- The paper introduces FMSP, a novel algorithm framework that leverages FM-generated code policies for open-ended multi-agent strategy discovery.
- QDSP, a variant of FMSP, innovatively balances quality and diversity using a dimensionless MAP-Elites approach without hand-crafted behavioral descriptors.
- Empirical results in the Car Tag and Gandalf domains show that FMSP variants, especially QDSP, outperform traditional self-play methods by achieving higher QD-Scores.
Foundation Model Self-Play: Open-Ended Strategy Innovation via Foundation Models
Introduction and Motivation
The paper introduces Foundation-Model Self-Play (FMSP), a new family of policy search algorithms that leverage the code-generation and knowledge capabilities of large foundation models (FMs) to drive open-ended strategy discovery in multi-agent settings. Traditional self-play (SP) algorithms have achieved superhuman performance in competitive domains by exploiting the implicit curriculum generated by agents playing against themselves. However, SP is limited by its tendency to converge to local optima and its inability to generate a diverse set of high-quality solutions. FMSP addresses these limitations by using FMs to generate code-based policies, enabling large jumps in policy space and facilitating the discovery of both diverse and high-performing strategies.
FMSP Algorithmic Variants
The FMSP framework is instantiated in three main variants, each inspired by classic search paradigms:
- Vanilla Foundation-Model Self-Play (vFMSP): Maintains a single policy per side and iteratively improves each via FM-driven code generation, analogous to standard self-play but operating at the level of code policies.
- Novelty-Search Self-Play (NSSP): Focuses exclusively on generating a diverse archive of policies, using FMs to propose novel strategies without regard to performance.
- Quality-Diversity Self-Play (QDSP): Integrates the strengths of vFMSP and NSSP, maintaining an archive of policies that are both high-performing and diverse, using a dimensionless MAP-Elites approach where the FM and embedding model define behavioral diversity.
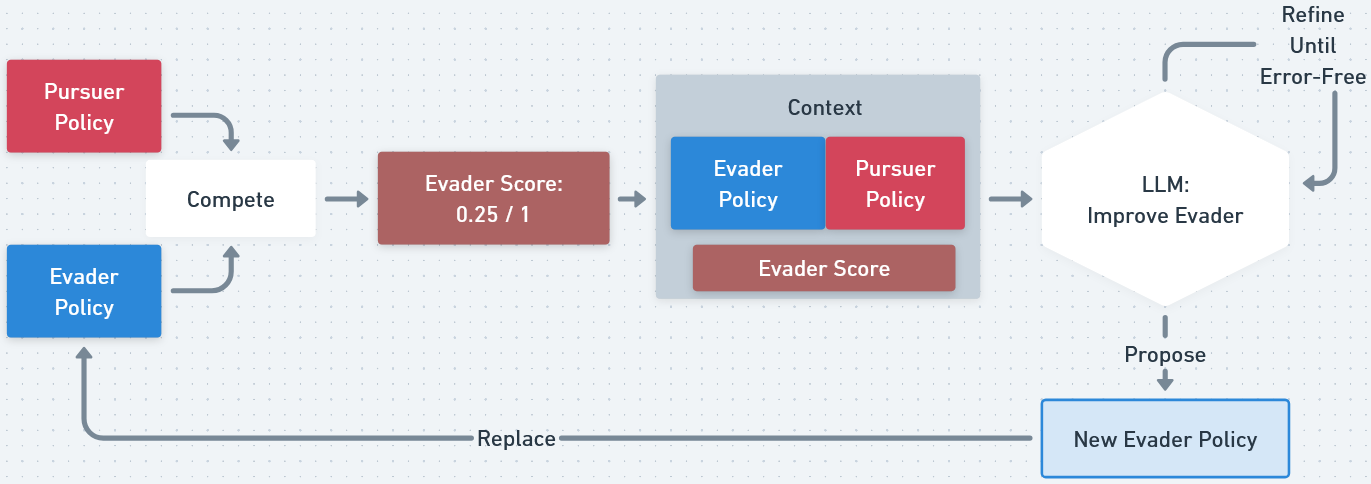
Figure 1: Overview of Vanilla Foundation-Model Self-Play (vFMSP), which iteratively improves code-based policies for each agent via FM-driven policy improvement steps.
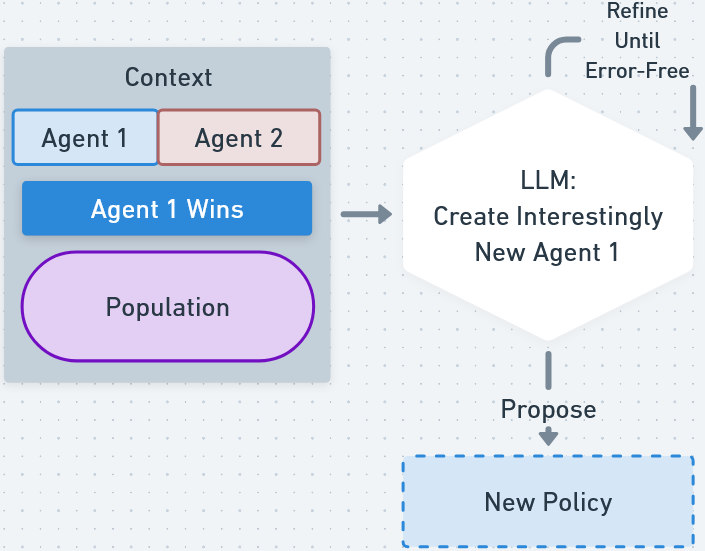
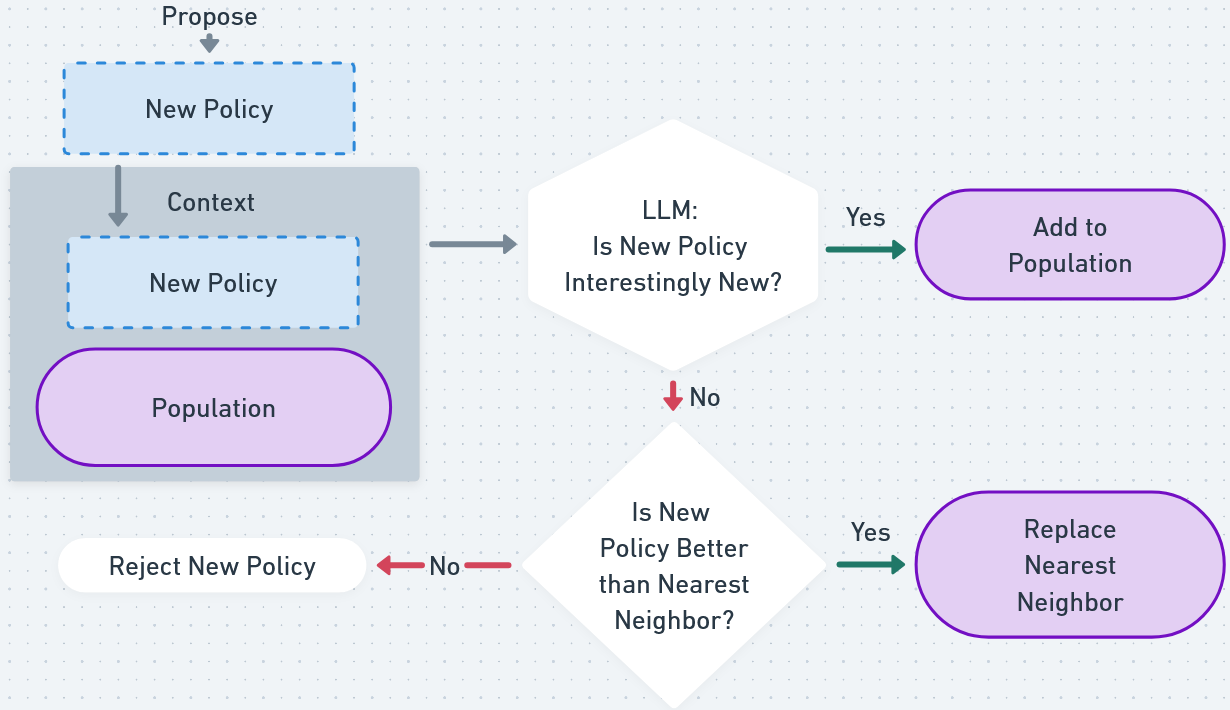
Figure 2: Overview of Quality-Diversity Self-Play (QDSP), which alternates between proposing novel policies and updating an archive to maximize both quality and diversity without predefined behavioral dimensions.
QDSP is particularly notable for being the first MAP-Elites-style algorithm that does not require human-specified behavioral descriptors, instead using FM-generated embeddings to define behavioral diversity in a high-dimensional, open-ended space.
Empirical Evaluation: Car Tag
The Car Tag domain, a continuous-control pursuer-evader game, serves as a testbed for evaluating the exploration and exploitation capabilities of FMSP variants. Each algorithm is seeded with simple human-designed policies and iteratively generates new code-based policies using FMs (GPT-4o for Car Tag). Policies are evaluated in round-robin tournaments, and their quality and diversity are assessed using ELO ratings and QD-Score metrics, respectively.
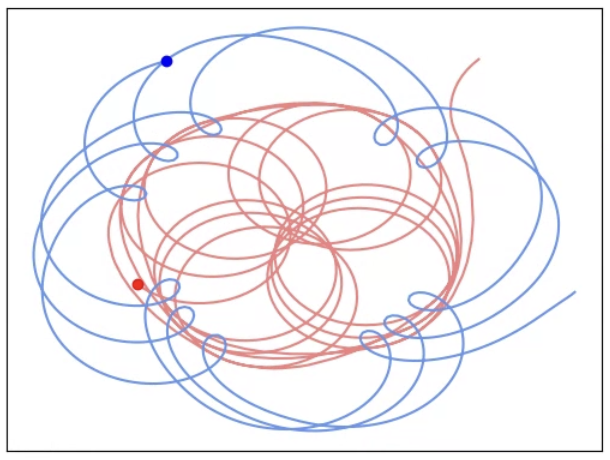

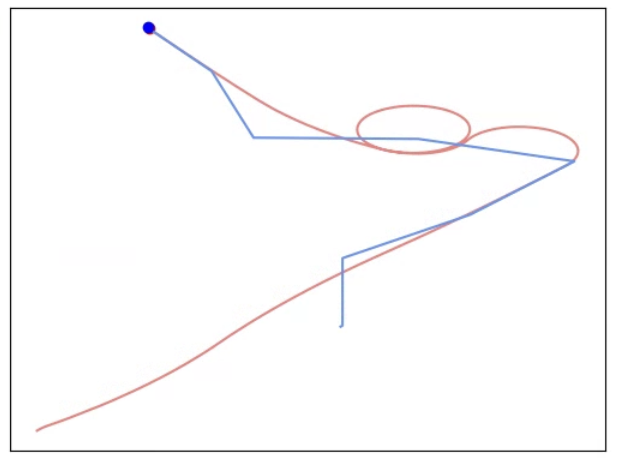
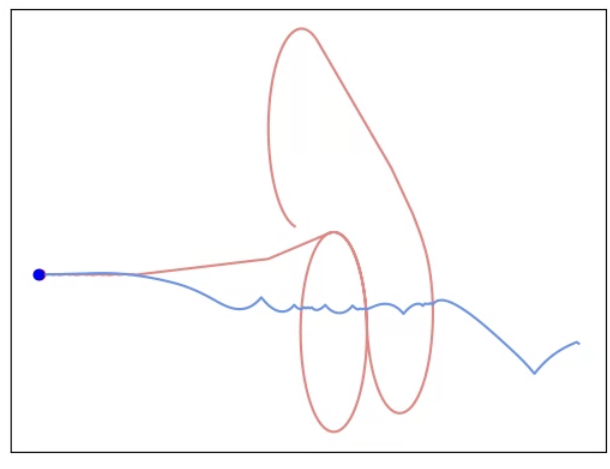
Figure 3: Selected FM-constructed policies from QDSP in Car Tag, illustrating the diversity of strategies such as Q-Learning, MPC, evolutionary search, and heuristics.
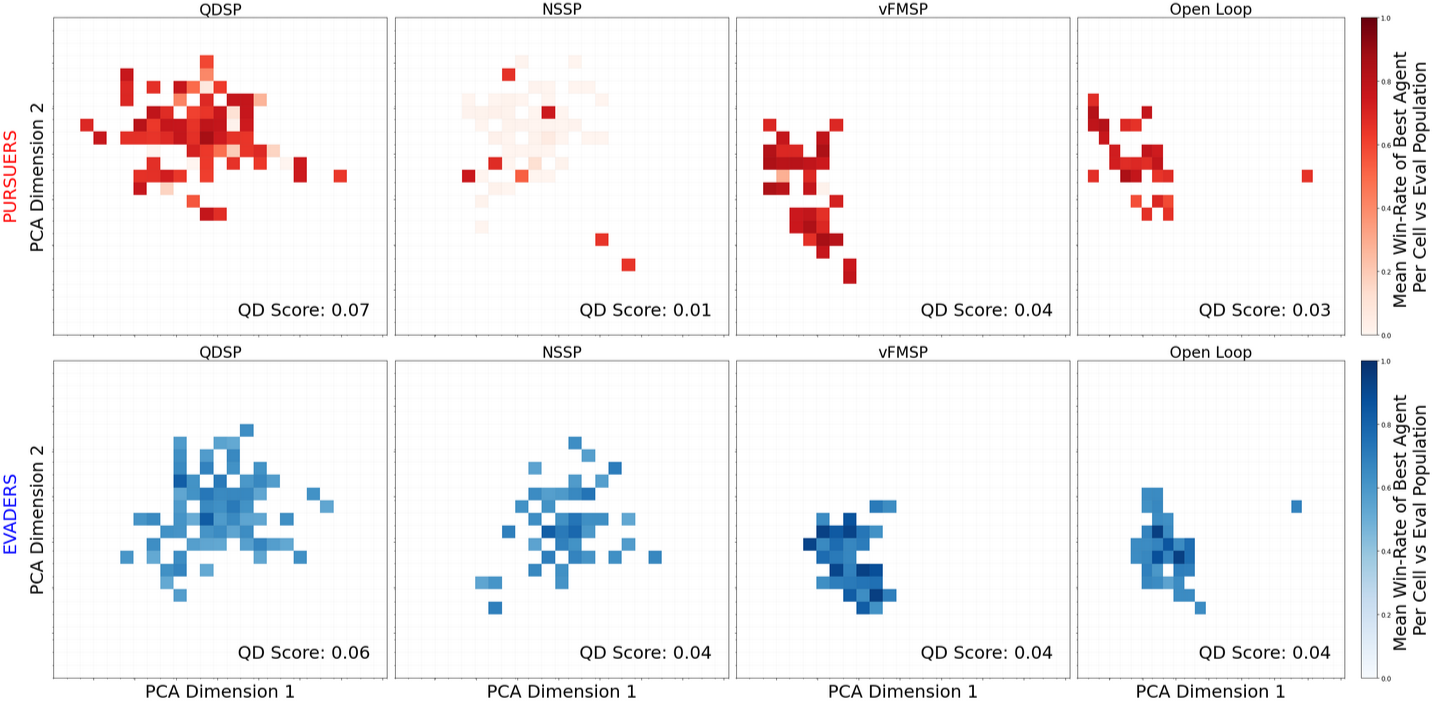
Figure 4: Example QD Plots for each algorithm, showing the coverage and quality of discovered policies in the PCA-reduced embedding space.
Key findings include:
- QDSP achieves the highest QD-Score, indicating the best balance between exploration and exploitation.
- vFMSP and Open-Loop baselines can find high-quality policies but exhibit limited exploration.
- NSSP explores widely but fails to consistently find high-performing solutions.
- QDSP and vFMSP generate policies that match or exceed strong human-designed baselines, with QDSP being the only method to consistently produce top-tier policies for both pursuer and evader roles.
Empirical Evaluation: Gandalf (LLM Red Teaming)
The Gandalf domain is a text-based AI safety game where attackers attempt to jailbreak an LLM protected by a series of increasingly sophisticated defenses. This domain tests the ability of FMSP algorithms to discover novel attack and defense strategies in a setting where solutions are unlikely to be present in the FM's pretraining data.
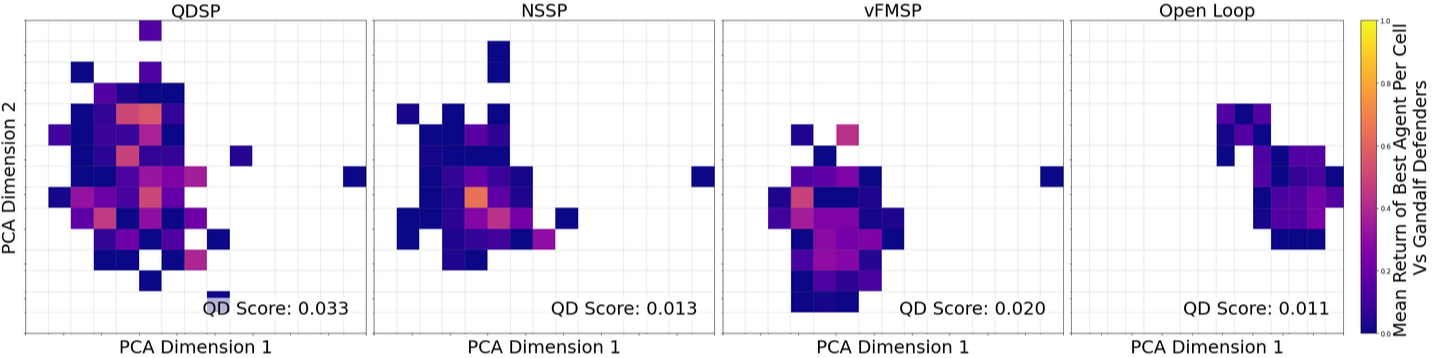
Figure 5: QD Plots for each algorithm showing the diversity and quality of solutions found when evolving attackers for the Gandalf game.
- QDSP, NSSP, and vFMSP all discover attack policies that defeat Gandalf levels 1–6.
- The Open-Loop baseline fails to solve the more challenging levels, indicating that FM pretraining alone is insufficient for this domain.
- QDSP achieves the highest QD-Score (statistically significant, p<0.05), demonstrating superior balance between exploration and exploitation.
- No single policy is able to defeat the combined defenses of level 7, highlighting the compositional challenge of synthesizing multiple specialist strategies.
Closing the Loop: Automated Defense Generation
FMSP algorithms are also evaluated in a two-sided setting, where new defenders are evolved to patch vulnerabilities discovered by the attacker population. Defenders are required to maintain functionality on benign queries, preventing degenerate solutions.
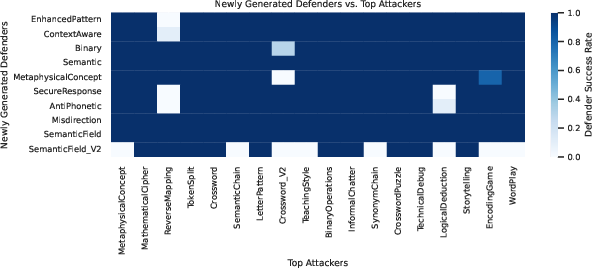
Figure 6: New defenders discovered by QDSP tested against strong attacker variants that collectively bypassed Gandalf levels 1–6. Color indicates defender success rate.
- All FMSP variants, including Open-Loop, are able to generate defenders that patch discovered vulnerabilities within a few iterations.
- Defense appears to be an easier search problem than attack in this domain, likely due to the FM's strong code-writing priors and the relative simplicity of patching known exploits.
Analysis and Discussion
Algorithmic Trade-offs
- vFMSP: Exploitation-focused, rapidly hill-climbs to strong solutions but risks mode collapse and limited diversity.
- NSSP: Exploration-focused, achieves high coverage but low average quality.
- QDSP: Balances both, achieving the highest QD-Score and producing a diverse set of high-quality policies without requiring hand-crafted behavioral descriptors.
FM-Driven Search vs. Non-FM Baselines
A program evolution baseline (GP-style search over code) is dramatically outperformed by FMSP methods, both in terms of diversity and quality. The FM's ability to generate semantically meaningful, executable code is critical for effective search in high-dimensional policy spaces.
Safety and Practical Implications
The paper emphasizes the importance of sandboxing and alignment in automated code generation. FMSP's ability to discover and patch vulnerabilities in LLM defenses demonstrates its potential for automated red teaming and continuous improvement of AI safety mechanisms. However, the same capabilities could be misused, underscoring the need for robust governance and transparency.
Theoretical Implications and Future Directions
- QDSP's dimensionless MAP-Elites approach removes the need for human-specified behavioral axes, enabling open-ended discovery in arbitrary domains.
- The inability to synthesize a single policy that defeats all Gandalf defenses (level 7) highlights the challenge of compositional generalization in open-ended search.
- Future work could integrate more sophisticated population-based or meta-learning techniques, or extend FMSP to generate reward functions or environments, further increasing the scope of open-ended discovery.
Conclusion
Foundation-Model Self-Play (FMSP) represents a significant advance in open-ended multi-agent policy search by leveraging the generative and reasoning capabilities of large foundation models. The QDSP variant, in particular, demonstrates the ability to discover a diverse set of high-quality strategies in both continuous control and AI safety domains, outperforming both human baselines and non-FM search methods. The framework's generality, scalability, and reliance on FM-driven code generation position it as a promising direction for future research in open-ended learning, automated red teaming, and the development of robust, adaptive AI systems.

