- The paper introduces VARGPT-v1.1, a unified visual autoregressive model that integrates next-token and next-scale prediction to advance both visual comprehension and image generation.
- It employs a modular architecture combining Qwen2-7B, a Vision Transformer encoder, and a 2B parameter visual decoder, facilitating balanced multimodal instruction handling.
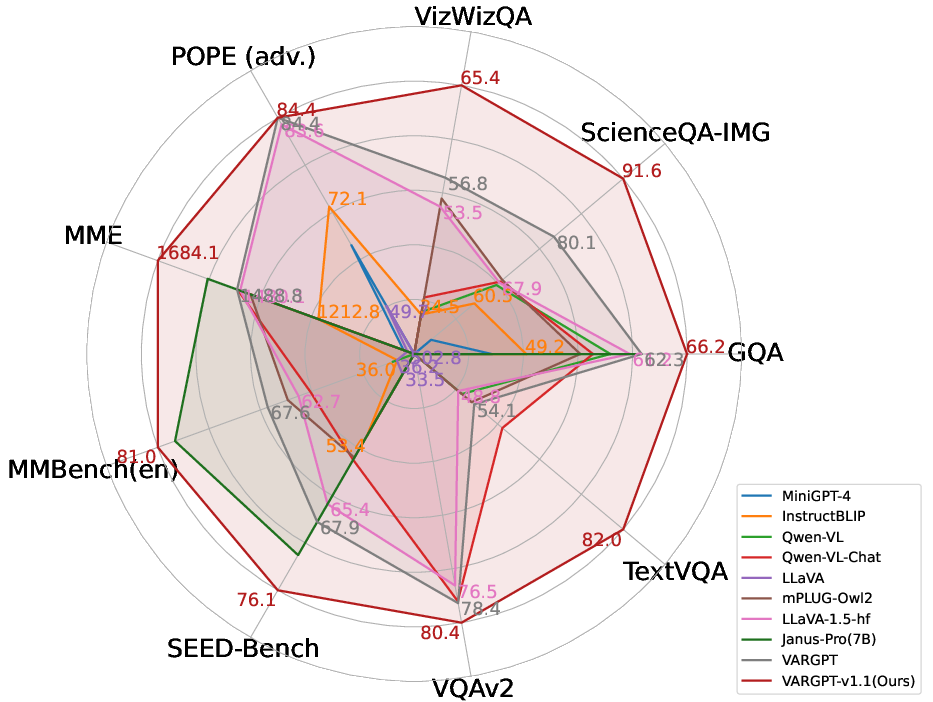
- Empirical results demonstrate state-of-the-art performance on benchmarks and efficient scaling using 8.3M visual-generative instruction pairs from both real and synthetic sources.
VARGPT-v1.1: Unified Visual Autoregressive Large Model via Iterative Instruction Tuning and Reinforcement Learning
Motivation and Context
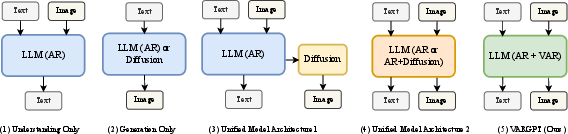
VARGPT-v1.1 is positioned within the ongoing trend toward unified multimodal architectures, which seek to integrate both visual understanding and generation in a single, scalable model. The authors target the paradigm conflict that often arises in prior multimodal LLMs (MLLMs), especially those attempting to reconcile discrete token-based understanding with continuous or diffusion-based generation. VARGPT-v1.1 builds on its predecessor by maintaining a dual autoregressive paradigm—next-token prediction for visual understanding and next-scale prediction for image generation—while substantially improving data scale, architectural efficiency, and training procedures.
Model Architecture and Training Strategy
VARGPT-v1.1 adopts a modularized architecture leveraging Qwen2-7B as its language backbone, integrated with a Vision Transformer (ViT) encoder, linear projectors, and a 2B parameter visual decoder. The architectural innovation lies in maintaining causality in both text and image token prediction, enabling mixed-modal instruction handling. Next-token prediction is used for comprehension, while visual generation is implemented via multi-scale residual quantization and block causal attention in the decoder, facilitating progressive scale prediction in image synthesis.
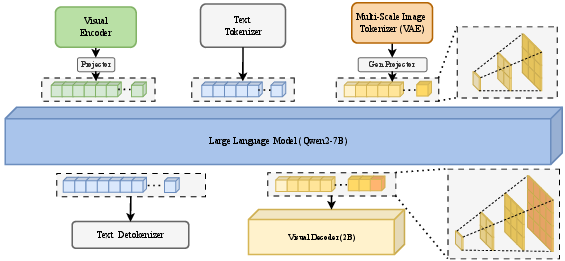
Figure 1: The VARGPT-v1.1 framework combines Qwen2-7B-Instruct with a Vision Transformer encoder and a dedicated visual decoder, harmonizing causal attention across modalities.
The model employs a progressive, three-phase training schedule:
- Stage 1: Pretraining on foundational multimodal capabilities.
- Stage 2: Visual instruction tuning with supervised fine-tuning (SFT) on both real and synthetic data.
- Stage 3: Iterative instruction tuning and reinforcement learning via Direct Preference Optimization (DPO), progressively increasing image resolution and introducing image editing through instruction dataset augmentation.
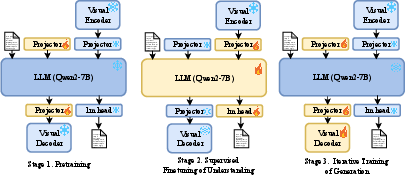
Figure 2: The three-stage curriculum: pretraining, instruction tuning, and iterative SFT–RL for refinement and expanded task coverage.

Figure 3: Iterative training integrates alternating SFT and DPO phases, progressively enhancing output resolution and unlocking image editing competence.
The core SFT–RL loop leverages automatically constructed preference datasets, circumventing manual annotation by contrasting model outputs against stronger commercial baselines (Midjourney, Flux), and optimizing the reward margin through DPO for image token generation only. This strategic decoupling allows policy improvement specific to image generation, while maintaining unified architecture.
Dataset Composition and Scalability
VARGPT-v1.1's dataset is considerably expanded—8.3M visual-generative instruction pairs (a 6-fold increase over v1.0)—split equally between LAION-COCO real samples and synthetic outputs from Midjourney v6 and Flux. For visual comprehension tasks, datasets are drawn from LLaVA-1.5 and LLaVA-OneVision. Visual editing is enabled by full-parameter SFT using StyleBooth datasets, facilitating instruction-based manipulation without structural adjustment.
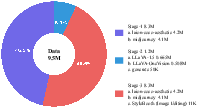
Figure 4: Visualization of data source and proportional allocation across the three training phases.
This approach demonstrates strong evidence for synthetically enhanced convergence, reaffirming the importance of high-quality synthetic data in multimodal scaling.
Empirical Results and Analysis
VARGPT-v1.1 is extensively evaluated across:
VARGPT-v1.1 demonstrates comprehensive improvements:
Qualitative assessments also show VARGPT-v1.1's ability for nuanced meme interpretation, artistic critique, and scene analysis in visual understanding tasks.
Visual Generation and Editing
High-resolution image synthesis (512×512 px) and compliance with mixed-modal instructions are demonstrated in figures featuring both text-to-image generation and image editing functionality, with qualitative outputs retaining fidelity and diversity across domains.

Figure 7: Selected 512×512 image samples generated from mixed-modality instruction prompts.
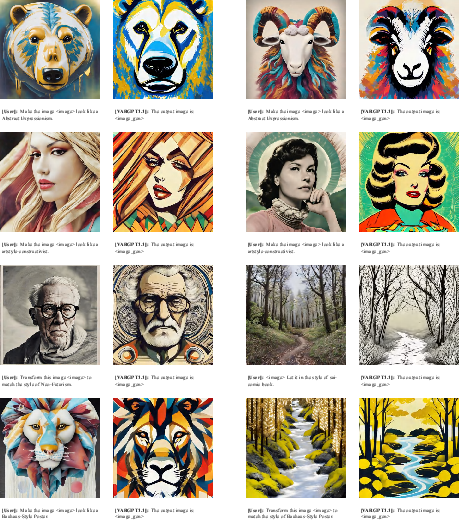
Figure 8: Showcases image editing by instruction—VARGPT-v1.1 applies style transfer and targeted manipulations without architectural modification.
Implications and Outlook
VARGPT-v1.1 establishes a scalable framework for unified multimodal modeling, harmonizing comprehension, generation, and editing without compromising architectural simplicity or efficiency. The iterative SFT–RL pipeline and large-scale synthetic data utilization point toward sustainable, scalable strategies for future multimodal model development. The model’s emergent image editing capacity—acquired by dataset augmentation rather than bespoke architectural intervention—implies further potential for generalized task support in unified multimodal systems.
The empirical achievements underscore the model’s suitability for instruction-following, visual reasoning, and high-quality generation tasks, offering quantitative evidence that autoregressive paradigms, when properly trained, can rival or surpass diffusion-based frameworks in fidelity and task flexibility.
Future work will focus on further scaling, alternative tokenizer innovations, expanded editing datasets, and reinforcement learning integration in multi-turn dialogue settings, with the aim to enhance output quality, resolution, and instruction adherence.
Conclusion
VARGPT-v1.1 advances unified multimodal systems by integrating visual autoregressive modeling with iterative instruction tuning and reinforcement learning. The architecture achieves state-of-the-art comprehension, generation, and editing performance across benchmarks, enabled by scalable training and modular design. Limitations include gaps in generative quality versus commercial models and constrained editing scope, but the approach lays a robust foundation for future work in scalable, instruction-adherent visual LLMs.