Intervening to learn and compose disentangled representations
Published 7 Jul 2025 in stat.ML and cs.LG | (2507.04754v1)
Abstract: In designing generative models, it is commonly believed that in order to learn useful latent structure, we face a fundamental tension between expressivity and structure. In this paper we challenge this view by proposing a new approach to training arbitrarily expressive generative models that simultaneously learn disentangled latent structure. This is accomplished by adding a simple decoder-only module to the head of an existing decoder block that can be arbitrarily complex. The module learns to process concept information by implicitly inverting linear representations from an encoder. Inspired by the notion of intervention in causal graphical models, our module selectively modifies its architecture during training, allowing it to learn a compact joint model over different contexts. We show how adding this module leads to disentangled representations that can be composed for out-of-distribution generation. To further validate our proposed approach, we prove a new identifiability result that extends existing work on identifying structured representations in nonlinear models.
The paper introduces a novel decoder module that effectively learns disentangled latent representations through causal interventions.
It modifies standard encoder-decoder architectures by incorporating representation, intervention, and expressive layers to achieve robust OOD sample composition.
The authors provide an identifiability theorem and validate their approach on benchmark datasets such as MNIST, CelebA, and simulated environments.
Learning Disentangled Representations Through Intervention
This paper introduces a novel approach to training expressive generative models capable of learning disentangled latent structures by incorporating a decoder-only module to the head of an existing decoder block. This module processes concept information by implicitly inverting linear representations from an encoder. Inspired by causal graphical models, the module modifies its architecture during training, allowing it to learn a compact joint model over different contexts, leading to disentangled representations that can be composed for OOD generation. The paper also presents a new identifiability result extending existing work on identifying structured representations in nonlinear models.
Architecture and Methodology
The core of the approach involves augmenting a black-box encoder-decoder architecture with a context module at the decoder's head (Figure 1).
Figure 1: A diagram illustrating the modular approach of appending a context module to the head of the decoder to process embeddings and compose concepts for OOD generation.
This context module consists of three layers: a representation layer, an intervention layer, and an expressive layer. The representation layer learns concept representations by implicitly inverting their linear forms from the encoder's embeddings. The intervention layer embeds these concept representations into a reduced-form SEM. The expressive layer transforms the input latent dimension into a smaller space of exogenous noise variables for the intervention layer. The final decoder architecture is represented as zϵcx, where each layer serves a distinct purpose in mapping the latent space to the generated output.
The use of a reduced form SEM facilitates interventions directly in the latent space, exploiting invariances between interventional contexts without explicitly estimating a causal graph. The authors model the relationships between concepts with a linear SEM:
cj=k=1∑cαkjck+ϵk,αkj∈R.
By reducing this SEM, it can be shown that: c=Aϵ, where c=(c1,…,cc) and ϵ=(ϵ1,…,ϵc).
Concept interventions are performed by manipulating the structural coefficients in the SEM. For example, intervening on the jth concept involves setting α⋅j=0, updating outgoing edges from ϵj, and replacing ϵj with a new ϵj′.
Empirical Validation and Results
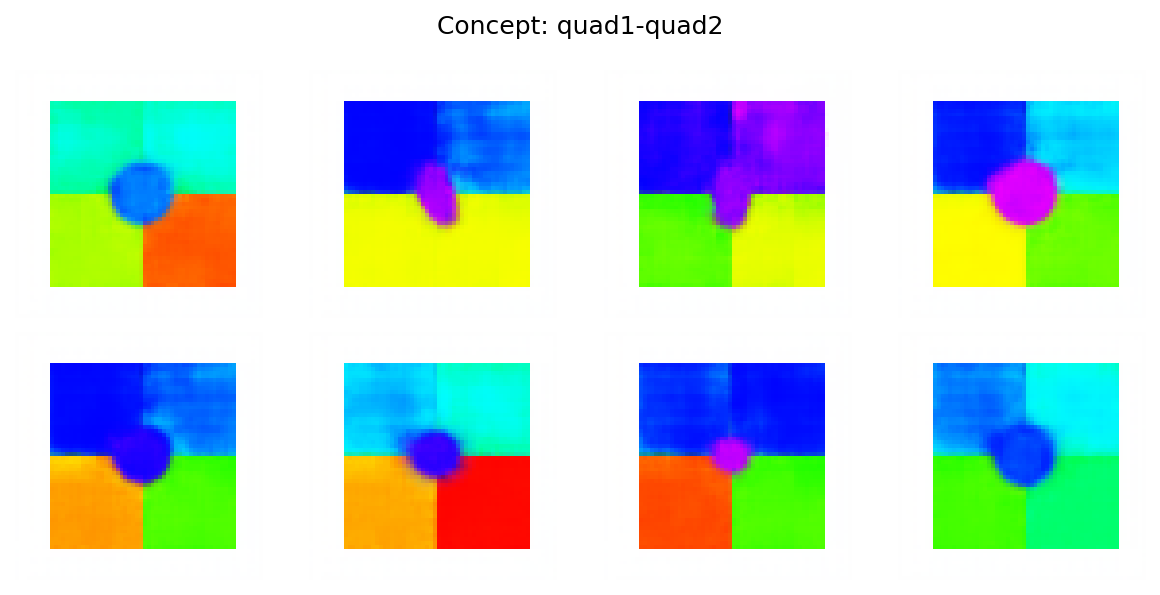
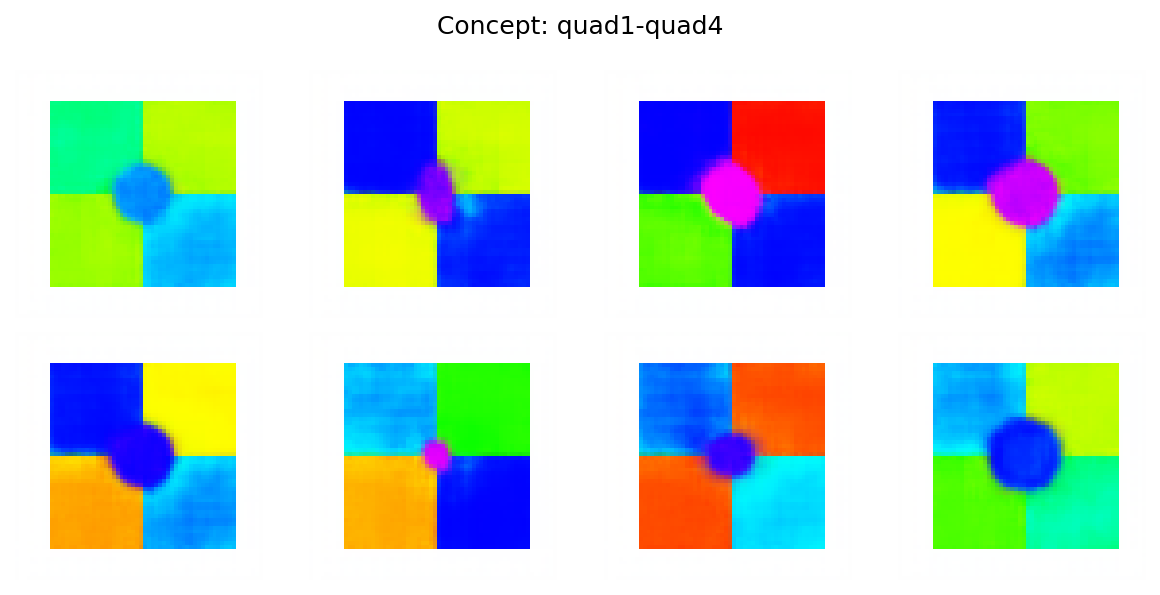
The proposed approach was evaluated through experiments on several benchmark datasets, including 3DIdent, CelebA, and MNIST, as well as controlled simulations. A key aspect of the evaluation involved OOD generation, which demonstrates the model's ability to compose learned concepts in novel ways. The authors introduce a simple simulated visual environment called "quad" for testing disentanglement and OOD generation (Figure 2).
Figure 2: Example images from the quad dataset, showcasing different contexts through single-node interventions (top) and double-concept interventions (bottom).
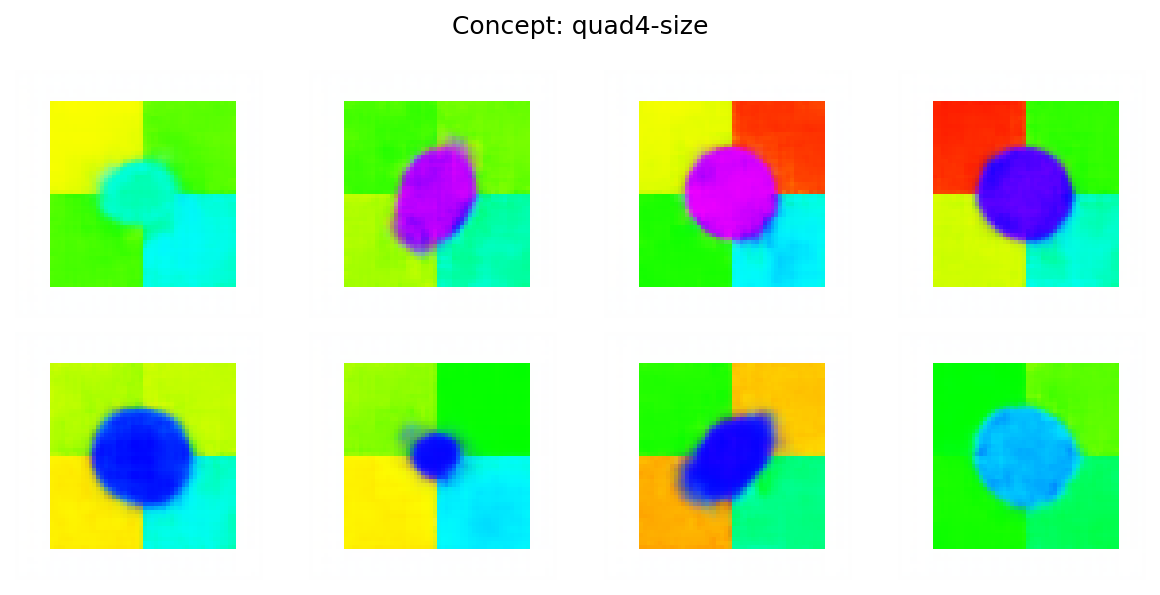
This environment allows for controlled experiments and ablations, providing insights into the model's OOD capabilities. Results on MNIST show that the structured representation learned by the context module incurs only a slight degradation in numerical metrics. Ablation studies on the quad dataset further demonstrate the model's ability to generate OOD samples by composing concepts from seen contexts. For example, Figure 3 shows OOD samples from a lightweight VAE trained on this dataset.
Figure 3: Example images from a lightweight VAE on the quad benchmark, demonstrating concept composition using the concept module.
When the module is incorporated into a complex black-box model (NVAE) on more challenging datasets, the model maintains competitive reconstruction performance, with only slight degradation when the context module is attached to the NVAE decoder.
Theoretical Contributions
The authors provide a theoretical justification for the proposed architecture by proving an identifiability result under concept interventions. This result shows that under certain assumptions, the architecture can be viewed as an approximation to an identifiable model over disentangled concepts. The identifiability result is formally stated as follows:
Theorem: Assume that the rows of each Cj are chosen from a linearly independent set and f is injective and differentiable. Then, given single-node interventions on each concept cj, we can identify the representations Cj and the latent concept distribution p(c).
The proof relies on techniques from previous work on causal representation learning and extends them to the case of concept interventions.
Implications and Future Directions
The research challenges the widely held belief that there is a fundamental tradeoff between expressivity and structure in generative models. By introducing a simple module that can be attached to the head of an existing decoder block, the authors demonstrate that it is possible to learn disentangled latent structure without sacrificing model capacity. The theoretical identifiability result provides further support for the proposed approach.
The implications of this research are significant for a variety of applications, including:
Interpretability: The disentangled representations learned by the model can be used to gain insights into the underlying structure of the data.
OOD generation: The model's ability to compose learned concepts in novel ways enables the generation of OOD samples.
Downstream tasks: The structured representations learned by the model can be used to improve performance on downstream tasks.
Future research directions include:
Extending the theoretical identifiability result to more general settings.
Applying the proposed approach to a wider range of datasets and applications.
Conclusion
This paper presents a compelling approach to learning disentangled representations in generative models. By combining a modular architecture with a causal intervention strategy, the authors demonstrate that it is possible to train expressive models that capture meaningful latent structure. The theoretical and empirical results provide strong support for the proposed approach, highlighting its potential for a variety of applications.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.