel dual diffusion framework that achieves cycle consistency between forward and inverse rendering processes.
- It employs a single-step UNet finetuning approach with tailored loss functions to enhance rapid inference and maintain high-fidelity rendering.
- Experimental evaluations demonstrate superior PSNR, SSIM, and angular error metrics across diverse datasets, highlighting potential for real-time applications.
Implementation and Implications of "Ouroboros: Single-step Diffusion Models for Cycle-consistent Forward and Inverse Rendering"
Overview
The paper "Ouroboros: Single-step Diffusion Models for Cycle-consistent Forward and Inverse Rendering" introduces a dual diffusion model framework tailored for both forward and inverse rendering, optimizing these processes for rapid computation and mutual reinforcement. The framework ensures the synthesis and decomposition processes remain cycle-consistent, mitigating performance discrepancies often observed with independently trained models.
Model Architecture and Training
Ouroboros Pipeline
The Ouroboros framework consists of two primary diffusion models: one for inverse rendering and another for forward rendering. The inverse rendering model deconstructs an image into intrinsic maps such as albedo, normal, roughness, metallicity, and irradiance. The forward rendering model reconstructs the image from these intrinsic maps along with textual prompts.
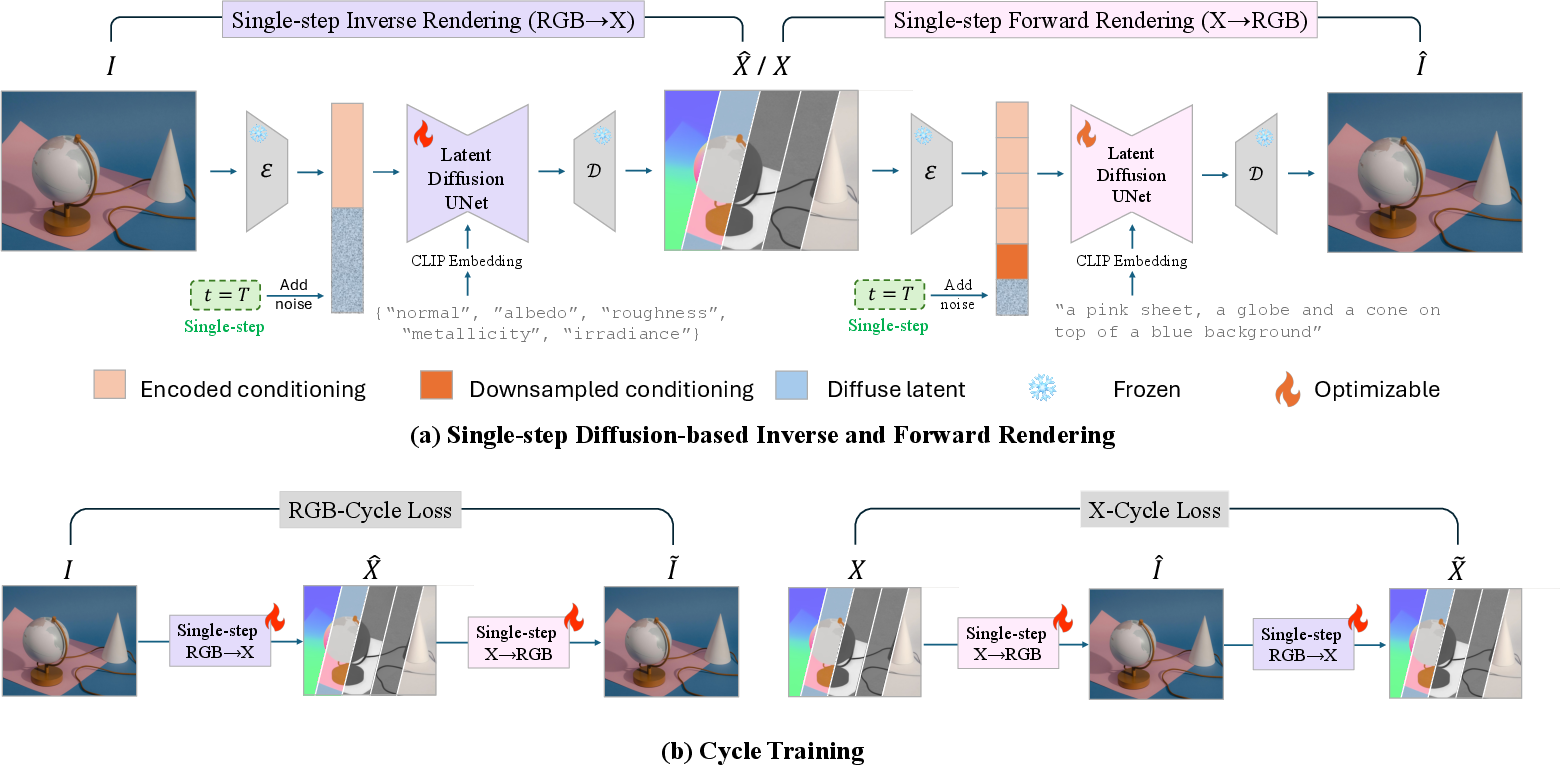
Figure 1: Overview of Ouroboros Pipeline. (a) presents the training pipeline of our single-step Diffusion-based inverse and forward rendering model. For inverse rendering, the model takes the image I and text prompt indicating the output intrinsic maps as input to finetune the latent diffusion UNet. For forward rendering, the model is fed with concatenated intrinsic maps along with simple image description to estimate the original image. (b) provides the overview of cycle training pipeline.
Finetuning and Loss Functions
The models are first finetuned using a single-step prediction approach inspired by state-of-the-art end-to-end finetuning strategies, such as E2E loss [martingarcia2024diffusione2eft]. Only the UNet component of the diffusion model is trained to predict denoised latents directly from highly noisy inputs, ensuring rapid single-step inference:
1
2
3
4
5
6
7
|
def single_step_finetuning(model, data_loader):
model.freeze_all_except_unet()
for images, intrinsic_maps in data_loader:
noisy_latent = apply_noising(intrinsic_maps, amount=max_noise)
denoised_output = model.unet(noisy_latent, t=T)
loss = compute_loss(denoised_output, intrinsic_maps)
update_model(optimizer, loss) |
Specific loss functions cater to various intrinsic properties, including angular difference loss for normal maps and affine-invariant loss for irradiance to accommodate decompositional ambiguities.
Cycle Consistent Training
The independent training of forward and inverse models often results in cycle inconsistencies. In the Ouroboros framework, cycle-consistent training is implemented to ensure outputs from these models can reconstruct each other accurately:
- Cycle Consistency Loss: Ensures the conversion of an image to intrinsic maps and back is consistent with the original input, improving the coherence between the two transforms.
1
2
3
4
5
6
|
def cycle_consistent_training(model_rgb_x, model_x_rgb, dataset):
for image, intrinsic_maps in dataset:
predicted_maps = model_rgb_x(image)
reconstructed_image = model_x_rgb(predicted_maps)
cycle_loss = compute_cycle_loss(image, reconstructed_image)
model_combined_update(cycle_loss) |
Evaluation and Results
Numerical Evaluation
Experiments demonstrate that the Ouroboros method delivers state-of-the-art results with significantly reduced inference time. It showcases superior quantitative metrics in PSNR, SSIM, and angular errors across indoor and outdoor datasets compared to baseline models like RGB↔X [zeng2024rgb].
Qualitative Assessment
In visual inference tasks, the method excels at maintaining high-fidelity rendering even under challenging lighting conditions and complex scene geometries. The integration of real-world data for cycle training further enhances its robustness.
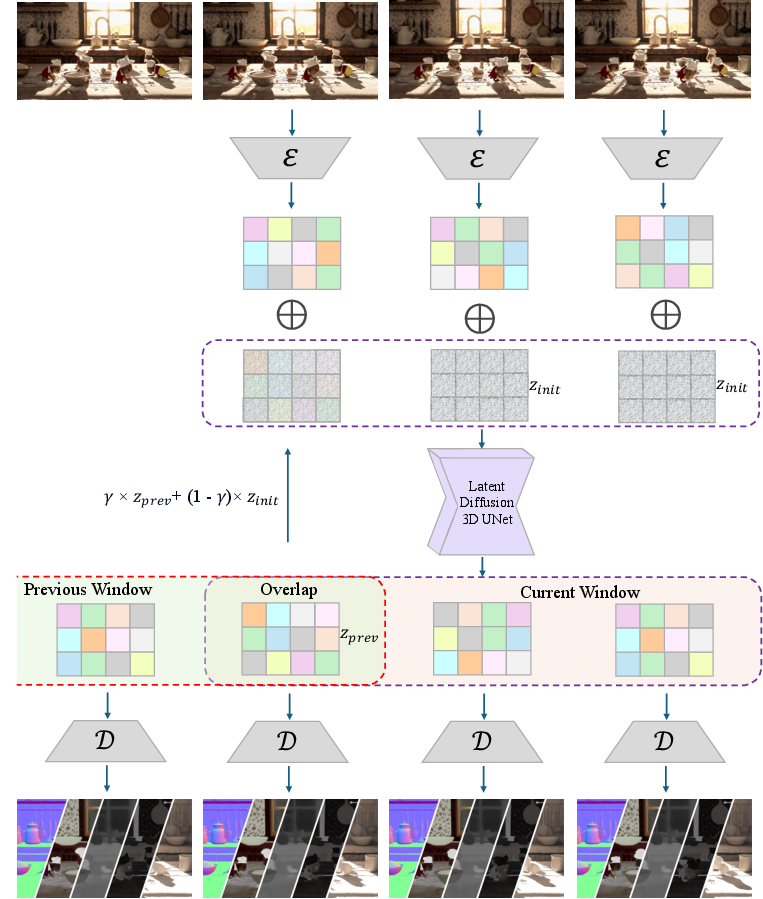
Figure 2: Iterative Video Generation Pipeline. Overlapping windows are processed sequentially, with latent representations from previous windows guiding the initialization of overlapping regions. In practice, the window size and overlap are larger than the figure shown.
Video Inference
The framework also successfully extends to video inference with pseudo-3D convolutional schemas, allowing seamless temporal consistency and efficient resource utilization.

Figure 3: Examples of Video Inference. Our model demonstrates the ability to process real-world scenarios.
Deployment Considerations
Scalability and Resource Efficiency
Ouroboros is highly suitable for scalable deployment in both cloud-based and edge computing environments due to its reduced computational requirements for single-step inference. However, real-time video processing might require optimization to address expanded computational loads.
Data Dependence and Adaptation
The model's performance is contingent on the diversity and quality of training datasets. Enhancing dataset diversity, particularly in outdoor and varied lighting conditions, could further improve model generalization capabilities.
Conclusion
The Ouroboros framework adeptly addresses cycle consistency in rendering tasks, offering a unified model capable of leveraging intrinsic decompositions for accurate and rapid rendering. As the approach matures, it holds promise for expanded applications in video graphics, real-time rendering, and synthetic data generation, albeit with a noted dependency on dataset augmentation for maximizing performance benefits.