Sakuga-42M Dataset: Scaling Up Cartoon Research
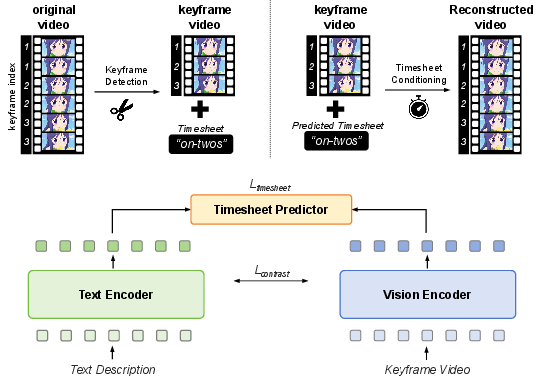
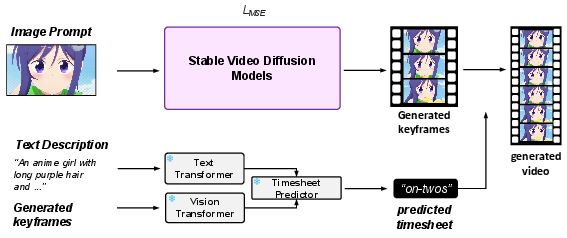
Abstract: Hand-drawn cartoon animation employs sketches and flat-color segments to create the illusion of motion. While recent advancements like CLIP, SVD, and Sora show impressive results in understanding and generating natural video by scaling large models with extensive datasets, they are not as effective for cartoons. Through our empirical experiments, we argue that this ineffectiveness stems from a notable bias in hand-drawn cartoons that diverges from the distribution of natural videos. Can we harness the success of the scaling paradigm to benefit cartoon research? Unfortunately, until now, there has not been a sizable cartoon dataset available for exploration. In this research, we propose the Sakuga-42M Dataset, the first large-scale cartoon animation dataset. Sakuga-42M comprises 42 million keyframes covering various artistic styles, regions, and years, with comprehensive semantic annotations including video-text description pairs, anime tags, content taxonomies, etc. We pioneer the benefits of such a large-scale cartoon dataset on comprehension and generation tasks by finetuning contemporary foundation models like Video CLIP, Video Mamba, and SVD, achieving outstanding performance on cartoon-related tasks. Our motivation is to introduce large-scaling to cartoon research and foster generalization and robustness in future cartoon applications. Dataset, Code, and Pretrained Models will be publicly available.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023.
- Sora. https://openai.com/sora. Accessed: 2024-5-12.
- Deep animation video interpolation in the wild. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6587–6595, 2021.
- Deep geometrized cartoon line inbetweening. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7291–7300, 2023.
- Internvid: A large-scale video-text dataset for multimodal understanding and generation. arXiv preprint arXiv:2307.06942, 2023.
- Videomamba: State space model for efficient video understanding. arXiv preprint arXiv:2403.06977, 2024.
- Pika. https://pika.art/. Accessed: 2024-5-3.
- Gen-2. https://research.runwayml.com/gen2. Accessed: 2024-5-3.
- Learning inclusion matching for animation paint bucket colorization. CVPR, 2024.
- Joint stroke tracing and correspondence for 2d animation. ACM Trans. Graph., 43(3), apr 2024.
- The animation transformer: Visual correspondence via segment matching. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11323–11332, 2021.
- Sprite-from-sprite: Cartoon animation decomposition with self-supervised sprite estimation. ACM Trans. Graph., 41(6), nov 2022.
- Re: Draw–context aware translation as a controllable method for artistic production. arXiv preprint arXiv:2401.03499, 2024.
- Toonsynth: example-based synthesis of hand-colored cartoon animations. ACM Transactions on Graphics (TOG), 37(4):1–11, 2018.
- Globally optimal toon tracking. ACM Transactions on Graphics (TOG), 35(4):1–10, 2016.
- Stereoscopizing cel animations. ACM Transactions on Graphics (TOG), 32(6):1–10, 2013.
- Dilight: Digital light table–inbetweening for 2d animations using guidelines. Computers & Graphics, 65:31–44, 2017.
- Exploring inbetween charts with trajectory-guided sliders for cutout animation. Multimedia Tools and Applications, pages 1–14, 2023.
- Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725, 2023.
- Animate anyone: Consistent and controllable image-to-video synthesis for character animation. arXiv preprint arXiv:2311.17117, 2023.
- Panda-70m: Captioning 70m videos with multiple cross-modality teachers. arXiv preprint arXiv:2402.19479, 2024.
- Frozen in time: A joint video and image encoder for end-to-end retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1728–1738, 2021.
- Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- Pyscenedetect. https://github.com/Breakthrough/PySceneDetect. Accessed: 2024-5-12.
- Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744, 2023.
- Share captioner. https://huggingface.co/Lin-Chen/ShareCaptioner. Accessed: 2024-5-12.
- Danbooru2021. https://gwern.net/danbooru2021. Accessed: 2024-5-12.
- Waifu dataset. https://github.com/thewaifuproject/waifu-dataset. Accessed: 2024-5-12.
- wd14-swin-v2. https://huggingface.co/SmilingWolf/wd-v1-4-swinv2-tagger-v2. Accessed: 2024-5-12.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pages 19730–19742. PMLR, 2023.
- chatgpt. https://chatgpt.com/. Accessed: 2024-5-12.
- Dall-e3. https://openai.com/dall-e-3. Accessed: 2024-5-12.
- cafe-aesthetic-model. https://huggingface.co/cafeai/cafe_aesthetic. Accessed: 2024-5-12.
- manga-image-translator. https://github.com/zyddnys/manga-image-translator. Accessed: 2024-5-12.
- Learning audio-video modalities from image captions. In European Conference on Computer Vision, pages 407–426. Springer, 2022.
- Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021.
- Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision, 123:32–73, 2017.
- Im2text: Describing images using 1 million captioned photographs. Advances in neural information processing systems, 24, 2011.
- Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22563–22575, 2023.
- High-resolution image synthesis with latent diffusion models. 2022 ieee. In CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, 2021.
- Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4296–4304, 2024.
- Gpt-4v. https://openai.com/research/gpt-4v-system-card. Accessed: 2024-5-12.
- Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023.
- Efficient in-context learning in vision-language models for egocentric videos. arXiv preprint arXiv:2311.17041, 2023.
- Manga line extraction. https://github.com/ljsabc/MangaLineExtraction_PyTorch. Accessed: 2024-5-12.
- Anime2sketch. https://github.com/Mukosame/Anime2Sketch. Accessed: 2024-5-12.
- Automatic temporally coherent video colorization. In 2019 16th conference on computer and robot vision (CRV), pages 189–194. IEEE, 2019.
- Optical flow based line drawing frame interpolation using distance transform to support inbetweenings. In 2019 IEEE International Conference on Image Processing (ICIP), pages 4200–4204. IEEE, 2019.
- Deep sketch-guided cartoon video inbetweening. IEEE Transactions on Visualization and Computer Graphics, 28(8):2938–2952, 2021.
- Ldmvfi: Video frame interpolation with latent diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 1472–1480, 2024.
- I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models. arXiv preprint arXiv:2311.04145, 2023.
- Wenhao Wang and Yi Yang. Vidprom: A million-scale real prompt-gallery dataset for text-to-video diffusion models. arXiv preprint arXiv:2403.06098, 2024.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

