- The paper presents CodeReasoner, which integrates a novel dataset construction technique with a two-stage training pipeline of instruction tuning and GRPO-based reinforcement learning.
- It demonstrates significant performance gains on code execution simulation tasks, outperforming both open-source and proprietary baselines in small and medium models.
- The approach reduces overthinking and verbosity while enhancing model generalization across diverse architectures, making it effective for debugging, code generation, and program repair.
CodeReasoner: Enhancing Code Reasoning in LLMs with Reinforcement Learning
Introduction
The paper introduces CodeReasoner, a framework designed to improve the code reasoning capabilities of LLMs, particularly in small and medium parameter regimes. Code reasoning, defined as the ability to understand and predict program execution behavior, is critical for downstream tasks such as debugging, code generation, and program repair. The authors identify two primary limitations in existing approaches: (1) the prevalence of low-quality, boilerplate-heavy training data, and (2) the limited generalization of models trained solely via supervised fine-tuning (SFT). To address these, CodeReasoner combines a novel dataset construction methodology with a two-stage training pipeline: instruction tuning followed by reinforcement learning using Group-relative Policy Optimization (GRPO).
Analysis of LLM Failures in Code Reasoning
The authors conduct a detailed error analysis on the Qwen2.5-7B model using the Cruxeval benchmark. They find that most failures occur during the execution simulation phase, not code comprehension. LLMs often mismanage state tracking, especially with complex data structures or control flow, due to their reliance on statistical patterns rather than explicit execution traces.

Figure 1: A motivating example from Cruxeval where the LLM comprehends code but fails in execution simulation, mispredicting the output due to incorrect state tracking.
This analysis underscores the necessity for training data and objectives that directly target execution simulation, rather than merely code comprehension or generation.
Limitations of Existing Datasets
Current code reasoning datasets, such as those used in SEMCODER and CODEI/O, are often constructed by expanding real-world code snippets into full programs, resulting in excessive boilerplate and superficial complexity.

Figure 2: Example from PXY-R showing that boilerplate code (in red) adds unnecessary complexity, obscuring the core logic relevant for reasoning.
Such datasets fail to provide strong training signals for execution simulation, as the core reasoning challenge is often trivialized by the surrounding scaffolding.
CodeReasoner Framework
Dataset Construction
The dataset construction process is algorithmically controlled to ensure conciseness, comprehensiveness, controllability, and varied difficulty. The process iterates over Python built-in types and methods, applying constraints on method calls, control structures, and input mutations. Each generated test case is validated by execution, and only concise, valid cases are retained.

Figure 3: Example test case from the constructed dataset, demonstrating improved conciseness and focus on execution logic compared to prior work.
This approach yields a dataset that is both diverse and directly targeted at the core challenges of code execution reasoning.
Two-Stage Training: Instruction Tuning and Reinforcement Learning
Instruction Tuning
Instruction tuning is performed using chain-of-thought (CoT) traces distilled from a strong teacher model (QwQ-32B). Both forward (input-to-output) and backward (output-to-input) reasoning tasks are included. Rejection sampling ensures only valid, executable reasoning traces are used. This stage injects domain-specific reasoning patterns into the student model, which is essential for subsequent RL.
Reinforcement Learning with GRPO
The second stage applies GRPO, a memory-efficient RL algorithm that optimizes for concise, correct reasoning chains. The reward function is binary, granting positive reward only for correct, non-verbose answers. GRPO operates by generating multiple candidate responses per prompt, scoring them, and updating the policy based on group-relative advantages, with KL regularization to stabilize training.

Figure 4: Case study demonstrating the effectiveness of the two-stage training pipeline, with clear improvements in both forward and backward reasoning after RL.
This RL stage addresses two key issues: (1) it mitigates the tendency of instruction-tuned models to produce overly long or repetitive reasoning chains, and (2) it enhances generalization to unseen reasoning tasks.
Experimental Results
Benchmarks and Baselines
CodeReasoner is evaluated on CRUXEval, LiveCodeBench, and REval, covering both high-level and fine-grained code reasoning tasks. Baselines include state-of-the-art closed-source models (GPT-4o, GPT-4o-mini), large open-source models (Qwen2.5-72B, Llama3-70B), and specialized code reasoning models (SEMCODER, CODEI/O).
- On input/output and output/input prediction tasks, CodeReasoner-7B matches or exceeds GPT-4o-mini and outperforms all open-source baselines, with average improvements of 16.4% over GPT-4o-mini and 32.8% over specialized 7B baselines.
- On fine-grained reasoning tasks (REval), CodeReasoner-7B outperforms similarly sized models by 21.9%–39.6% and even surpasses GPT-4o in several metrics. The 14B variant outperforms GPT-4o on average.
- Ablation studies confirm that both instruction tuning and RL are necessary; RL alone is ineffective without prior domain knowledge, and omitting reasoning chains leads to substantial performance drops.
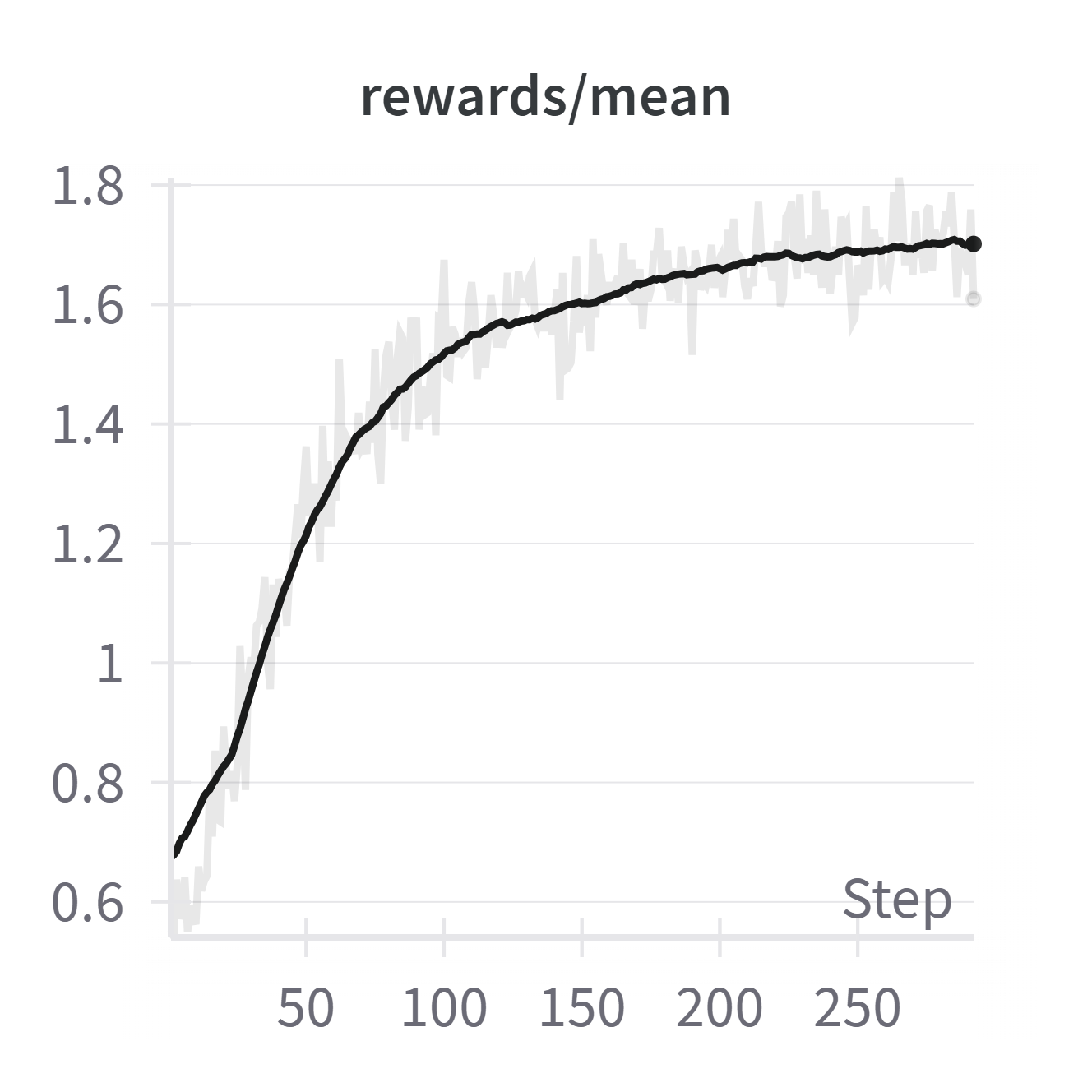
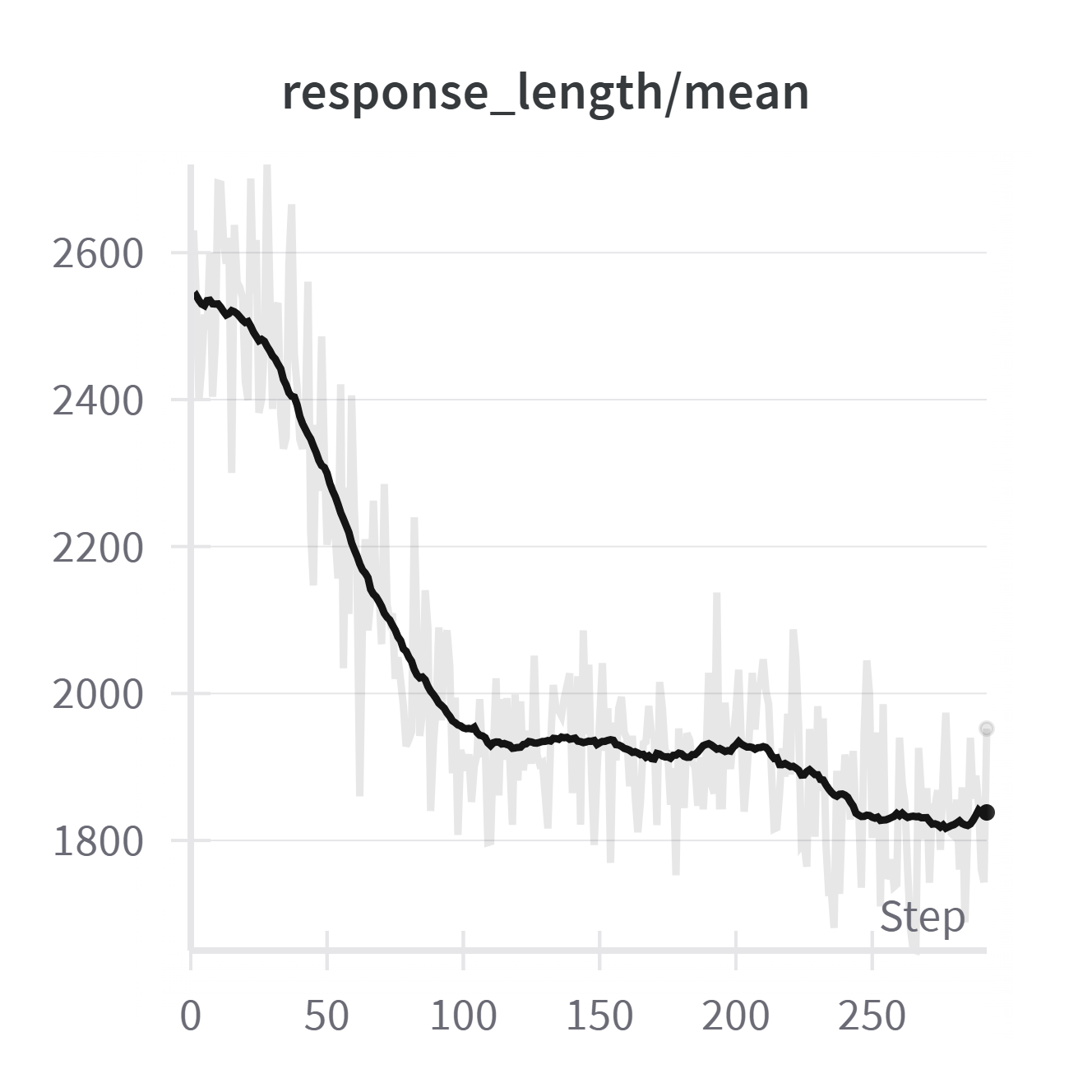
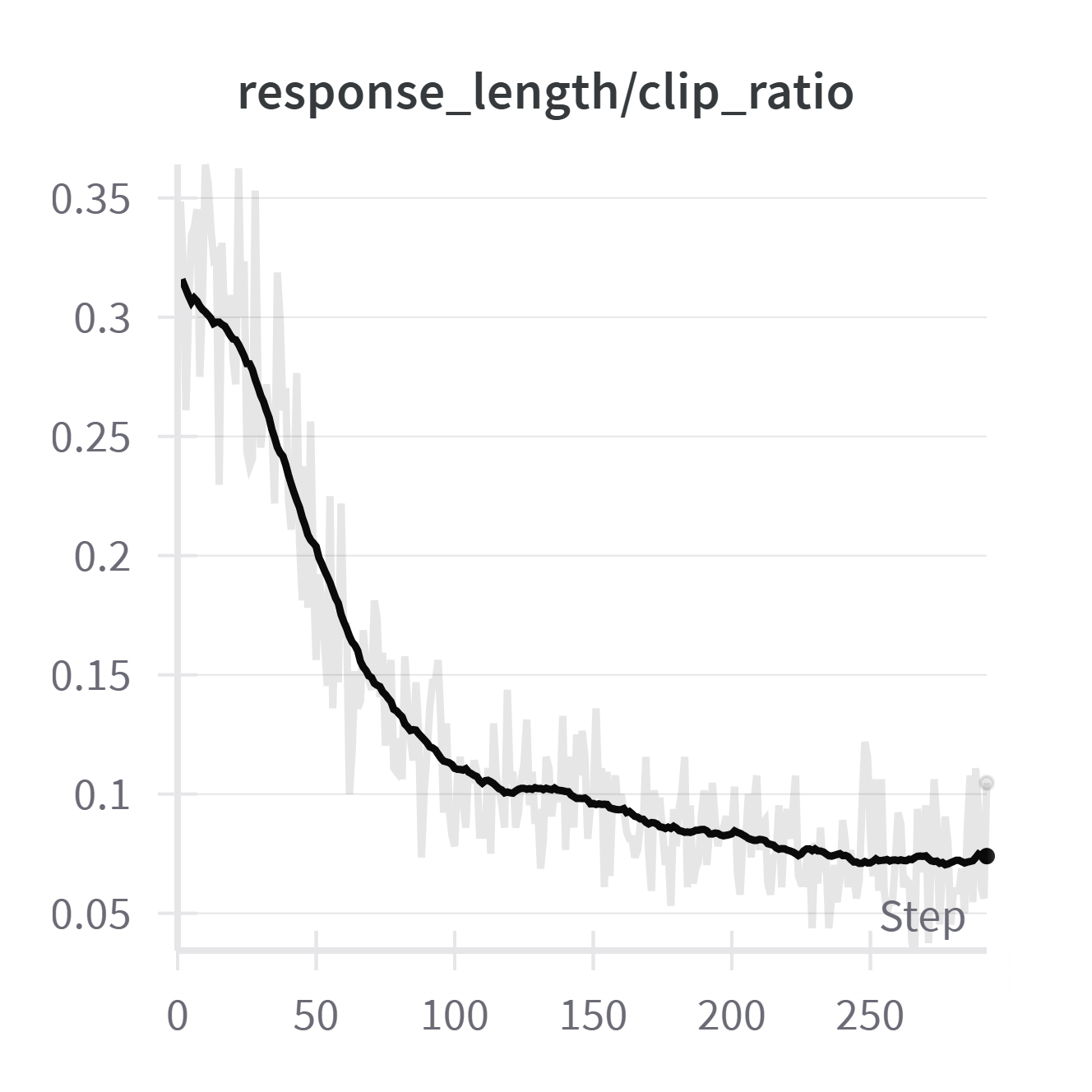
Figure 5: Training dynamics during RL: mean reward increases, average response length decreases, and the clipping ratio (overly long responses) drops, indicating improved conciseness and correctness.
Model Generalization
The framework is shown to be effective across different model architectures (Qwen2.5, Llama3) and sizes (7B, 8B, 14B), with relative improvements of 17.8%–31.0%.
Discussion
The RL stage, particularly with GRPO, is effective at reducing overthinking and verbosity, a problem exacerbated by instruction tuning. Unlike RL in mathematical domains, where response length often increases, here the average response length decreases as the model learns to avoid unnecessary reasoning steps. This is attributed to the task-specific reward structure and the initial tendency of instruction-tuned models to overgenerate.
Implications and Future Directions
Practical Implications
- For practitioners, CodeReasoner demonstrates that small and medium LLMs can achieve code reasoning performance on par with much larger or proprietary models, provided that training data and objectives are carefully designed.
- For tool developers, the approach is directly applicable to building more reliable AI-powered debugging, code review, and program repair assistants, especially in resource-constrained environments.
Theoretical Implications
- The results highlight the limitations of SFT for generalization in code reasoning and the necessity of RL for robust, concise reasoning.
- The findings suggest that dataset construction methodologies that focus on execution logic, rather than code structure, are critical for advancing LLM reasoning capabilities.
Future Work
- Extending the dataset and training pipeline to additional programming languages and multilingual benchmarks.
- Scaling the approach to larger models and more diverse architectures.
- Integrating CodeReasoner into end-to-end developer tools for debugging and automated repair.
Conclusion
CodeReasoner presents a comprehensive solution to the challenges of code reasoning in LLMs, combining principled dataset construction with a two-stage training pipeline. The approach yields substantial improvements over both open-source and proprietary baselines, particularly in small and medium model regimes. The work establishes a new standard for code reasoning evaluation and provides a blueprint for future research in LLM-based software engineering tools.