- The paper presents a novel VAD pipeline that integrates noise-removal pre-processing and majority voting post-processing to improve detection in challenging environments.
- The methodology employs spectral subtraction, energy gating, and RMS normalization to clean the audio input without increasing model size or needing additional fine-tuning.
- Experimental evaluations demonstrate an 84.7% detection accuracy on the AVA dataset, indicating significant performance gains over baseline models.
Tiny Noise-Robust Voice Activity Detector for Voice Assistants
Introduction
The paper "Tiny Noise-Robust Voice Activity Detector for Voice Assistants" (2507.22157) addresses the persistent challenge of accurately detecting voice activity in the presence of background noise. This task, known as Voice Activity Detection (VAD), is pivotal for enhancing the performance of speech processing systems such as automatic speech recognition, especially in devices with computational constraints like AIoT devices. The authors propose a novel approach incorporating both pre-processing and post-processing modules to augment a lightweight VAD model, thereby significantly enhancing its performance in noisy environments without enlarging the model size or requiring further fine-tuning.
Background and Approach
Historical methods for VAD have evolved from classical signal processing techniques that leverage simple features, to modern deep learning approaches that excel in noisy conditions. However, these latter models are typically too large for deployment on edge devices, necessitating an interest in lightweight VAD systems. The method proposed in the paper combines a pre-trained lightweight VAD model, SGVAD, with additional pre-processing and post-processing modules to enhance its robustness against background noise.
Proposed Pipeline
The authors introduce a robust VAD pipeline comprising multiple stages for processing audio signals. This includes segmentation of the input, noise-removal pre-processing techniques like spectral subtraction and energy gating, and a majority-voting-based post-processing method.
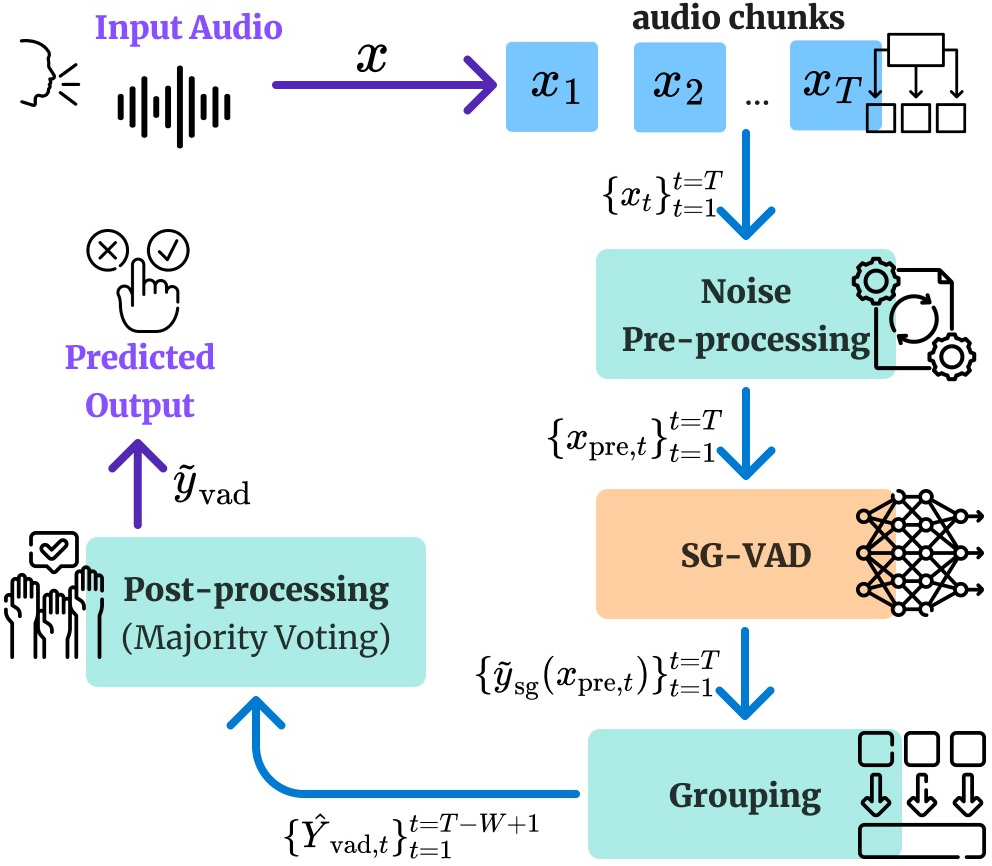
Figure 1: Block diagram of the proposed VAD pipeline, including segmentation, noise-removal pre-processing, inference with SGVAD, sliding-window grouping, and post-processing using majority voting.
Pre-Processing
The pre-processing module involves three techniques aimed at augmenting signal clarity before analysis by the VAD:
- Spectral Subtraction: This technique estimates and subtracts the power spectrum of background noise to yield a clearer signal representation, implemented to counteract stationary noises.
- Energy Gating: By examining short-time energy across frames, this method filters out segments falling below a certain energy threshold, typically identifying non-speech regions.
- RMS Normalization: This process scales audio signals to a fixed RMS level, accounting for dynamic range discrepancies and improving the effectiveness of subsequent energy-based decision mechanisms.
Post-Processing
The post-processing module employs a majority voting technique to enhance decision reliability. Grouping predictions over a sliding window allows the method to accommodate scenarios with intermittent speech, which is common in real-life applications involving voice assistants.
Experimental Evaluation
The paper presents a rigorous assessment of the proposed VAD system across multiple datasets, including AVA Speech, VBD, ESC50, and MS-SNSD. Through these evaluations, the proposed model exhibits superior performance, particularly in detecting noisy speech compared to existing SGVAD and other baseline models.
- Detection Accuracy: The proposed method demonstrated significant gains in speech detection accuracy, particularly for noisy speech (84.7% in the AVA dataset compared to 45.4% for the baseline).
- ROC Analysis: The ROC curves illustrate a lower false positive rate at high true positive rates for the proposed model, indicating its robustness in differentiating speech from noise effectively.
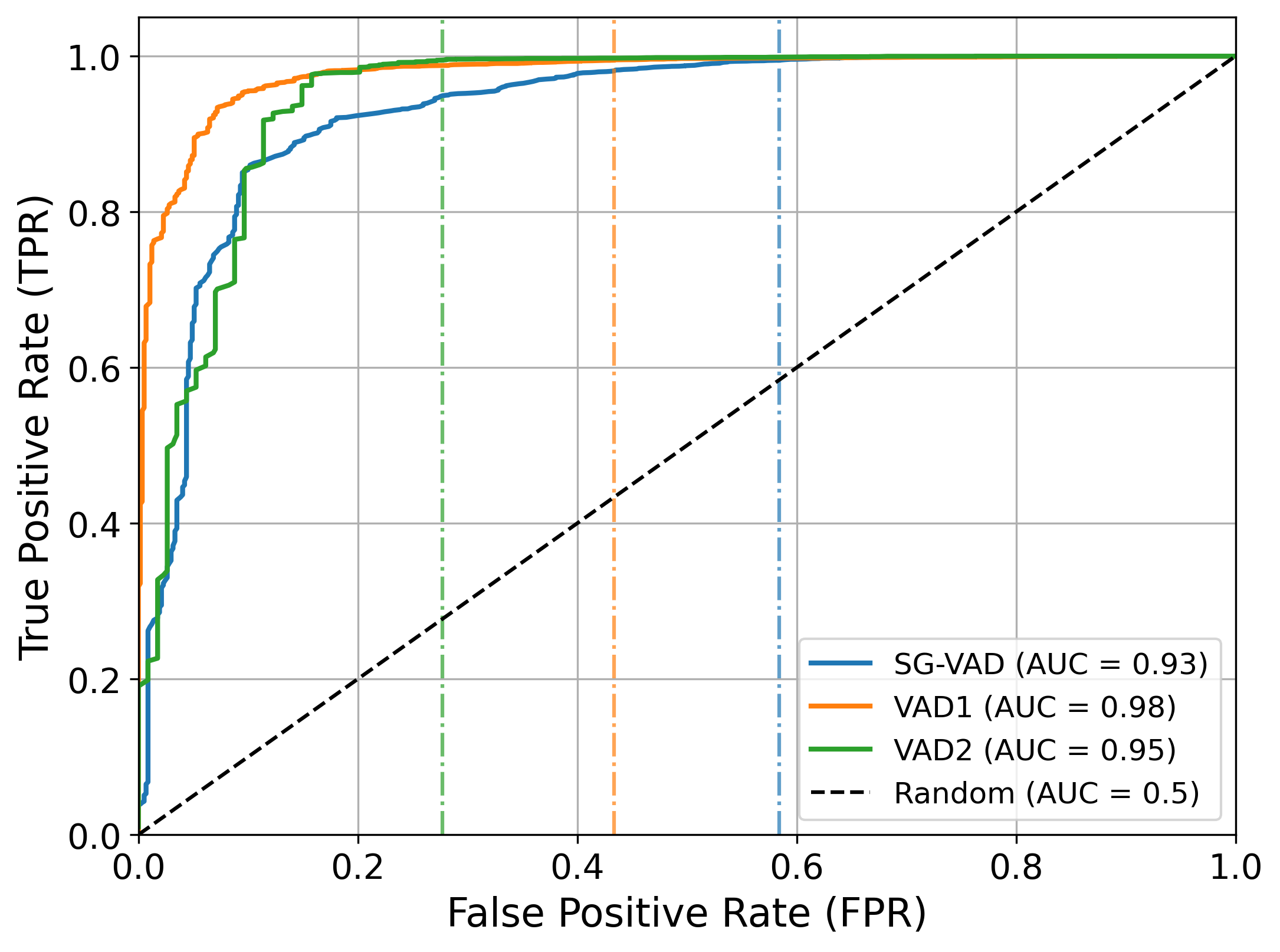
Figure 2: ROC curves for SGVAD (baseline), VAD 1 (with post-processing), and VAD 2 (with post-processing and pre-processing), demonstrating superior performance of VAD 2 in noise-saturated environments.
Conclusion
The paper effectively showcases a novel VAD model design tailored to overcome the challenges of detecting human voice within noisy settings, without compromising computational efficiency. By leveraging state-of-the-art pre- and post-processing strategies, this model achieves marked improvements in detecting not only clean but also noisy speech, paving the way for efficient deployment in resource-constrained, real-world environments. Such advancements enhance practical voice assistant technology and broaden the application scope for intelligent audio analysis systems.