- The paper introduces a layered avatar synthesis framework that decouples hair, garment, and body meshes to enable independent, physically plausible simulation and animation.
- It employs dedicated, text-conditioned generative models and 3D Gaussian splatting optimized via Score Distillation Sampling to achieve high visual fidelity.
- Experimental evaluations show superior performance with a VQAScore of 0.75 and over 89% user preference, setting new benchmarks in avatar realism and dynamic simulation.
SimAvatar: Simulation-Ready Avatars with Layered Hair and Clothing
SimAvatar addresses the challenge of synthesizing simulation-ready, clothed 3D human avatars from text prompts, targeting limitations in previous avatar generation models which entangle body, hair, and garment geometry—impeding independent simulation and physically plausible animation. The paper confronts the disconnect between implicit representations (optimal for leveraging priors from image diffusion models but unsuitable for animation in existing simulators) and explicit geometry required for physics-based or neural simulators. By seeking a representation compatible with both generative priors and simulation frameworks, SimAvatar proposes a layered architecture that enables physically plausible, pose-dependent deformations of garment and hair while maintaining high-fidelity appearance.

Figure 1: SimAvatar workflow: text prompts drive separate generation of hair strands, body mesh, and garment mesh, with 3D Gaussians optimized for visual fidelity and physical simulations.
Methodological Contributions
SimAvatar's framework decomposes avatars into three simulation-ready layers—hair strands, garment mesh, and SMPL body mesh—each generated by dedicated, text-conditioned generative models. Hair strands are produced using a diffusion-based model (HAAR), garments are obtained from a text-to-mesh diffusion model trained on large-scale garment datasets (GPG, CLOTH3D), and body shape comes from a GPT-based model (BodyShapeGPT). These explicit geometries enable compatibility with physics-based and neural simulation protocols.
Appearance modeling leverages 3D Gaussian Splatting (3DGS), augmenting each geometric layer with spatially attached Gaussians, whose properties (location, orientation, scale, color features, opacity) are optimized via Score Distillation Sampling (SDS) using powerful diffusion priors. To enforce plausible disentanglement and prevent artifacts (e.g., broken hair), additional regularization is applied—specifically on hair Gaussians' opacity, ensuring root-to-tip continuity. Prompt engineering is coupled with layer-wise optimization to further disentangle appearance and geometry across face, hair, and garment.
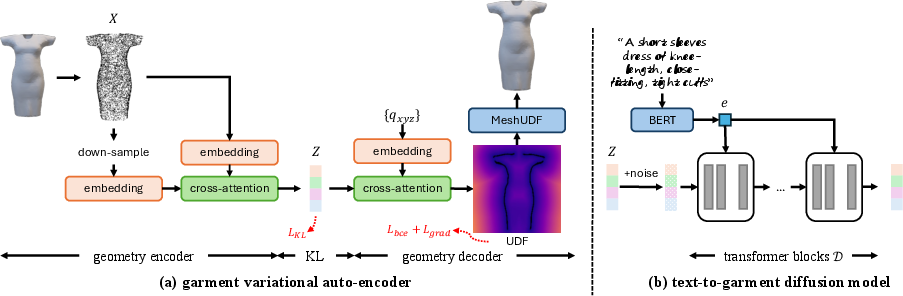
Figure 2: Architecture of the text-based garment diffusion model, combining VAE encoding of mesh geometry with latent diffusion, conditioned on text descriptions.
Simulation and Animation Pipeline
For driving avatar motion, the body mesh undergoes linear blend skinning for pose deformation, while hair strands and garment meshes are evolved by dedicated simulators—either neural (HOOD) or physics-based—where garments are simulated as draped meshes and hair strands as strand-based representations. Gaussians attached to these layers are transformed accordingly, ensuring persistent alignment with dynamic geometry. The approach allows independent and physically plausible motion of loose garments (e.g., dresses) and flowing hair, which previous works fail to deliver due to geometric entanglement or implicit representation limitations.
Experimental Evaluations
SimAvatar is rigorously evaluated against state-of-the-art models (Fantasia3D, TADA, GAvatar), with qualitative comparisons highlighting superior diversity, fidelity of garment types, and animated realism. Only SimAvatar can produce physically plausible animation for complex garments, such as maintaining dress continuity during leg raise motions, which baseline methods fail to achieve.

Figure 3: Qualitative comparison of static avatars: SimAvatar captures diverse garment topology and texture, outperforming Fantasia3D, TADA, and GAvatar.

Figure 4: Animated avatar comparison: SimAvatar yields physically plausible garment and hair deformation under pose changes, with baselines showing artifacts and unrealistic separation.
Quantitative assessment includes two metrics:
- VQAScore (alignment between generated avatars and detailed prompts): SimAvatar achieves a score of 0.75, compared to up to 0.53 with baselines.
- User preference studies: In extensive A/B testing (>500 votes), SimAvatar is strongly favored (> 89% for appearance and motion).
Ablation studies demonstrate the necessity of hair constraints and disentangled prompt-layer optimization; without these, artifacts and entanglements persist. Layer-wise rendering of each region, coupled with targeted prompts, is critical for preventing cross-layer contamination of textures.

Figure 5: Ablation results illustrating broken hair without regularization and texture entanglement without layer-wise optimization.
Implications and Future Directions
Theoretical implications center on the reconciliation of generative and simulation paradigms in avatar synthesis, demonstrating the necessity for explicit layered geometry to harness both high-fidelity priors and robust physical animation. Practically, SimAvatar unlocks scalable creation of avatars for applications in virtual try-on, film, gaming, AR/VR, and telepresence, where dynamic realism and full-layered control are essential. The approach sets a precedent for disentangled, simulation-ready asset generation, enabling downstream editing, animation, and independent manipulation of each avatar component.
Key limitations involve dependency on training data diversity for garment and hair models, sequential simulation architecture (potentially problematic for complex interactions such as hair/hood), and lack of disentanglement for accessories/footwear. Future work aims to address multi-modal simulation, expand dataset-driven diversity, and fully disentangle all wearable assets.

Figure 6: Additional qualitative results highlighting CLIP and VQAScore; SimAvatar produces diverse, prompt-aligned avatars with high numerical alignment.

Figure 7: Additional qualitative results demonstrating range and visual fidelity of SimAvatar-generated avatars.

Figure 8: Layer-wise visualization of SimAvatar—individual geometry and texture of hair, garment, and body.

Figure 9: Additional layer-wise visualizations showing the separate modeling of each avatar component.
Conclusion
SimAvatar introduces a novel layered methodology for simulation-ready 3D avatar synthesis from text prompts, unifying explicit geometry, data-driven generative models, 3D Gaussian-based appearance optimization, and robust physics-driven animation. The approach resolves core technical bottlenecks in previous methods, delivering avatars with unprecedented dynamic realism, disentangled structure, and high prompt alignment. Future extensions will focus on increasing compositional diversity, more complex simulation regimes, and further asset disentanglement, establishing SimAvatar as a paradigm for next-generation animatable avatar creation (2412.09545).

