- The paper presents a novel grid-based method that leverages LMMs to integrate map excerpts and textual analysis for improved georeferencing.
- The methodology combines NER, gazetteer querying, and multi-modal reasoning, resulting in reduced distance errors compared to baselines.
- Experimental results on natural history datasets demonstrate enhanced spatial reasoning capabilities, though challenges with linear features persist.
Large Multi-modal Model Cartographic Map Comprehension for Textual Locality Georeferencing
Introduction
The paper "Large Multi-modal Model Cartographic Map Comprehension for Textual Locality Georeferencing" explores a novel approach that enhances georeferencing methods by leveraging Large Multi-modal Models (LMMs). The authors underscore the challenges faced by natural history collections in georeferencing their archived data, which predominantly relies on complex locality descriptions rather than precise coordinates. These descriptions often involve relative spatial relations that are difficult to interpret and automate using traditional methods. The paper proposes using LMMs to integrate map comprehension with textual processing, suggesting an innovative grid-based approach to address this task in a zero-shot setting.
Methodology
The authors introduce an intricate workflow aimed at achieving accurate georeferencing of locality descriptions by incorporating LMM capabilities. This workflow includes several key modules that systematically parse, analyze, and predict geographic locations from textual data.
Textual Information Parsing
Initially, the process identifies and extracts named entities (place names) and spatial relationships from the descriptions. Named Entity Recognition (NER) tools, both off-the-shelf and custom-trained models, play a crucial role in detecting these entities. Advanced techniques such as coreference resolution are employed to handle multiple references to the same place within the text.
The next stage involves querying gazetteers and geospatial databases to obtain authoritative geometric representations of the extracted place names. By leveraging diverse sources such as OpenStreetMap and GeoNames, the framework ensures comprehensive coverage and resolves ambiguities in place identification.
Map Generation
A map excerpt is generated based on the disambiguated features, ensuring it contains all necessary landmarks but is not overly coarse. The excerpt overlays a labeled grid that facilitates LMM predictions by defining spatial extents that can be computationally related to the described locations.
Multi-modal Georeferencer
At the core of this framework, an LMM utilizes both the textual description and the gridded map to predict the grid cell most likely to represent the described location. Several prompting designs were explored, with a Logical Chain-of-thought approach ultimately proving most effective for guiding the LMM's reasoning process.
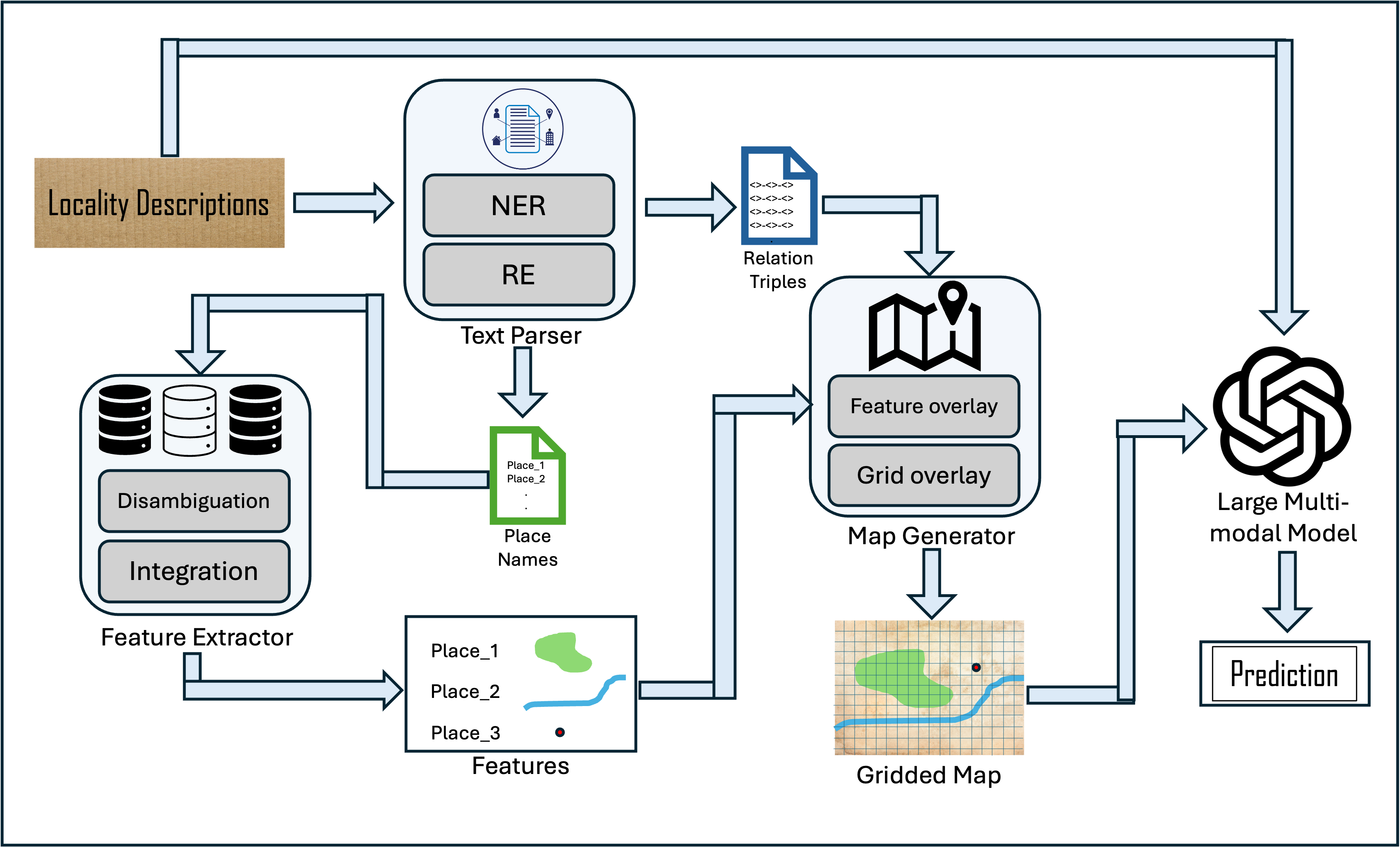
Figure 1: Workflow of the complete automated georeferencing process.
Experimental Results
To evaluate the proposed method, the authors conducted experiments using manually annotated data from natural history collections, specifically floral specimens in New Zealand. Their dataset incorporated grid-labeled map snippets generated from the chosen gazetteers.
Compared against baselines such as GEOLocate and various LLM approaches, the LMM-based method achieved superior results. Distance errors were reduced substantially, demonstrating the LMM's effective integration of map-based spatial reasoning and textual understanding.
(Table \ref{resultsTable})
Table 1: Performance results across different methods, highlighting the effectiveness of the LMM-based approach.
Spatial Understanding
The experiments revealed the LMM's ability to discern spatial extents of features, further supported by its reasoning capabilities. However, challenges remain with linear features, where manual adjustments to map scales improved results.
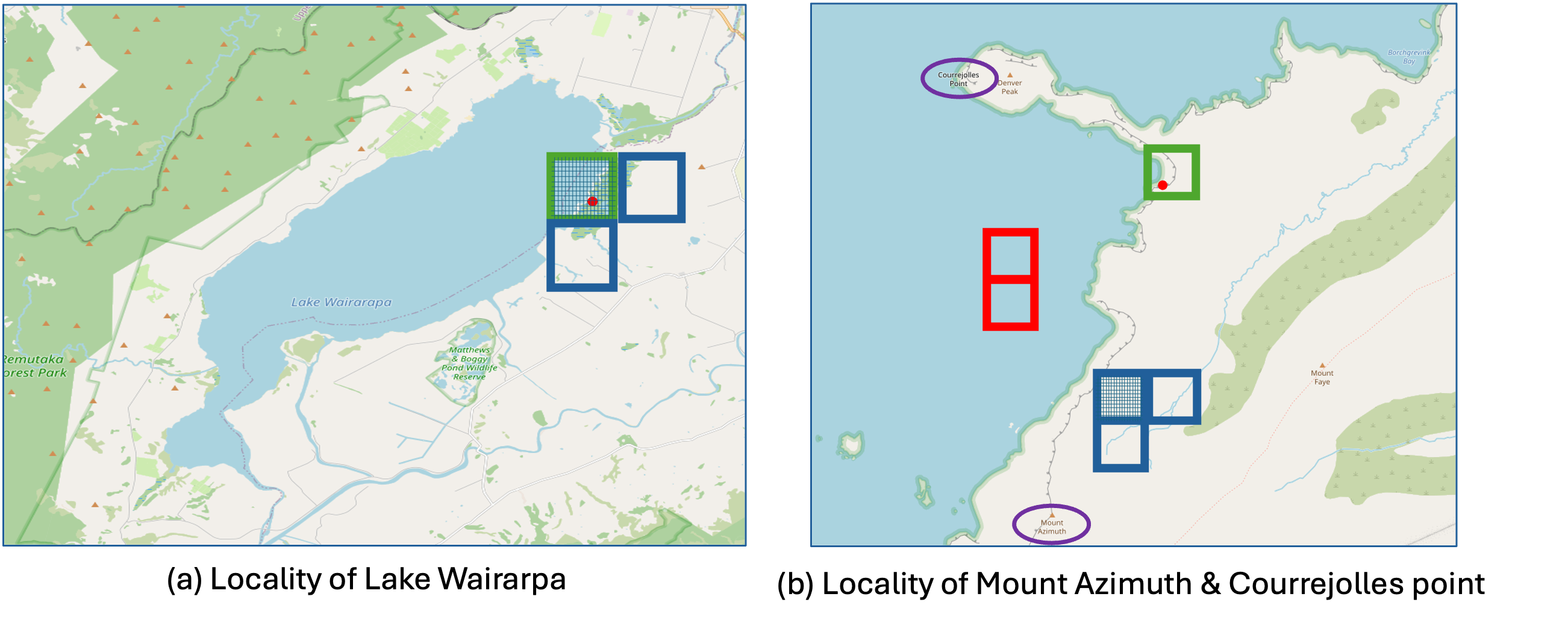
Figure 2: Map excerpts, their labels, and predictions demonstrating terrain-related spatial reasoning.
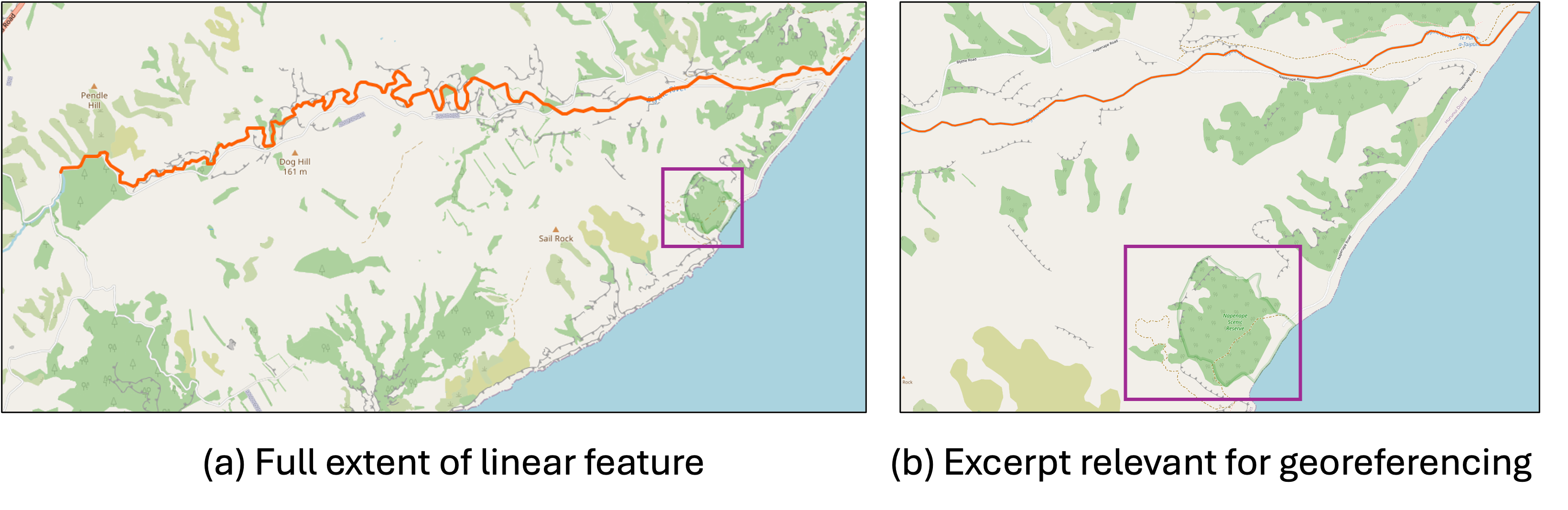
Figure 3: Two map excerpts for the same locality description, illustrating the impact of map granularity on prediction accuracy.
Discussion
This study demonstrates that multi-modal approaches can significantly improve georeferencing tasks by combining language and vision capabilities. The ability to understand terrain and spatial extents, while not perfect, represents a promising step toward automating complex georeferencing tasks.
Potential Improvements
Further enhancements could involve fine-tuning models with large annotated datasets, focusing specifically on map comprehension. These models could learn to interpret complex terrain features and spatial relations more accurately, leveraging the wealth of unstructured locality descriptions available globally.
Conclusion
The paper introduces an innovative georeferencing method using LMMs, showing marked improvements over traditional approaches. It proposes a practical framework to adopt these methods within georeferencing workflows, with implications for advancing GeoAI capabilities. Future research is encouraged to refine these models, potentially employing distantly supervised learning to harness vast archives of locality descriptions for training specialized, map-comprehending models.