- The paper introduces a full-stack Q fine-tuning pipeline that integrates domain-adaptive pretraining, supervised fine-tuning, and reinforcement learning to significantly improve code generation performance.
- The paper constructs a novel LeetCode-style Q benchmark with 678 problems to provide a standardized evaluation, highlighting difficulty stratification and algorithmic diversity.
- The paper demonstrates that larger models (up to 32B) and reasoning augmentation yield substantial cumulative gains, outperforming state-of-the-art closed-source models.
Full-Stack Fine-Tuning for the Q Programming Language: An Expert Analysis
Introduction and Motivation
This technical report presents a comprehensive methodology for adapting LLMs to the Q programming language, a domain-specific language central to quantitative finance but underrepresented in public code corpora. The authors address the challenge of LLM specialization for niche languages by constructing a LeetCode-style Q benchmark, systematically evaluating both open and closed-source models, and developing a full-stack adaptation pipeline comprising domain-adaptive pretraining, supervised fine-tuning (SFT), and reinforcement learning (RL). The resulting Qwen-2.5-based models, spanning 1.5B to 32B parameters, are shown to outperform GPT-4.1 and, at the largest scale, surpass Claude Opus-4 on the Q benchmark.
Dataset Construction and Evaluation Harness
A central contribution is the creation of a LeetCode-style Q dataset, addressing the absence of standardized benchmarks for Q code generation. The dataset construction pipeline is model-in-the-loop, leveraging LLMs to translate Python LeetCode problems into Q, with strict separation between solution and test harness generation to mitigate reward hacking. Automated verification is performed via execution in a Q interpreter and, where necessary, LLM-based output equivalence checks. The final dataset comprises 678 problems, stratified by difficulty and algorithmic category.
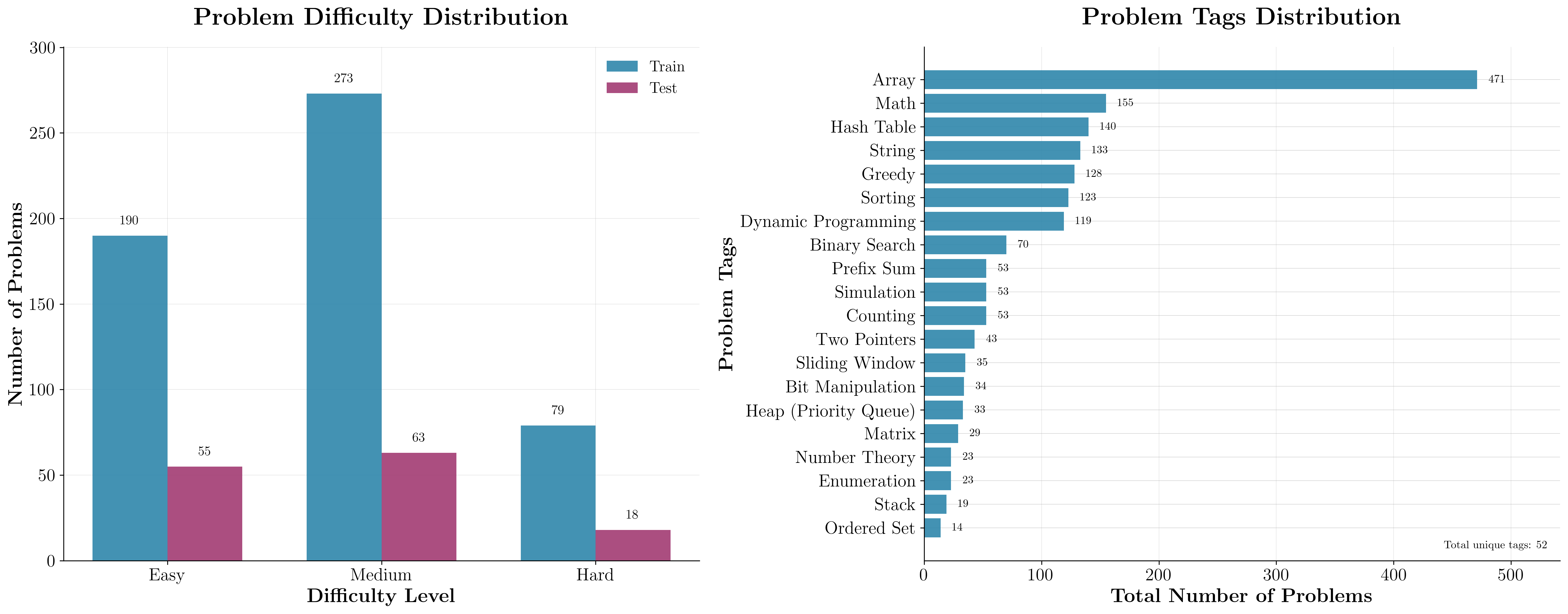
Figure 1: Distribution of problem difficulty and algorithmic tags in the Q-LeetCode dataset, ensuring coverage across a diverse set of tasks.
The evaluation harness is engineered for high-throughput, parallelized benchmarking, supporting both API-based and self-hosted models. The primary metric is pass@k, with k up to 40, following established code LLM evaluation protocols. The harness supports multiple evaluation modes, including retries and context augmentation, and is designed for rapid iteration and scalability.
Baseline Model Benchmarking
Initial benchmarking reveals that even state-of-the-art closed-source models (Claude Opus-4, Sonnet-4, GPT-4.1) perform poorly on Q code generation, with pass@1 rates below 30% for the best models and near-zero for GPT-4.1. Open-source Qwen-2.5 models, prior to adaptation, are similarly weak. Notably, Q-to-Python translation is substantially easier for all models, indicating that Q code synthesis, rather than comprehension, is the primary bottleneck.
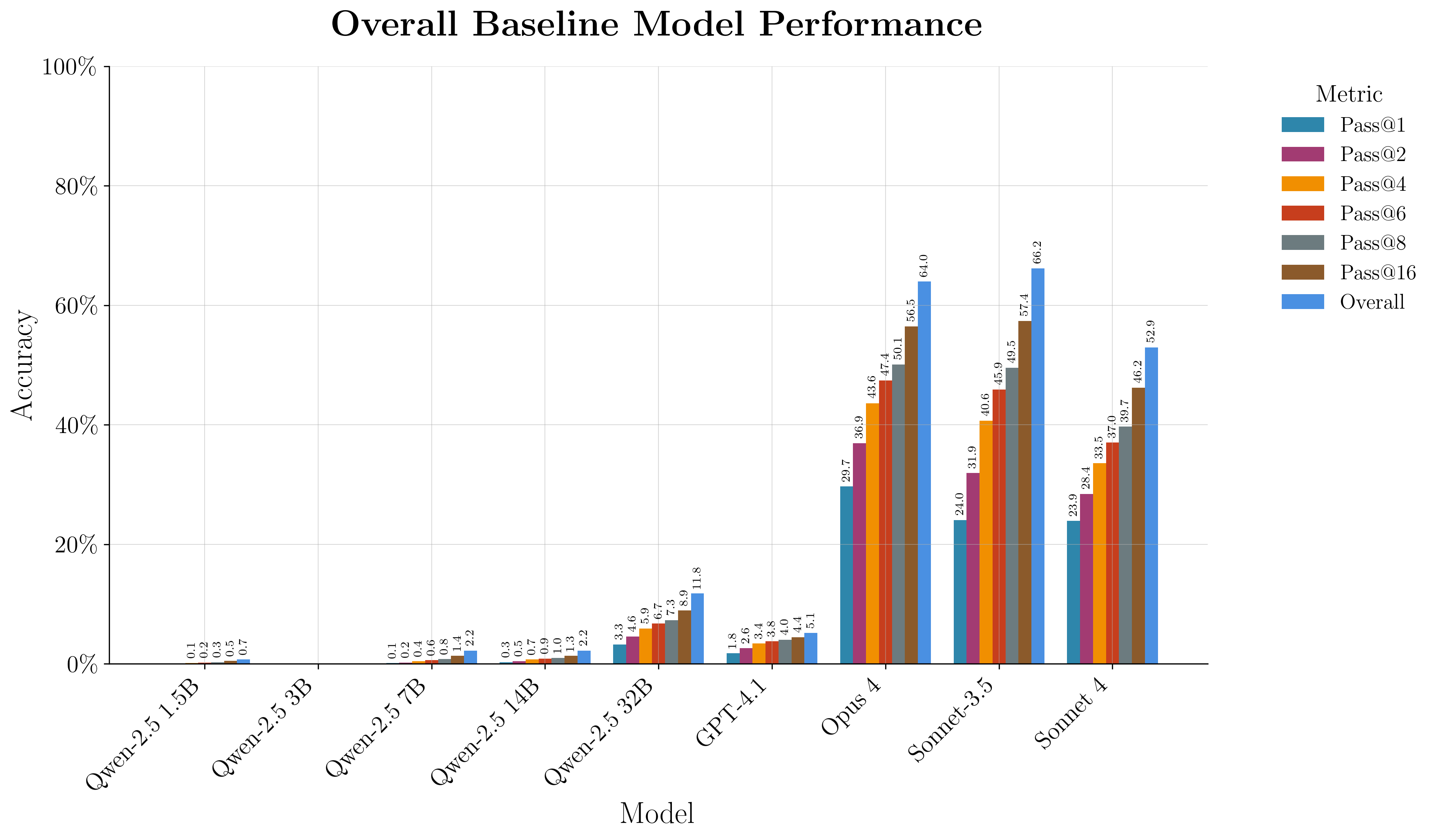
Figure 2: Probabilistic pass@k comparison across all models, highlighting the overall difficulty of Q code generation and the performance gap between model families.
Domain-Adaptive Pretraining
The pretraining phase utilizes a curated, license-permissive Q code corpus, filtered via LLM-assigned usefulness scores and manual inspection. Pretraining is performed with next-token prediction on raw Q code, not instruction data, to maximize exposure to Q syntax and idioms. Larger models (14B, 32B) exhibit overfitting on the limited corpus, necessitating early stopping, while smaller models show stable loss curves.
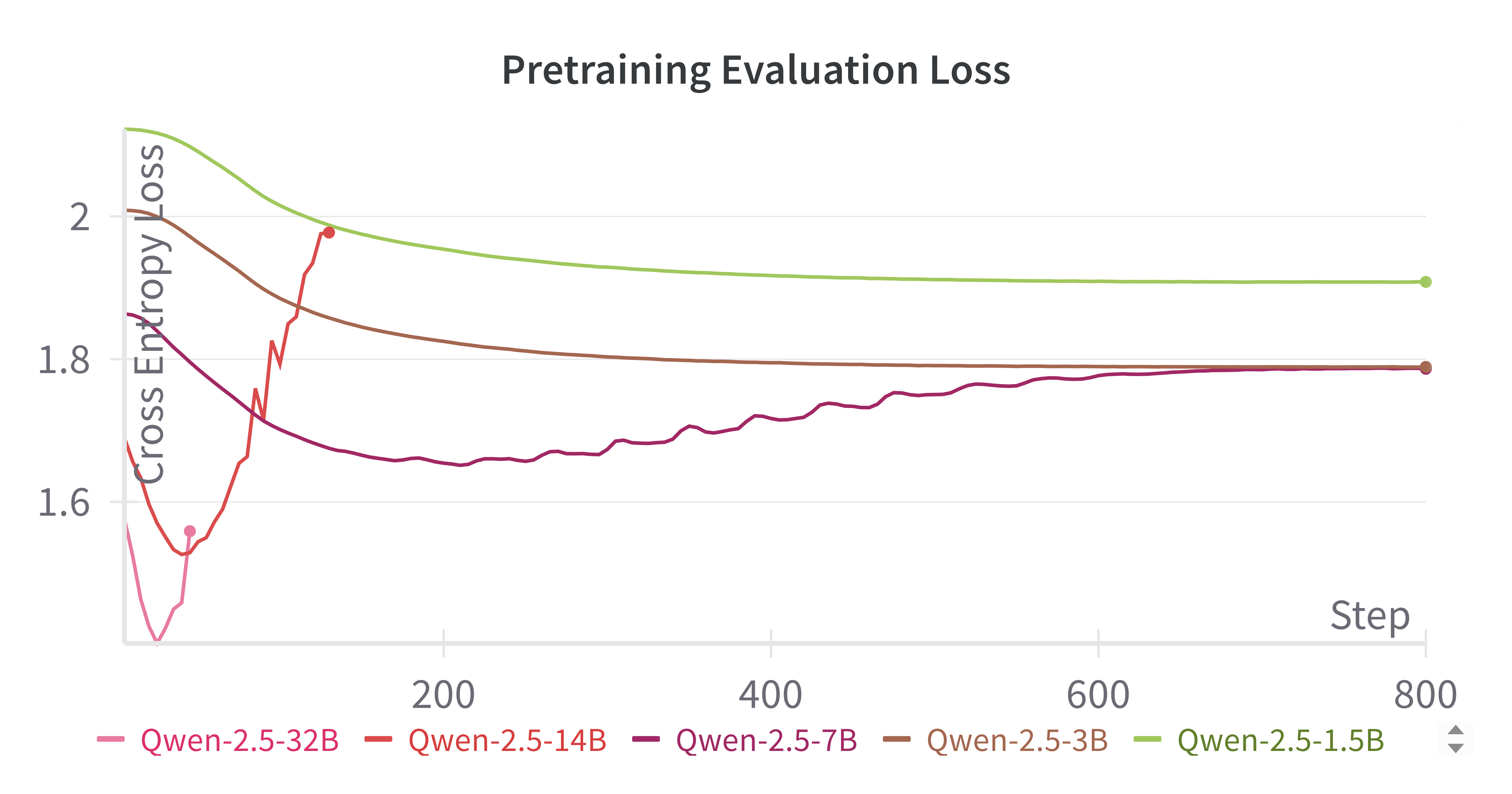
Figure 3: Pretraining evaluation loss curves for all Qwen-2.5 model sizes, illustrating overfitting in high-capacity models and the need for careful model selection.
Pretraining yields incremental but consistent gains in pass@k, with larger models benefiting more. LoRA-based pretraining is slightly more effective than full-parameter, but full-model finetuning is preferred for downstream compatibility.
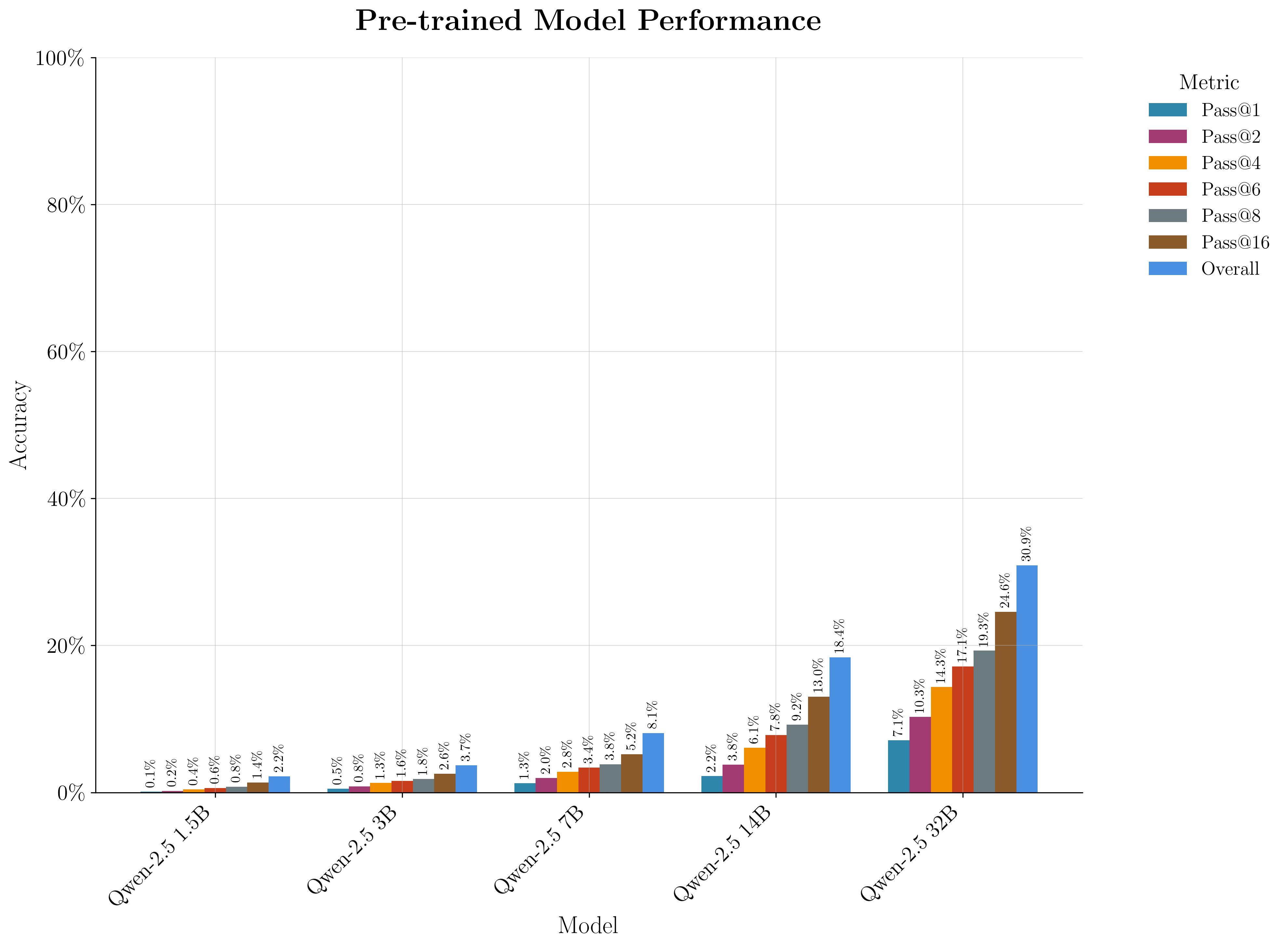
Figure 4: Pass@k performance on the Q-LeetCode benchmark after pretraining, showing systematic improvements with increasing model size.
Supervised Fine-Tuning
SFT is performed on the full LeetCode-Q dataset, with each problem expanded into multiple instruction-tuning samples (description-to-Q, Q-to-Python, Python-to-Q, test harness translation). Ablation studies on the 7B model indicate that full-model SFT outperforms LoRA, and that curriculum learning strategies provide marginal benefit. Interestingly, initializing from the pretrained checkpoint can slightly reduce SFT performance on the LeetCode-Q task, likely due to a trade-off between general Q knowledge and the highly Pythonic structure of the dataset.
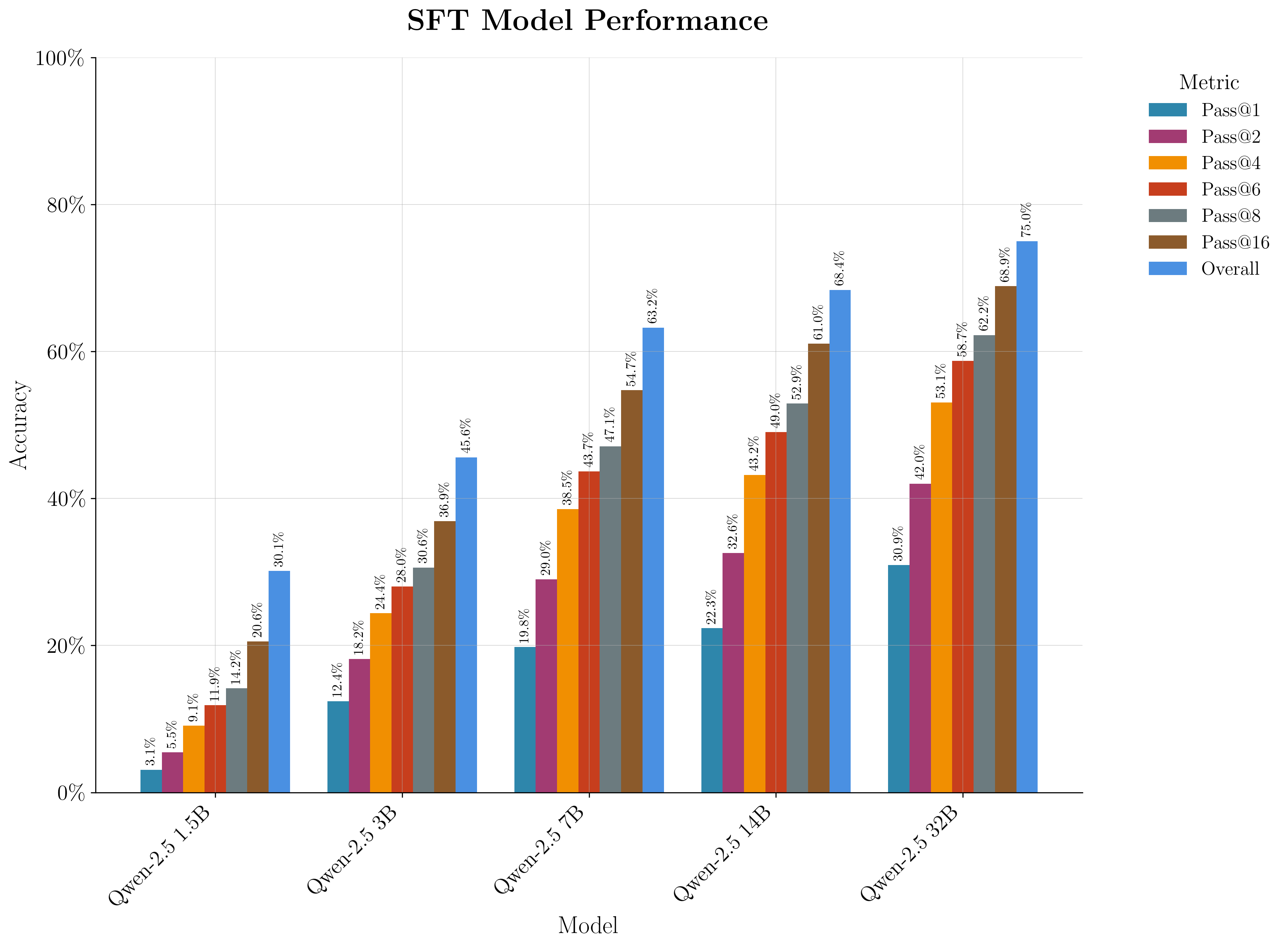
Figure 5: Pass@k results for each Qwen-2.5 base model after SFT, demonstrating systematic accuracy gains across all model sizes.
Reinforcement Learning
The RL phase employs Group Relative Policy Optimization (GRPO), with reward signals based on test case pass rates and perfect completion bonuses. Both reasoning-augmented and non-reasoning models are trained, with ablations on reward structure and sampling temperature. RL yields clear improvements for 14B and 32B models, with the largest reasoning-augmented model achieving the highest accuracies. The 1.5B model does not benefit from RL, and in some cases, performance degrades.
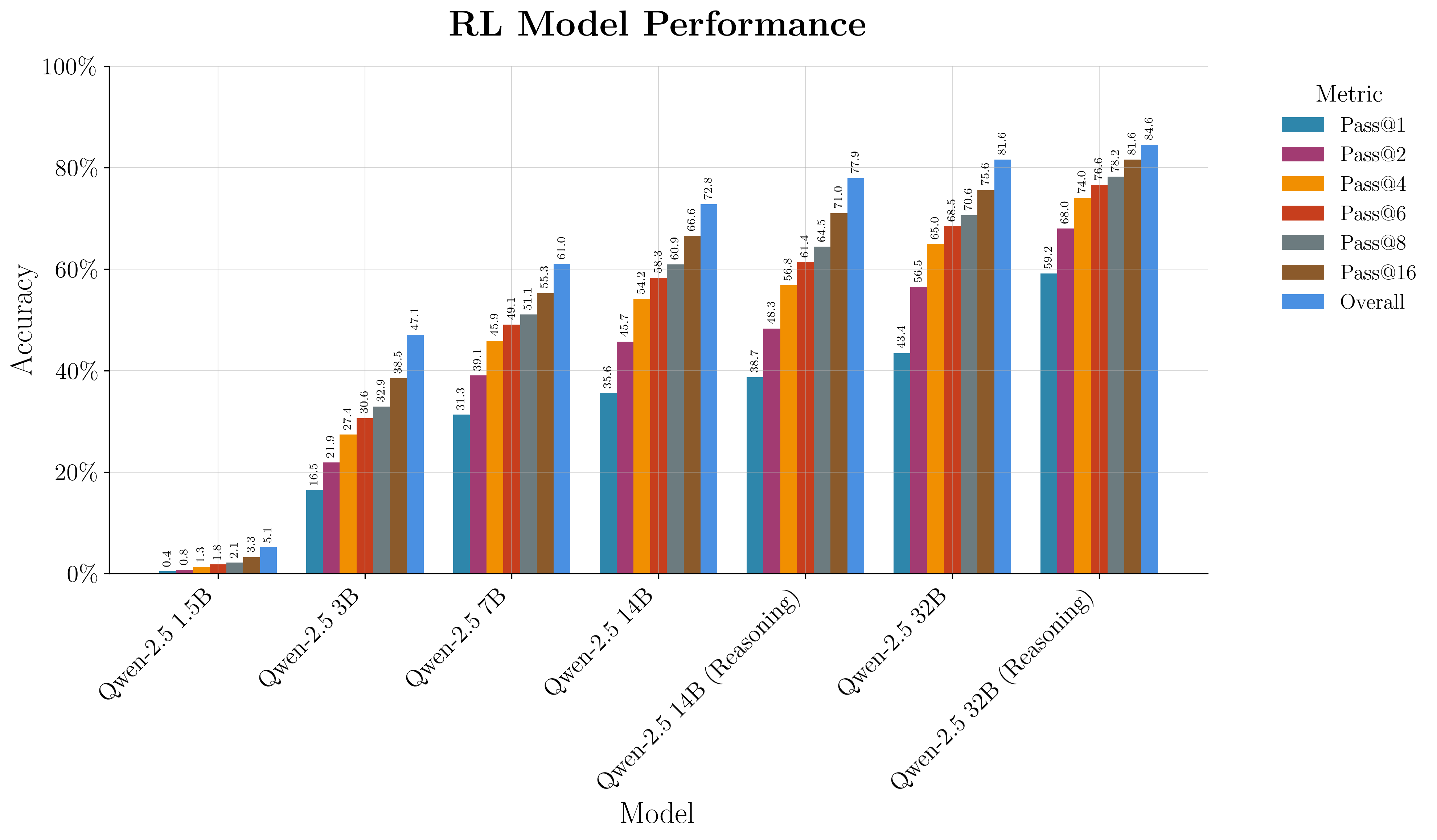
Figure 6: RL model performance across the Qwen-2.5 series, with reasoning-augmented models at large scale achieving the highest pass@k rates.
Training dynamics for the 32B reasoning model show stable, monotonic reward improvement and non-monotonic completion length, suggesting evolving solution strategies during RL.
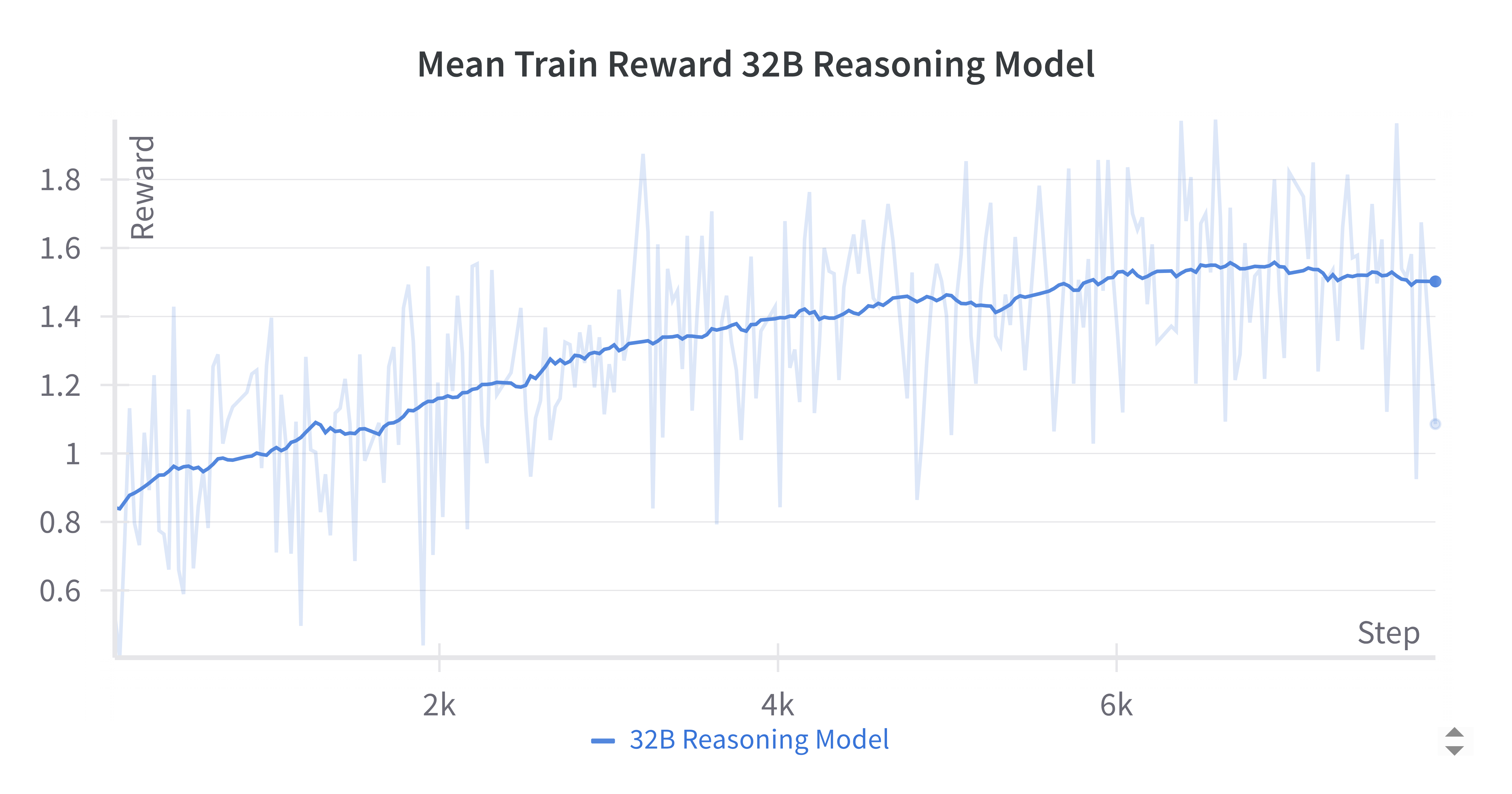
Figure 7: Average training reward during GRPO for the Qwen-2.5-32B reasoning model, indicating effective reward-driven optimization.
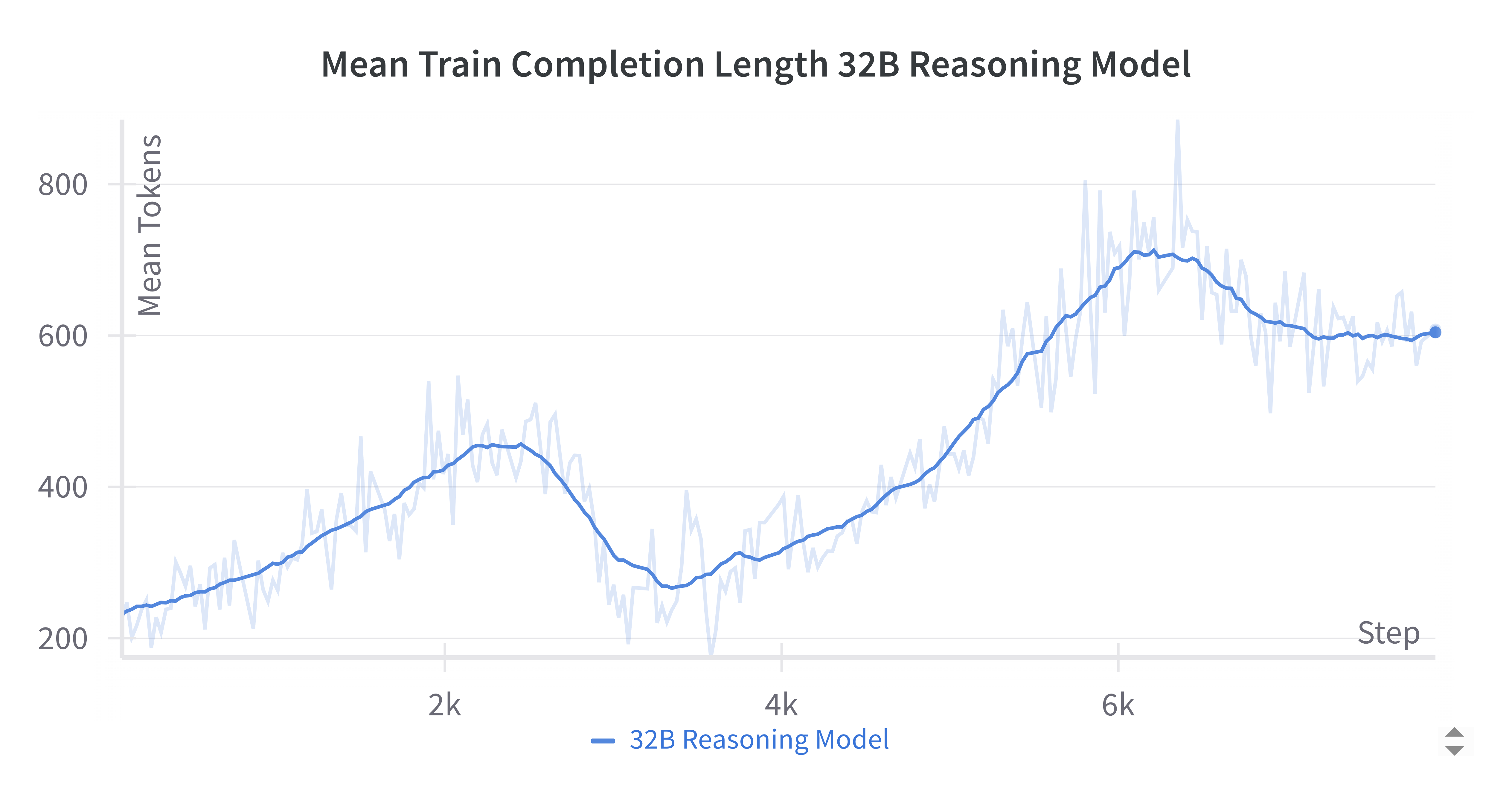
Figure 8: Mean completion length during RL adaptation, reflecting the model's evolving approach to problem solving.
The full-stack adaptation pipeline—pretraining, SFT, RL—yields substantial cumulative gains, especially for larger models. The 32B reasoning-augmented model achieves a pass@1 of 59% on the Q benchmark, surpassing Claude Opus-4 by 29.5%. All Qwen-2.5 models, including the 1.5B variant, outperform GPT-4.1. The staged improvements are visualized in a stacked bar chart, emphasizing the additive value of each adaptation phase.
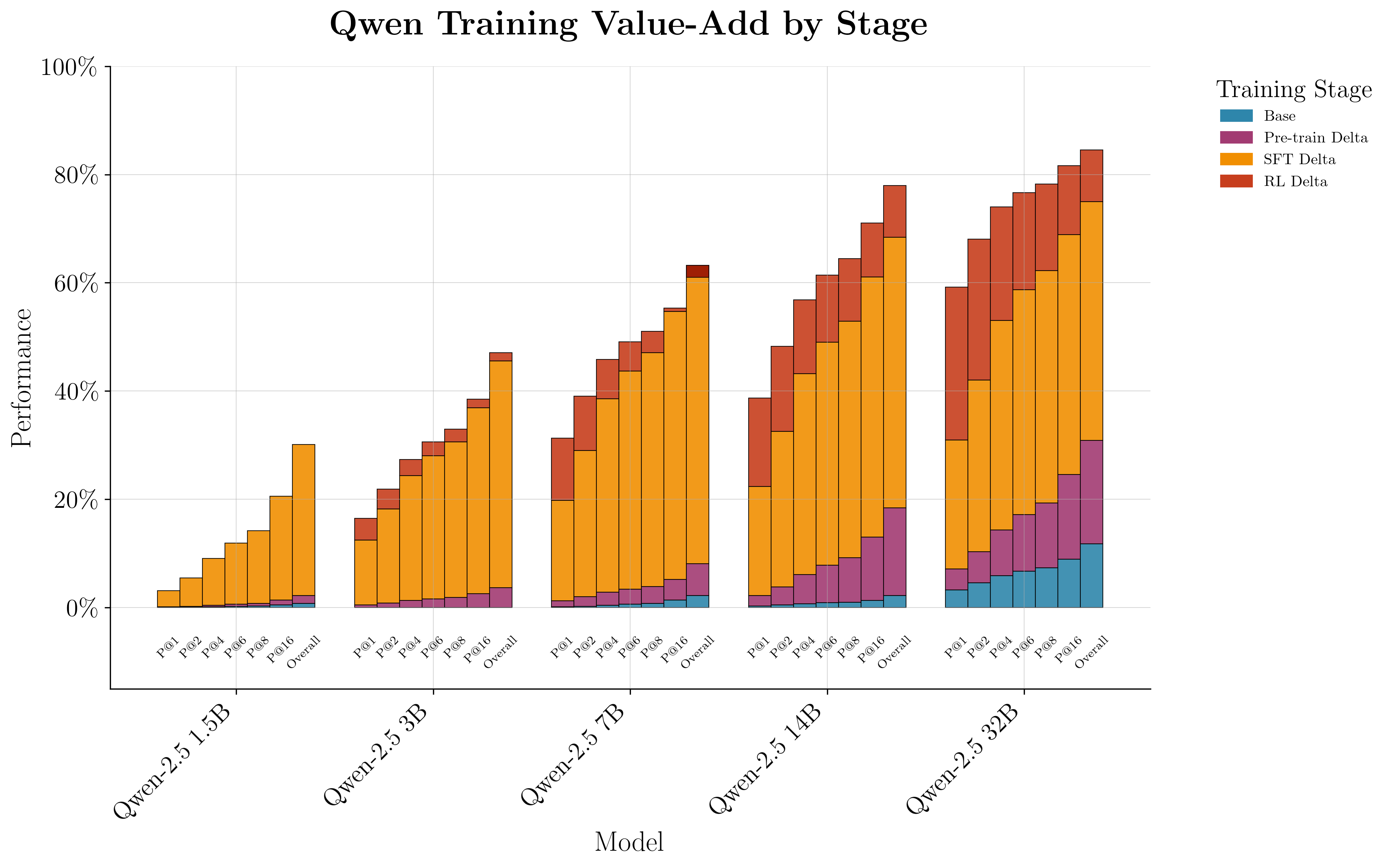
Figure 9: Cumulative pass@k improvements for all Qwen-2.5 model sizes across adaptation stages, with significant gains for larger models.
Error Analysis and Limitations
Error analysis by problem category and difficulty reveals that model accuracy declines with increasing problem hardness and that certain algorithmic categories (e.g., dynamic programming) remain challenging. The LeetCode-Q dataset, while enabling standardized evaluation, is acknowledged to be unrepresentative of real-world Q usage, which is dominated by database queries and analytics rather than algorithmic problem solving. The authors note that pretrained models may provide better general-purpose Q answers than SFT or RL models, which overfit to the Pythonic LeetCode style.
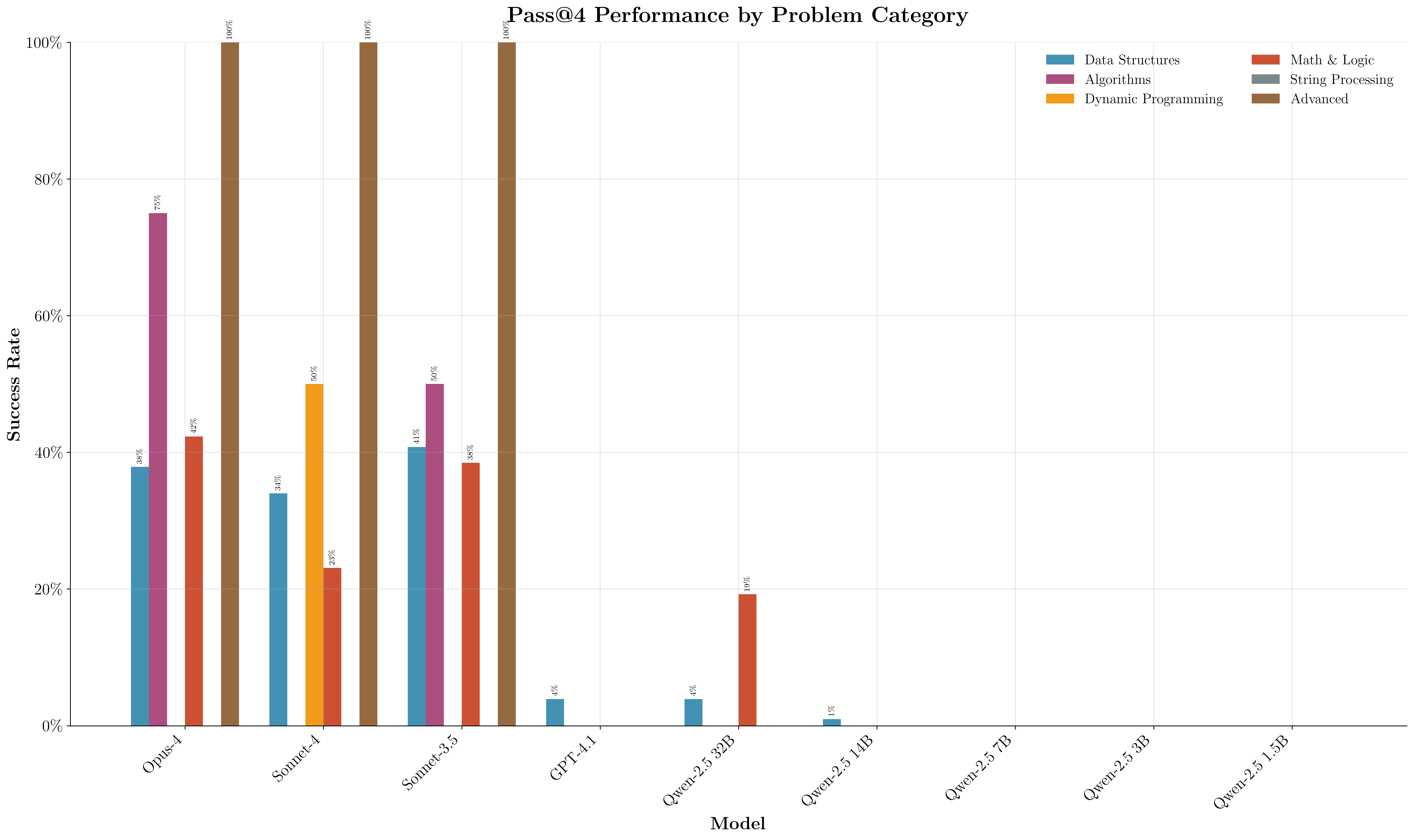
Figure 10: Per-category error distribution, highlighting which problem types require further adaptation.
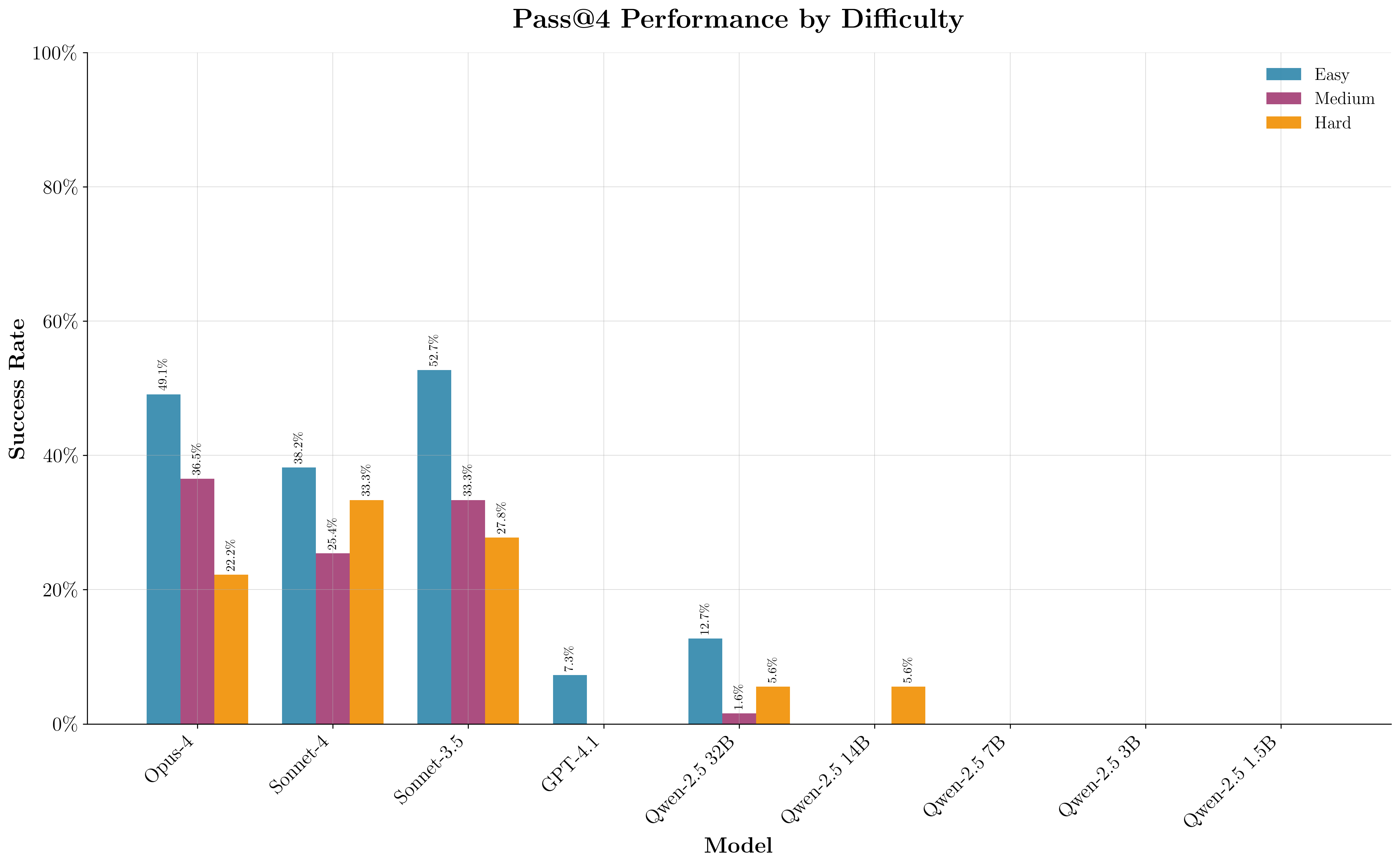
Figure 11: Error breakdown by problem difficulty, showing declining accuracy on harder problems.
Practical Implications and Future Directions
The report provides a reproducible, open-source blueprint for LLM specialization in low-resource domains, emphasizing the criticality of robust evaluation, data quality, and scalable infrastructure. The methodology is broadly applicable to other niche languages and domains with verifiable evaluation criteria. The findings underscore that large model capacity (≥14B) is essential for meaningful domain adaptation, and that RL can further boost performance when reward signals are well-defined.
For Q practitioners, the released models and codebase offer a foundation for further adaptation, especially as more representative datasets become available. For the broader LLM community, the work demonstrates that with careful engineering, even highly specialized domains can be effectively addressed by open-source models.
Conclusion
This work establishes a rigorous, end-to-end methodology for adapting LLMs to specialized programming languages with limited public data. Through systematic dataset construction, benchmarking, domain-adaptive pretraining, SFT, and RL, the authors achieve state-of-the-art performance on Q code generation, surpassing leading closed-source models. The open-source release of models, code, and evaluation tools provides a valuable resource for both Q practitioners and the wider research community. Future work should focus on developing benchmarks and datasets that more faithfully reflect real-world Q usage, as well as extending the methodology to other underrepresented domains.