- The paper introduces a novel code-driven approach that enables autonomous image manipulation and complex reasoning within multimodal LLMs.
- It employs a two-stage training strategy combining supervised fine-tuning on a 500K sample dataset and reinforcement learning with a GRPO-ATS algorithm to refine execution precision.
- Experimental results demonstrate significant improvements over baselines in perception and reasoning tasks, with gains up to 81.6% in certain challenging scenarios.
Thyme: Enabling Autonomous Code-Driven Image Manipulation and Reasoning in Multimodal LLMs
Introduction and Motivation
Thyme introduces a paradigm shift in multimodal LLMs (MLLMs) by enabling autonomous, code-driven image manipulation and mathematical reasoning. Unlike prior "think with images" approaches that are limited to cropping or rely on image generation, Thyme empowers models to dynamically generate and execute Python code for a broad spectrum of image operations (cropping, rotation, contrast enhancement, zooming) and complex computations. This is achieved through a tightly integrated model-sandbox architecture, allowing the model to decide when and how to invoke code, and to iteratively refine its reasoning based on execution feedback.
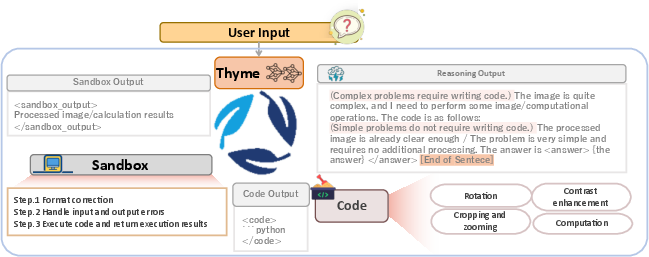
Figure 1: The Thyme pipeline, showing the iterative loop between model reasoning, code generation, sandbox execution, and feedback.
This design addresses the limitations of both cropping-only and image-generation-based methods, providing a richer, more flexible toolset for perception and reasoning tasks. The system is trained via a two-stage process: supervised fine-tuning (SFT) on a curated dataset to instill code generation capabilities, followed by reinforcement learning (RL) with a novel Group Relative Policy Optimization with Adaptive Temperature Sampling (GRPO-ATS) algorithm to refine decision-making and execution precision.
Data Construction and Training Methodology
SFT Data Pipeline
The SFT phase leverages a 500K-sample dataset constructed from over 4 million raw sources, encompassing direct-answer, image manipulation, and multi-turn reasoning tasks. The data pipeline involves prompt construction, model code generation, sandbox execution for code validation, MLLM-based verification of code-result alignment, and manual review for quality assurance.

Figure 2: SFT data construction pipeline, including automated and manual filtering for code validity and answer correctness.
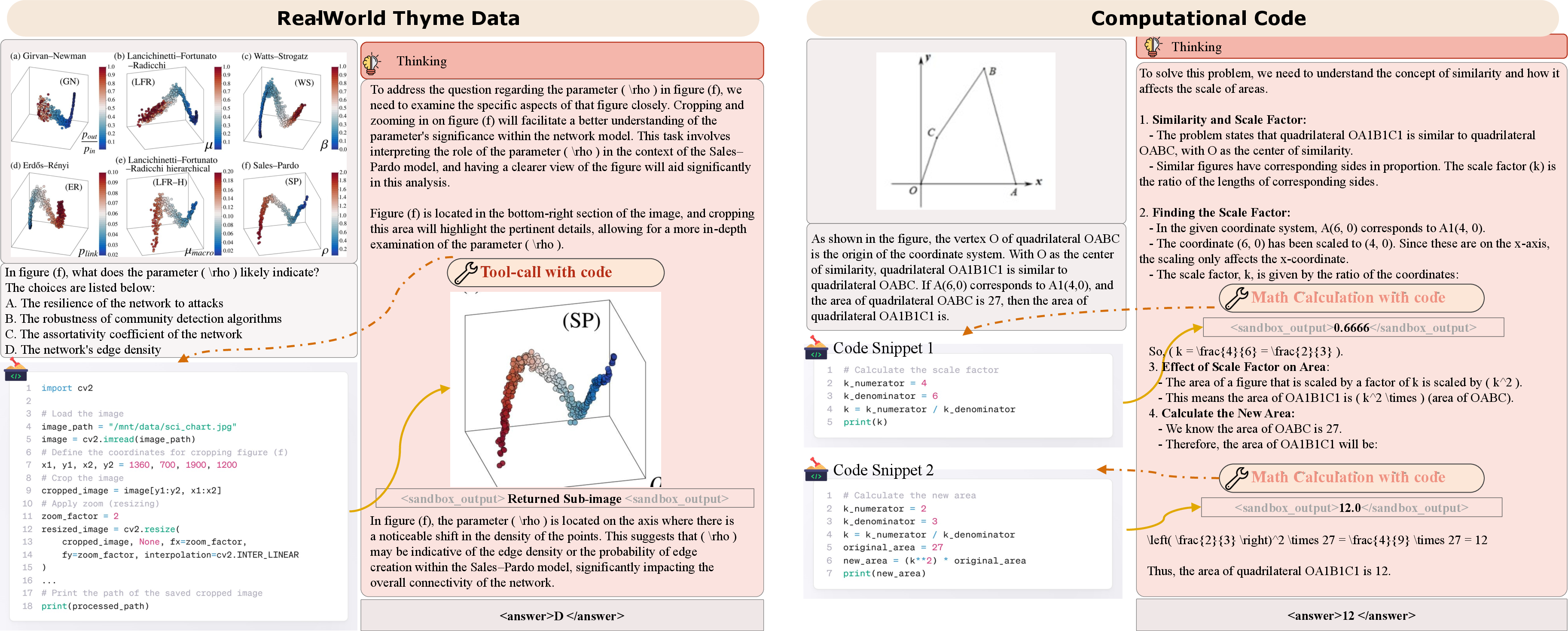
Figure 3: Examples of SFT data, illustrating both image manipulation and computational reasoning tasks.
Key strategies in SFT include masking sandbox outputs to prevent gradient contamination, focusing loss computation on the final round in multi-turn dialogues, and annealing on math data to ensure the model learns to generate computation code despite its lower frequency.
RL Data and Algorithmic Innovations
The RL phase supplements public datasets with 10,000 manually annotated, high-resolution, perceptually challenging images. Human annotators design questions targeting small, difficult-to-recognize objects, ensuring the RL data distribution is substantially more complex than standard benchmarks.

Figure 4: RL data instances, highlighting the focus on high-resolution, complex perception tasks.
The RL algorithm, GRPO-ATS, applies temperature 1.0 for text and 0.0 for code generation, balancing exploration in reasoning with determinism in code. This dual-temperature approach is critical: high temperature in code generation leads to invalid code and model collapse into code avoidance, while low temperature ensures code usability and effective tool use. Early termination via substring repetition detection and a cap on dialogue turns further improve sample efficiency.
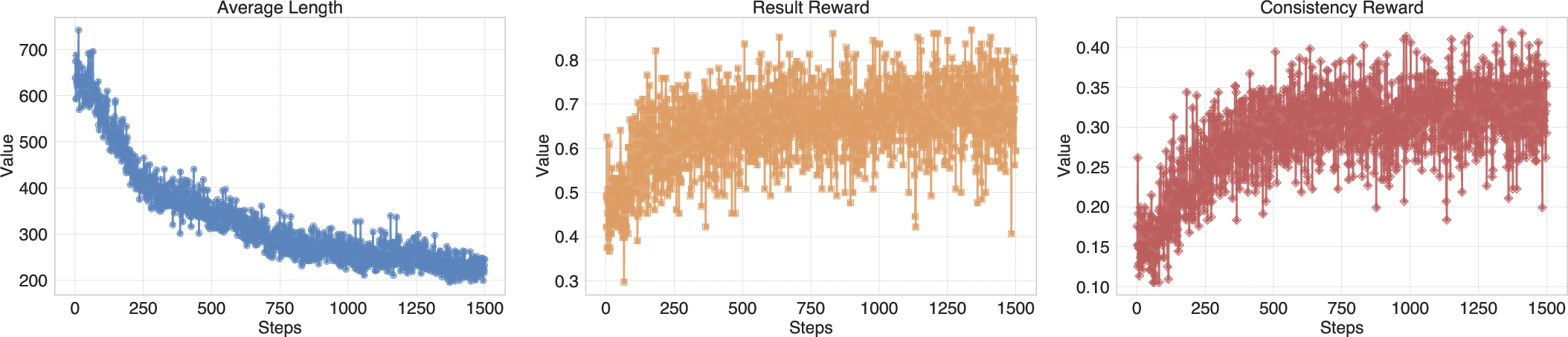
Figure 5: RL training dynamics, showing convergence in response length, accuracy, and consistency rewards.
Reward design combines formatting, result, and consistency rewards, with the latter only contributing when the answer is correct, preventing the model from optimizing for consistency at the expense of accuracy.
Model Architecture and Sandbox Design
The model is based on Qwen 2.5 VL 7B, with all code execution handled in a secure, robust Python sandbox. The sandbox automatically corrects minor code issues (formatting, boundary conditions, variable handling), reducing the code generation burden on the model and increasing the rate of successful executions. Dangerous operations are filtered, and execution time is capped to ensure system safety.
Experimental Results and Analysis
Thyme demonstrates substantial and consistent improvements over strong baselines (Qwen2.5-VL-7B, InternVL3-8B, Qwen2.5-VL-32B, GPT-4o) across nearly 20 benchmarks spanning perception, reasoning, and general tasks.
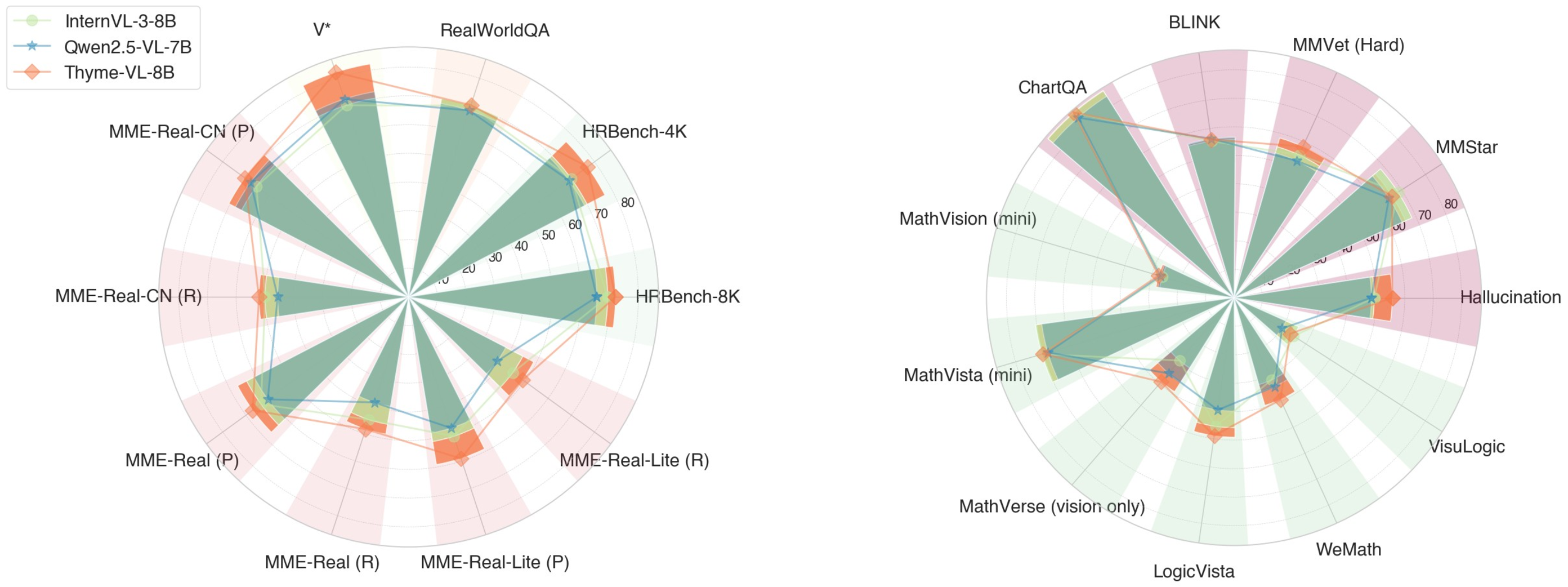
Figure 6: Thyme's benchmark performance, showing significant gains in perception and reasoning over baselines.
- On high-resolution perception tasks (e.g., HRBench-4K, MME-RealWorld), Thyme outperforms Qwen2.5-VL-7B by up to +11.1% in overall accuracy, and even surpasses larger models in several splits.
- In challenging domains such as monitoring and autonomous driving, Thyme achieves +27.1% and +65.0% relative improvements in perception, and +81.6% in reasoning.
- For mathematical reasoning (MathVision, MathVerse, LogicVista), Thyme consistently outperforms the baseline, with improvements up to +9.2%.
- General tasks (hallucination, chart QA, MMVet Hard) also see notable gains, with hallucination reduction and improved robustness.
Qualitative Case Studies
Thyme's code-driven approach enables nuanced, context-sensitive tool use:
- Cropping and Zooming: The model autonomously identifies small, distant objects (e.g., street signs, phone numbers), generates code to crop and zoom, and accurately answers questions.

Figure 7: Thyme autonomously crops and zooms to identify a street sign in a high-resolution image.

Figure 8: Thyme locates and zooms in on a phone number, demonstrating precise region selection.

Figure 9: Thyme analyzes the image, determines the absence of target objects, and justifies its answer.
- Rotation and Contrast Enhancement: Thyme detects misoriented or low-contrast images, applies the appropriate transformation via code, and extracts the required information.

Figure 10: Thyme rotates an image to correct orientation before extracting a mathematical expression.

Figure 11: Thyme enhances image contrast to improve OCR performance.
- Complex Computation: The model translates multi-step mathematical reasoning into executable code, ensuring correctness and transparency.
Failure Modes
Despite its strengths, Thyme exhibits several failure cases:
- Omission of Tool Use: In some high-resolution scenarios, the model answers directly without performing necessary cropping (Figure 12).
- Unnecessary Code Generation: For trivial calculations, Thyme may generate code unnecessarily, sometimes introducing errors (Figure 13).
- Inaccurate Cropping: The model may crop irrelevant regions but still arrive at the correct answer, indicating imperfect spatial localization (Figure 14).
Implications and Future Directions
Thyme demonstrates that code-driven tool use, when tightly integrated with MLLMs, can substantially enhance both perception and reasoning, especially in high-resolution and complex scenarios. The dual-temperature RL strategy is critical for balancing exploration and code reliability, and the sandbox abstraction is essential for practical deployment.
However, the approach is still bounded by the underlying model's localization and code synthesis capabilities. Scaling to stronger base models and further improving spatial reasoning and code generation fidelity are natural next steps. Additionally, the lack of robust benchmarks for advanced image manipulations (e.g., rotation correction, contrast enhancement) limits comprehensive evaluation; new datasets targeting these capabilities are needed.
The open-sourcing of Thyme's datasets, sandbox, and code will facilitate further research into autonomous tool use, multimodal reasoning, and the development of more generalist AI systems.
Conclusion
Thyme establishes a new paradigm for MLLMs by enabling autonomous, code-driven image manipulation and reasoning. Through a combination of curated SFT data, RL with adaptive temperature control, and robust sandbox execution, Thyme achieves significant and consistent improvements over strong baselines in perception, reasoning, and general tasks. The work highlights the importance of integrating executable tool use into multimodal models and provides a foundation for future research in autonomous, generalist AI systems.

