- The paper introduces CodeGrad, which integrates multi-step verification with gradient-based LLM refinement to enhance automated code generation.
- It employs an iterative process combining forward generation, backward evaluation, gradient propagation, and formal optimization to meet strict correctness and efficiency constraints.
- Results show significant improvements on benchmarks like HumanEval (+27.2%) and simulation tasks (+152%), underscoring the method's practical efficacy.
CodeGrad: Integrating Multi-Step Verification with Gradient-Based LLM Refinement
Introduction
"CodeGrad: Integrating Multi-Step Verification with Gradient-Based LLM Refinement" proposes a novel framework to address challenges in automated code generation using LLMs. Despite the capabilities of LLMs in generating code, inherent limitations in ensuring correctness, efficiency, and completeness persist. CodeGrad integrates rigorous formal verification techniques within an iterative LLM-driven loop, effectively treating generated code as a differentiable variable influenced by pseudo-gradients derived from formal critical analysis.
Methodology
Problem Definition: The framework seeks to generate code that meets both functional correctness against a ground-truth model as specified by a natural language description and adheres to formally defined invariants, including completeness and efficiency constraints.
Formal-Gradient Code Generation Pipeline: The pipeline involves four iterative phases crucial for refining code solutions:
- Forward Generation: A code-centric LLM proposes initial or revised code implementations based on task descriptions and previous iteration feedback direction.
- Backward Evaluation: A separate backward model reviews the code, identifying flaws and suggesting structured corrections in areas such as correctness, I/O format, and efficiency.
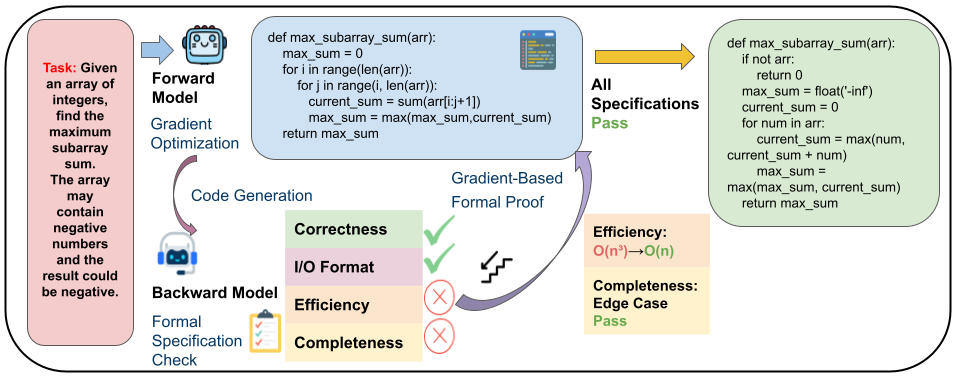
Figure 1: Overview of the Formal-Gradient Code Generation loop showcasing a transition from a computationally inefficient solution to an optimal one guided by formal critique.
- Gradient Propagation: The textual critique is transformed into a pseudo-gradient that guides modifications to improve the code.
- Formal Optimization: The iteration cycle strives for code revisions that strictly satisfy the formal invariants, terminating upon successful verification or maximum iteration bounds.
Results
The framework was evaluated using the HumanEval, HumanEval+, and LiveCodeBench V6 benchmarks, achieving significant improvements over baseline models:
- HumanEval: A performance increase of up to 27.2%.
- LiveCodeBench V6: A relative improvement of 40.6%.
Performance varied substantially across problem categories:
- Greedy Algorithms: CodeGrad effectively solved these problems where the baseline models could not, proving its competence in navigating complex constraints.
- Simulation Tasks: Notable improvements (+152%) relative to baseline models.
(Table 1)
Table 1: Pass@1 performance across benchmarks, demonstrating improvements with CodeGrad.
Additionally, analysis demonstrated transformative gains (+611%) on medium difficulty problems where baseline models faltered, accentuating CodeGrad’s capability in handling complexity.
Implications
CodeGrad opens avenues for reliable AI-assisted code generation in domains that necessitate rigorous formal verification. Its success in comprehensive problem sets suggests potential applications in automated program repair and interactive proof generation.
Conclusion
CodeGrad exemplifies the integration of LLM flexibility with verifiable formal methods, significantly enhancing code generation reliability in stringent scenarios. The framework's approach to iterative refinement via formal critique offers sustainable solutions for AI-driven software development.
The development and impact of CodeGrad serve as a testament to its role in advancing automated software engineering through innovative methodologies, pushing the boundaries of what AI can achieve in high-stakes environments.

