- The paper presents novel benchmarks D-RICO and EC-RICO to evaluate incremental learning methods using diverse, realistic datasets.
- The experimental analysis shows replay-based methods significantly mitigate forgetting, outperforming distillation approaches in challenging scenarios.
- Findings highlight that single-model architectures struggle with task-specific nuances, suggesting the need for modular or adaptive strategies.
RICO: Realistic Benchmarks and Analysis for Incremental Object Detection
The paper introduces RICO, a pair of benchmarks—Domain RICO (D-RICO) and Expanding-Classes RICO (EC-RICO)—designed to rigorously evaluate incremental learning (IL) methods for object detection under realistic, diverse, and challenging conditions. The work provides a comprehensive empirical analysis of state-of-the-art IL algorithms, revealing fundamental limitations in adaptability, retention, and model plasticity, and establishes replay as a strong baseline. The benchmarks are constructed from 14 heterogeneous datasets, spanning real and synthetic domains, multiple sensor modalities, and varied annotation policies, thus capturing distribution shifts and task diversity absent in prior evaluations.
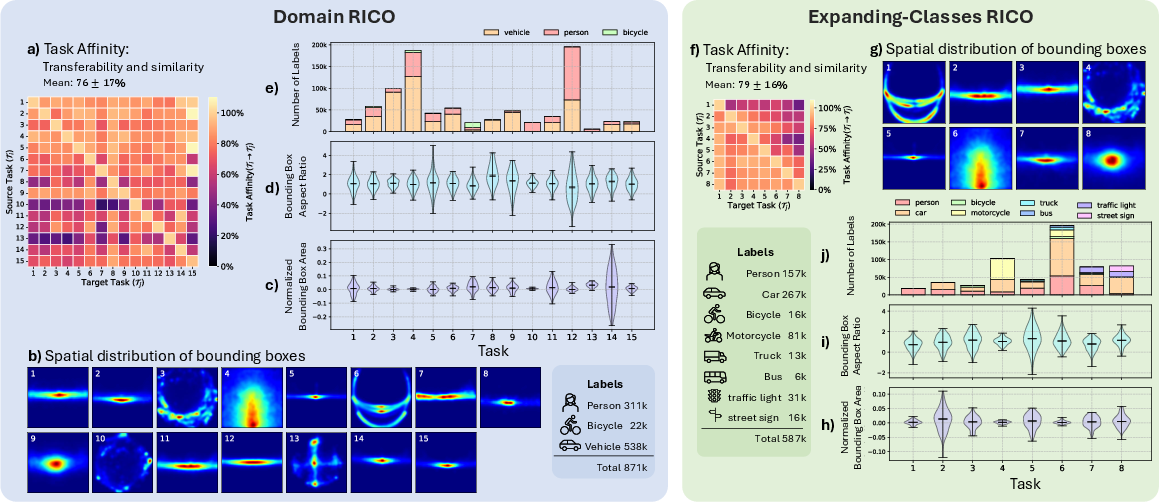
Figure 1: Overview of the domain-RICO and expanding-classes RICO benchmark tasks, illustrating the diversity of domains, sensors, and annotation policies.
Benchmark Design and Task Diversity
RICO is motivated by the inadequacy of existing IL benchmarks, which typically rely on single datasets with limited diversity or artificial splits. D-RICO comprises 15 tasks with a fixed class set (person, bicycle, vehicle), each drawn from a distinct dataset and domain, including urban, rural, synthetic, fisheye, thermal, nighttime, and event camera scenarios. EC-RICO consists of 8 tasks, each introducing a new class and domain, simulating the expanding requirements of real-world applications.
The benchmarks enforce strict dataset selection criteria: minimum size, structural and semantic diversity, common object classes, and open availability. Images and annotations are processed for consistency, but dataset-specific characteristics are preserved to maintain realism. Annotation policies vary widely, with differences in bounding box tightness, amodal/visible labeling, and class definitions.

Figure 2: Random example objects from D-RICO, visualizing annotation policy and quality differences across tasks.

Figure 3: Random examples from EC-RICO, highlighting the diversity in annotation policies and object classes.
Evaluation Protocols and Metrics
IL performance is assessed using mean Average Precision (mAP) as the base metric, with additional measures for memory stability (Forgetting Measure, FM), learning plasticity (Forward Transfer, FWT; Intransigence Measure, IM), and overall accuracy (mAP). The benchmarks require models to sequentially learn new tasks without access to previous data, except for replay-based methods. Task affinity is quantified via fine-tuning output layers, revealing asymmetric and order-dependent transferability.
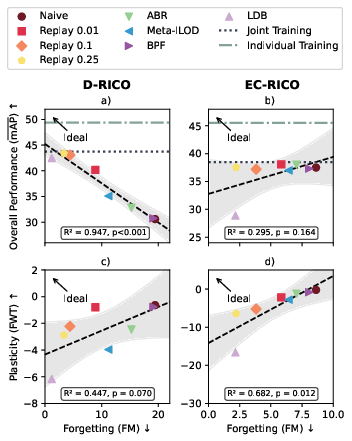
Figure 4: Correlations between Forward Transfer, Forgetting, and Performance across experiments; current methods fail to achieve high plasticity with low forgetting.
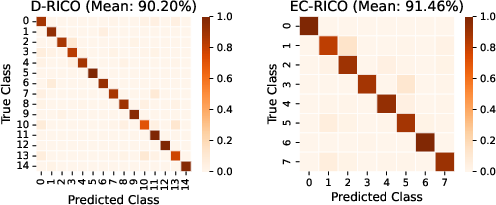
Figure 5: Confusion Matrix of the Nearest Mean Classifier based on image features, demonstrating task separability in feature space.
Experimental Analysis and Method Comparison
The experimental setup employs a two-stage ViTDet-based detector with an EVA-02-L backbone and Cascade Faster R-CNN head, initialized from large-scale pretraining. The backbone is frozen during training to isolate detection head adaptation. Baselines include joint and individual training, naive finetuning, and replay with varying buffer sizes. SOTA methods evaluated include ABR, Meta-ILOD, BPF, and LDB, representing distillation, rehearsal, and model expansion strategies.
Key findings:
- Replay outperforms all SOTA methods: Even low-rate replay (1%) substantially mitigates forgetting and improves mAP, with higher rates approaching joint training performance.
- Distillation is ineffective in diverse domains: Methods relying on knowledge distillation (ABR, Meta-ILOD, BPF) underperform due to weak teacher models, as prior task models generalize poorly to new domains.
- Model plasticity is insufficient: All methods exhibit a trade-off between stability and plasticity; none achieve both high retention and adaptability, leaving a gap relative to individual training.
- Single-model architectures are inadequate: The gap between joint and individual training indicates that a single model cannot capture all task-specific nuances, especially with annotation contradictions and domain shifts.
- Task order has limited impact for strong methods: While naive finetuning is sensitive to task order, replay-based methods are robust, and task affinity does not predict optimal ordering.
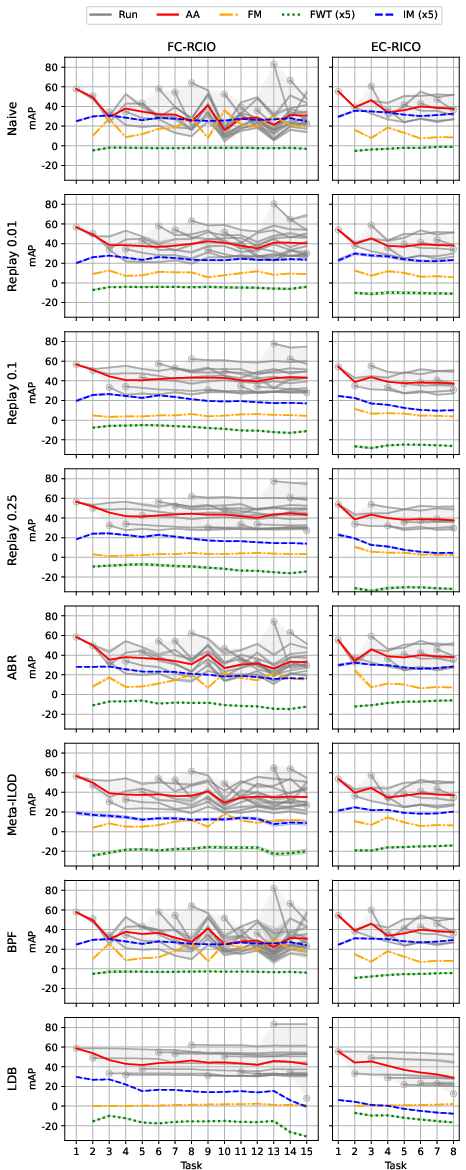
Figure 6: Test performance on D-RICO and EC-RICO for the tested methods, showing the evolution of IL metrics across tasks.
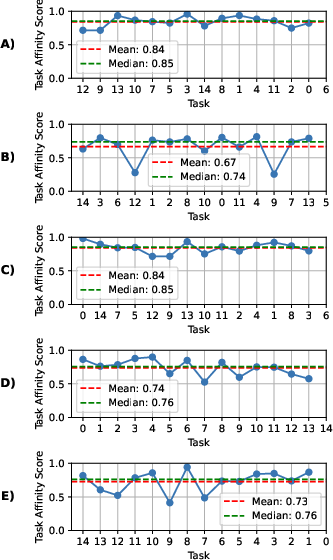
Figure 7: Task affinity to the next task for different task orders, illustrating the asymmetry and diversity in transferability.
Implications and Future Directions
The RICO benchmarks expose fundamental challenges in incremental object detection:
- Replay is a strong but limited baseline: While effective for retention, replay does not enhance plasticity and cannot match individual training performance.
- Distillation and regularization approaches require robust teacher models: In realistic, diverse settings, teacher models often fail to provide meaningful guidance, necessitating new strategies for knowledge transfer.
- Model expansion and task-specific adaptation are necessary: Task-specific weights or modular architectures may be required to handle domain and annotation diversity, but efficiency and transfer remain open problems.
- Plasticity must be prioritized: Future IL research should focus on enhancing model adaptability, not just mitigating forgetting.
- Benchmark realism is critical: D-RICO and EC-RICO set a new standard for evaluating IL methods, emphasizing diversity, annotation policy variation, and long task sequences.
The release of code and data processing scripts enables reproducibility and further research. The benchmarks can be extended to online, few-shot, and class-incremental scenarios, and serve as a platform for studying domain generalization, adaptation, and multi-task learning.
Conclusion
RICO establishes two challenging, realistic benchmarks for incremental object detection, revealing that current IL methods are fundamentally limited in balancing stability and plasticity. Replay emerges as a strong baseline, but new approaches are needed to achieve the adaptability and retention required for real-world deployment. The diversity and complexity of D-RICO and EC-RICO provide a foundation for future research, driving the development of more robust and generalizable IL algorithms.