- The paper presents Music Arena as a live evaluation platform for text-to-music models, using real-time, pairwise user preference battles.
- It employs a modular architecture with a Gradio frontend, LLM-powered prompt routing, and Dockerized model endpoints to unify diverse system interfaces.
- Renewable data releases, privacy-preserving logging, and a Bradley-Terry-based leaderboard provide rigorous, reproducible evaluation metrics and ethical oversight.
Music Arena: A Live Evaluation Platform for Text-to-Music Generation
Introduction
The paper introduces Music Arena, an open, web-based platform for scalable, live human preference evaluation of text-to-music (TTM) models. The motivation stems from the inadequacy of current TTM evaluation protocols, which are often inconsistent, expensive, and lack renewable, open human preference data. Music Arena addresses these challenges by leveraging a live evaluation paradigm, where real-world users submit text prompts, listen to outputs from two TTM systems, and express their preferences. The platform is designed with music-specific features, including an LLM-based routing system to handle heterogeneous model interfaces and the collection of detailed user interaction data. The system also emphasizes privacy, transparency, and renewable data releases, aiming to provide a rigorous, standardized, and open evaluation protocol for the TTM research community.
System Architecture and Data Lifecycle
Music Arena's architecture consists of three modular components: a Gradio-based frontend, a backend orchestrator, and a set of model endpoints. The frontend provides a unified interface for users to submit prompts and compare model outputs. The backend manages prompt processing, model selection, audio delivery, and data logging. Model endpoints encapsulate the diverse TTM systems, each within a Docker container to handle dependency isolation and interface unification.
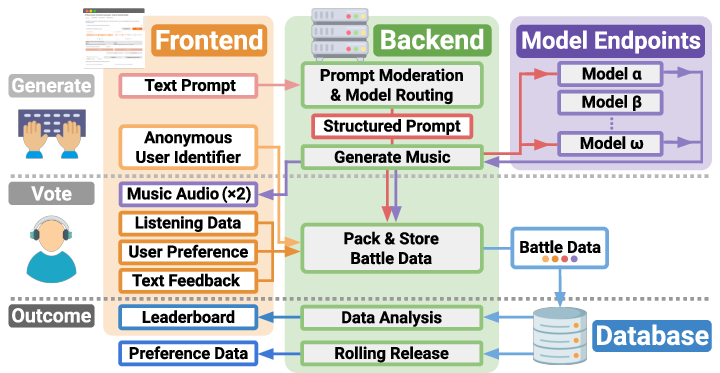
Figure 1: The Music Arena data lifecycle, illustrating user engagement, backend orchestration, model endpoint routing, and data storage for leaderboard compilation and public release.
The data lifecycle begins with user-initiated "battles," where a prompt is submitted and routed to two compatible TTM models. The backend ensures simultaneous delivery of generated audio to mitigate bias from inference speed. User preferences, listening behaviors, and optional natural language feedback are logged and stored in a database. This data is periodically released to the public, supporting leaderboard updates and enabling external research.
User Interaction and Data Collection
The user experience is structured around pairwise "battles." Upon providing informed consent, users submit a text prompt, receive two audio outputs, and are required to listen to each for a minimum duration before voting. The interface conceals audio length to reduce bias and offers four voting options: prefer A, prefer B, tie, or both bad. After voting, model identities and generation speeds are revealed, and users are incentivized to provide additional feedback.
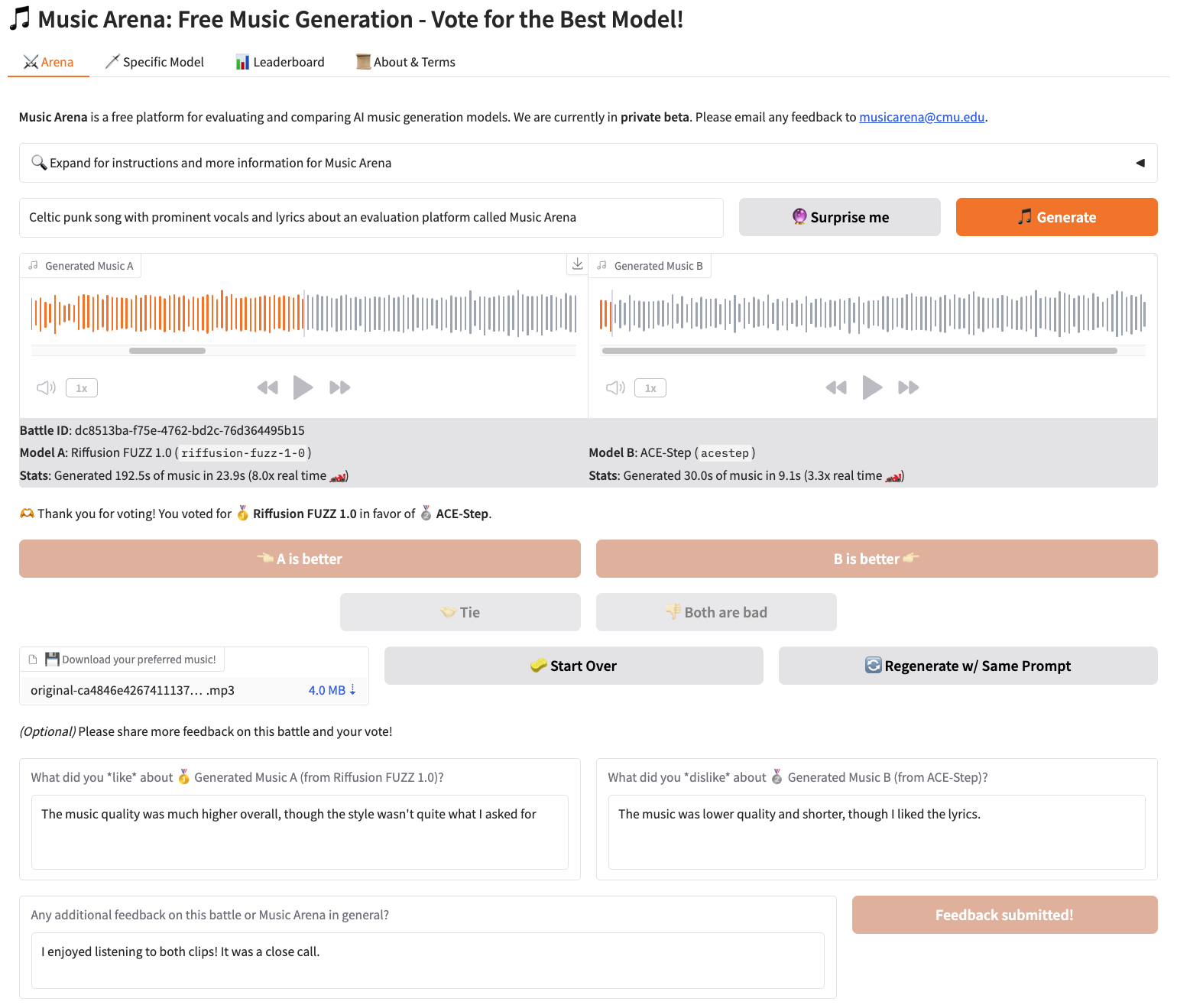
Figure 2: An example of a completed user battle in the Music Arena frontend, showing the interface for prompt submission, audio comparison, and preference selection.
The platform collects fine-grained listening data, including playback and pause timestamps, to analyze user engagement. This is complemented by optional natural language feedback, which provides qualitative insights into user preferences. The combination of quantitative and qualitative data supports both leaderboard construction and deeper analysis of model strengths and weaknesses.
Model Endpoint Unification and LLM-Based Routing
A central challenge in TTM evaluation is the heterogeneity of model interfaces. Models differ in their support for vocals, lyrics, output duration, and other control signals. Music Arena addresses this by implementing a unified API for model endpoints, each encapsulated in a Docker container. For open-weight models, endpoints manage GPU resource allocation and batching; for commercial APIs, endpoints translate requests to proprietary formats.
Prompt routing and moderation are handled by an LLM (currently GPT-4o), which parses user prompts to extract structured information (e.g., presence of vocals, explicit duration) and determines model compatibility. The LLM also performs content moderation, rejecting prompts referencing copyrighted material, culturally insensitive themes, or inappropriate content. This ensures that only valid and safe prompts are routed to models, and that user experience is consistent across heterogeneous systems.
Privacy, Transparency, and Data Release Policies
Music Arena implements a pseudonymization protocol using salted hashing to anonymize user identifiers (e.g., IP addresses), enabling record linkage for longitudinal analysis while preserving privacy. The platform is open source, with all code (except for secret keys and production configurations) and data releases made publicly available. Data is released at regular intervals, including anonymized user identifiers, generated audio, and detailed preference logs, subject to model licensing constraints.
This rolling data release policy ensures that the evaluation dataset remains current with evolving models and shifting user preferences. The transparency of the platform and data lifecycle allows for independent auditing and reproducibility of evaluation results.
Leaderboard Construction and Evaluation Metrics
The leaderboard is constructed using pairwise preference data, typically aggregated via the Bradley-Terry model to produce an "Arena Score" for each system. Additional attributes are included to address music-specific considerations: training data provenance and quantity, system license, and generation speed (measured by median real-time factor, RTF). The leaderboard is designed to be sortable and filterable by these attributes, enabling nuanced comparisons based on application-specific requirements.
The inclusion of training data information is particularly salient given the diversity of sources (e.g., licensed stock music, Creative Commons, unspecified provenance) and the legal and ethical implications for generative music systems. Generation speed is also emphasized, as latency is a critical factor in creative workflows.
Ethical Considerations
Music Arena is governed by IRB-approved protocols, with explicit informed consent, privacy safeguards, and LLM-based content moderation. The platform surfaces training data information to inform ethical and legal assessments. The authors acknowledge broader societal implications, including potential impacts on music labor, cultural homogenization, and the risk of bias due to a non-representative user base. The platform's open and auditable nature, combined with the ability to halt live evaluation if necessary, provides mechanisms for ongoing ethical oversight.
Limitations and Future Directions
Current limitations include coarse-grained tracking of user listening behavior (inability to capture seeking within audio), uniform random model pair selection (rather than adaptive strategies), and a focus limited to TTM (excluding symbolic generation and style transfer). The user base is not globally representative, and the sustainability of free access to open-weight models is uncertain.
Future work will address these limitations by refining frontend/backend capabilities, improving pair selection algorithms, leveraging the growing dataset for meta-evaluation of automatic metrics, and integrating live evaluation into creative workflows. The platform will also adapt its evaluation methodology in response to community feedback to maintain rigor and fairness.
Conclusion
Music Arena establishes a standardized, scalable, and transparent protocol for human evaluation of text-to-music models. By integrating LLM-based moderation and routing, detailed user interaction logging, and open, renewable data releases, the platform addresses key challenges in TTM evaluation. The system's modular architecture and privacy-preserving policies facilitate broad participation and reproducibility. As TTM models continue to evolve, Music Arena provides a robust foundation for rigorous, real-world evaluation, supporting both academic research and practical deployment of generative music systems.