- The paper introduces JAM, a compact flow-based lyrics-to-song generator offering fine-grained control over word- and phoneme-level timing, style, and duration.
- It leverages a conditional flow-matching framework with token-level duration control to achieve a >99% reduction in post-target audio amplitude and improved training efficiency.
- Iterative Direct Preference Optimization and the new JAME benchmark demonstrate JAM's superiority with leading objective metrics and expert-rated musicality.
JAM: A Tiny Flow-based Song Generator with Fine-grained Controllability and Aesthetic Alignment
Introduction and Motivation
JAM introduces a compact, flow-matching-based architecture for lyrics-to-song generation, targeting the limitations of prior systems in controllability, efficiency, and alignment with human musical preferences. Unlike previous large-scale models (e.g., LeVo, DiffRhythm, ACE-Step), JAM is designed to provide word- and phoneme-level timing control, global and local duration specification, and robust aesthetic alignment, all within a 530M parameter footprint—less than half the size of the next smallest open system. The model is trained and evaluated on a carefully curated dataset, with a new public benchmark (JAME) introduced to standardize evaluation and avoid data contamination.
Model Architecture and Training Pipeline
JAM is built on a conditional flow-matching framework, leveraging a 16-layer LLaMA-style Diffusion Transformer (DiT) backbone. The model operates in the latent space of a VAE, with the encoder from Stable Audio Open and a decoder initialized from DiffRhythm, both kept frozen during JAM training. The system is conditioned on three axes: lyrics (with word/phoneme-level timing), style (audio or text prompt), and duration (global and token-level).
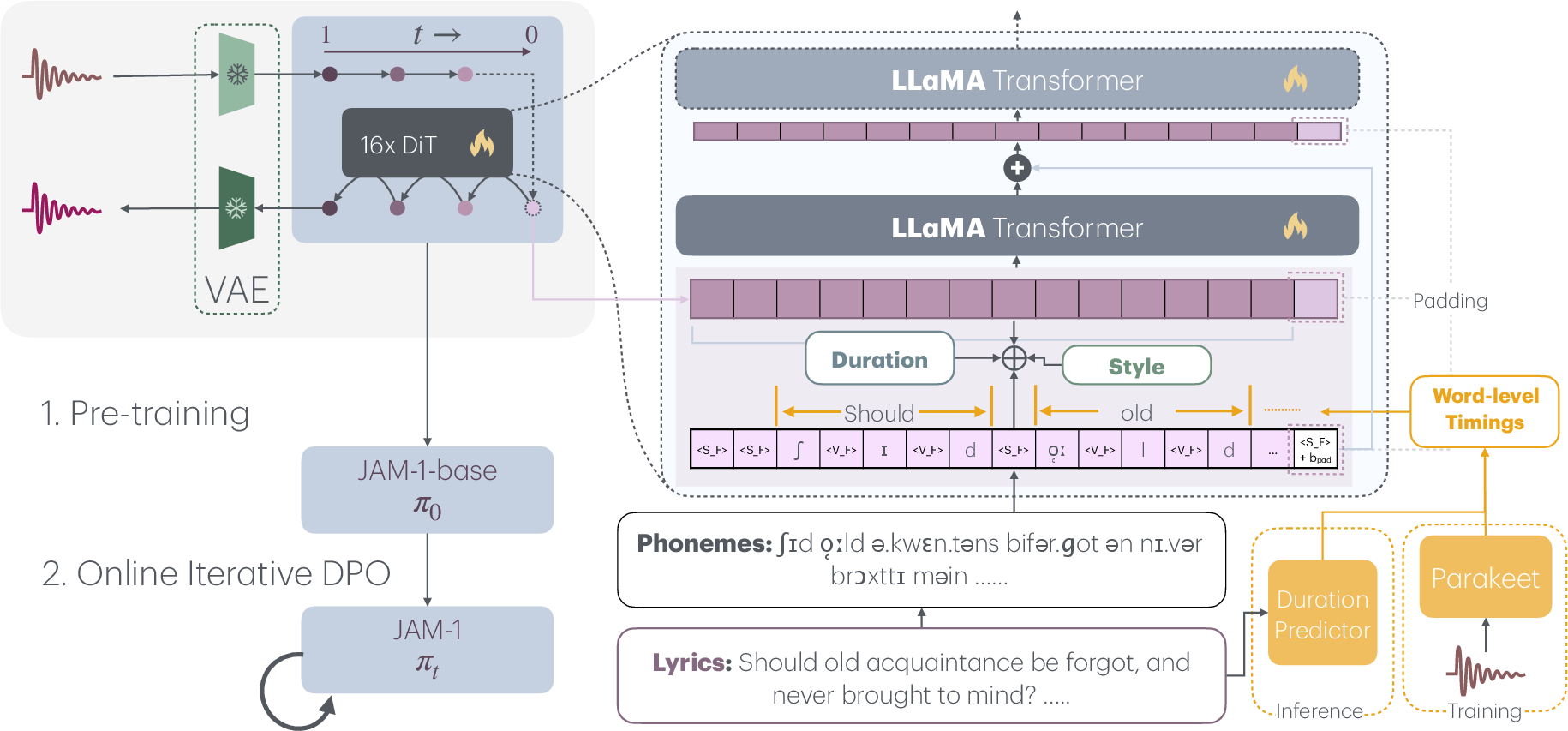
Figure 1: A depiction of the JAM architecture and training pipeline, highlighting the integration of lyric, style, and duration conditioning into the flow-matching generative process.
The training pipeline consists of:
Conditioning and Fine-grained Control
Lyric and Temporal Conditioning
JAM accepts lyrics annotated with word-level start and end times, which are converted to phoneme sequences using DeepPhonemizer and upsampled to match the latent sequence length. This enables precise alignment of generated vocals with the intended prosody and rhythm. The conditioning pipeline fuses lyric, style, and duration embeddings with the latent representation, with additional residual injections in the first half of the transformer layers to strengthen supervision.
Duration Control
JAM implements both global and token-level duration control. Global duration is encoded as a single embedding, while token-level control is achieved by adding a learnable bias to padding tokens beyond the target duration, ensuring silence and preventing content spillover. Ablation studies demonstrate that token-level duration control yields a >99% reduction in post-target audio amplitude, compared to models without this mechanism.
Style Conditioning
Style is encoded via MuQMulan embeddings, supporting both reference audio and text prompts. Classifier-free guidance (CFG) is used during inference to balance the influence of style and lyric conditions.
Flow Matching and Inference
JAM employs rectified flow matching, directly regressing the velocity field that transports noise to the target latent distribution. This approach offers improved training stability and sample efficiency over score-based diffusion. Inference is performed by integrating the learned ODE using an Euler solver, with multi-condition CFG applied to modulate the influence of each conditioning axis.
Aesthetic Alignment via Direct Preference Optimization
To address the gap between technical fidelity and human musical preference, JAM applies DPO in multiple rounds, using SongEval as the reward signal. This process iteratively refines the model to align with synthetic aesthetic preferences, without requiring manual annotation. A variant of the DPO loss incorporates a ground-truth reconstruction term to regularize against over-alignment and preserve stylistic fidelity.
Evaluation and Results
Objective Evaluation
JAM is evaluated on JAME, a new public benchmark comprising 250 post-training-cutoff tracks across five genres. Metrics include WER, PER, MuQ-MuLan similarity, genre classification accuracy, FAD, and SongEval/Audiobox-aesthetic scores.
Key results:
- WER: 0.151 (lowest among all models; >3× improvement over DiffRhythm)
- PER: 0.101 (lowest)
- MuQ-MuLan: 0.759 (highest)
- Genre Accuracy: 0.704 (highest)
- FAD: 0.204 (lowest)
- SongEval/Audiobox-aesthetic: JAM leads or is competitive across all sub-metrics.
JAM achieves these results with the smallest model and dataset among all compared systems.
Subjective Evaluation
Eight expert annotators rated outputs from five models on quality, enjoyment, musicality, voice naturalness, and song structure clarity. JAM is preferred for enjoyment, musicality, and structure clarity, and is competitive in quality and naturalness.
Ablation and Analysis
- Token-level duration control is essential for precise temporal boundaries.
- Phoneme assignment: The "Average Sparse" method, which distributes phonemes evenly within word spans, yields better FAD and SongEval scores than the "Pad Right" method.
- Aesthetic alignment: Iterative DPO rounds consistently improve musicality, enjoyment, and structure, but may slightly increase FAD unless regularized with ground-truth loss.
- Duration prediction: Naive GPT-4o-based timestamp prediction degrades performance, while beat-aligned quantization offers a practical compromise with minimal loss in musicality and intelligibility.
Limitations and Future Directions
JAM's reliance on accurate word-level timing annotations limits usability for non-experts. Inference-time duration prediction remains an open challenge; naive approaches yield robotic outputs, while beat-aligned quantization, though practical, introduces subtle artifacts. Future work should focus on end-to-end trainable duration predictors, potentially at the phoneme level, to enhance robustness and accessibility. Additionally, further research is needed to balance aesthetic alignment with distributional fidelity (FAD).
Implications and Outlook
JAM demonstrates that compact, flow-matching-based architectures can achieve state-of-the-art controllability and musicality in lyrics-to-song generation, provided that fine-grained temporal and stylistic conditioning is available. The introduction of JAME as a public benchmark sets a new standard for transparent, genre-diverse evaluation. The iterative DPO-based aesthetic alignment pipeline, leveraging synthetic preference signals, is shown to be effective and scalable.
Practically, JAM enables professional users to generate highly controllable, musically aligned songs from lyrics, with explicit control over timing, style, and structure. The model's efficiency and open-source release facilitate broader adoption and further research. Theoretically, the work highlights the importance of integrating temporal, structural, and aesthetic supervision in generative music models, and points toward the need for robust, learnable duration prediction modules.
Conclusion
JAM advances the state of lyrics-to-song generation by combining a compact flow-matching architecture with fine-grained temporal and stylistic control, and by introducing a scalable, preference-aligned training pipeline. The model achieves strong objective and subjective results, setting a new baseline for controllable, high-fidelity song generation. Future work on integrated duration prediction and phoneme-level control will further enhance the model's robustness and usability for both expert and non-expert users.