- The paper introduces a novel flow matching framework that maps visual latent representations directly into action spaces without noise injection.
- It employs an efficient architecture combining a vision encoder, action autoencoder, and an MLP-based flow network to reduce inference latency by up to 130%.
- Experimental results validate VITA's competitive success rates across simulated and real-world tasks, establishing its potential for advanced robotic control.
VITA: Vision-to-Action Flow Matching Policy
The paper introduces VITA, a new framework for visuomotor control that leverages flow matching to map visual latent representations to action latent spaces. It presents a novel approach where latent images become the flow source, eliminating the inefficiencies associated with conventional conditioning mechanisms. The paper outlines several key components of VITA: an action autoencoder for dimensional matching and a straightforward ML paradigm using only MLP. Experimental results demonstrate its competitive performance across various simulated and real-world tasks, underlining its efficiency and state-of-the-art success rates.
Flow Matching from Vision to Action
VITA's core concept is to adapt flow matching for direct transformation between visual and action latents without noise injection (Figure 1). Traditional policies require Gaussian noise and extra conditioning modules to bridge the vision-action gap. VITA utilizes latent visual representations directly as the source distribution in flow matching, resolving constraints by learning action latencies that match visual dimensions. During inference, this process results in efficient, precise action prediction.
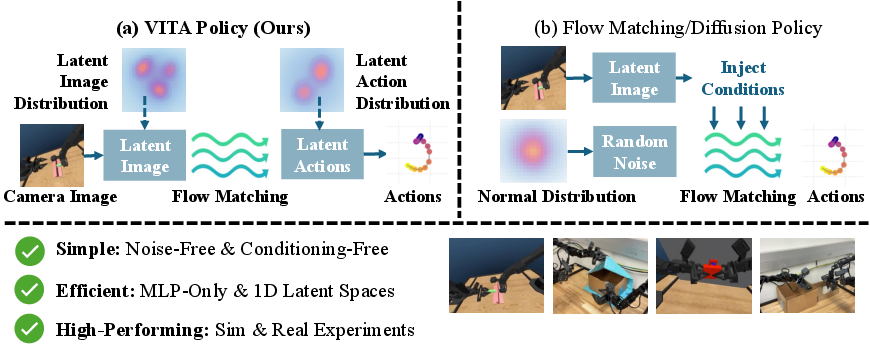
Figure 1: An overview of VITAâa noise-free, conditioning-free policy learning framework, achieving strong performance and inference efficiency across both simulation and real-world visuomotor tasks.
Efficient Policy Architecture
The VITA architecture (Figure 2) consists of simplified components: a vision encoder, action encoder-decoder, and flow matching network. The vision encoder maps observations to a 512-dimensional latent representation. The action autoencoder up-samples actions into corresponding latent dimensions, ensuring shape compatibility. The MLP-based flow network then learns the optimal velocity field to transform the latent vision into action via the learned ODE.
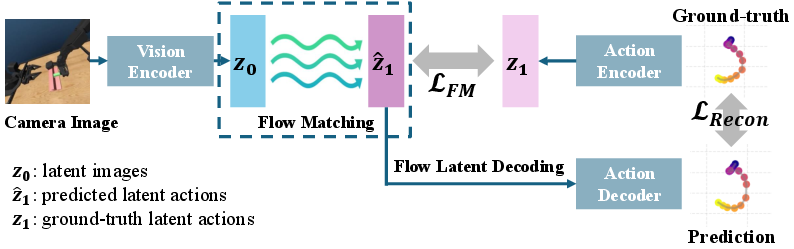
Figure 2: An overview of the VITA architecture, facilitating efficient representation translation through streamlined neural architecture components.
VITA's implementation emphasizes simplicity and efficiency. VITA combines lightweight encoders with MLP flow networks for lower computational overhead. This architecture allows VITA to reduce policy inference latency by 50% to 130% compared to traditional generative models (Table 1). It demonstrated state-of-the-art results in simulated ALOHA tasks and competitive performance in real-world settings, evidencing the effectiveness of its end-to-end flow latent decoding.
Experimental Evaluation
VITA was rigorously evaluated against state-of-the-art models across six simulation tasks and two real-world tasks. Simulation metrics illustrated VITA's superior or equivalent success rates compared to diffusion and autoregressive competitors (Table 2). The results highlight VITA's ability to efficiently learn viable policies in both simulated and operational environments, facilitated by its compact architecture (Figures 3 and 4).
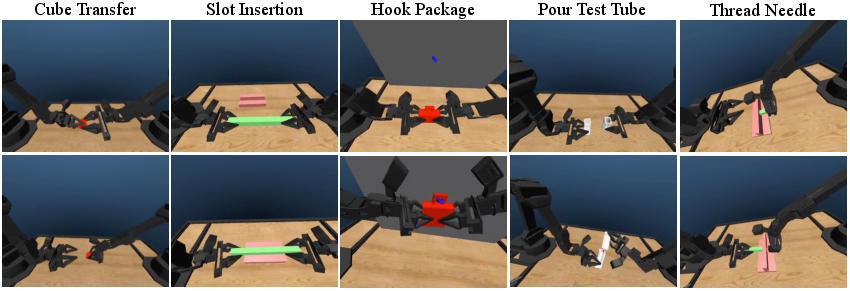
Figure 3: An illustration of five simulation AV-ALOHA tasks, CubeTransfer, SlotInsertion, HookPackage, PourTestTube, and ThreadNeedle.

Figure 4: An illustration of two challenging real-world AV-ALOHA tasks, HiddenPick, and TransferFromBox. The pictures are taken from autonomous rollouts by the VITA policy.
Ablation and Analysis of Flow Latent Decoding
A key innovation in VITA is the backpropagation of flow latent decoding. This allows end-to-end joint optimization of the vision and action latent spaces. The critical flow decoding loss (Figure 5) demonstrated its necessity for successful policy training, as ablations show a dramatic performance drop without it. The policy reaches optimal success rates through effective coupling of learned visions to executable actions.
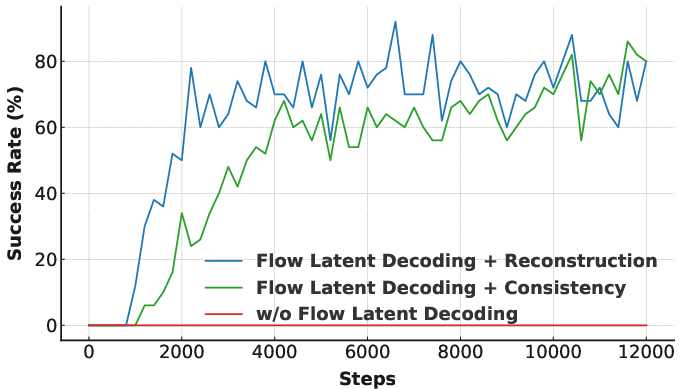
Figure 5: Ablation study on flow latent decoding, comparing different objective functions for supervising the predicted action latent.
Conclusion
VITA illustrates a substantial advancement in efficient, generative visuomotor policies. By effectively leveraging latent space matching and eliminating the need for complex conditioning modules, it sets a precedent for high-performance policy deployment with minimal inference latency. The framework's approaches can serve as a blueprint for future developments in both simulated and real-world robot manipulation tasks.

