- The paper presents Bisecle, a neuro-inspired framework that uses rapid binding and contrastive prompt learning to mitigate catastrophic forgetting in video language understanding.
- It leverages a large multimodal foundation model with frozen vision and language components while updating lightweight adaptive layers for better efficiency.
- Experiments on NExT-QA, DramaQA, and STAR show that Bisecle achieves superior accuracy, reduced forgetting rates, and robust performance even in low-resource settings.
Bisecle: Binding and Separation in Continual Learning for Video Language Understanding
Introduction
The paper "Bisecle: Binding and Separation in Continual Learning for Video Language Understanding" presents a novel approach to address the challenges of continual learning in video language understanding tasks. The authors introduce Bisecle, a framework inspired by neurobiological mechanisms, particularly rapid binding and pattern separation observed in the hippocampus. This approach aims to mitigate issues like catastrophic forgetting and update conflicts encountered in traditional continual learning frameworks.

Figure 1: (a) The backbone of our continual learning framework for video understanding; (b) The improved designs proposed in this paper; (c) The motivations from a neurobiological perspective.
Methodology
Backbone Architecture
The proposed framework utilizes a large multimodal foundation model combining a vision encoder with an LLM. The backbone architecture (Figure 1(a)) consists of frozen components, with only lightweight adaptive layers being updated during new task learning. This ensures efficient continual learning by avoiding the high computational costs associated with full-model updates.
Rapid Binding-Inspired Multi-Directional Supervision
To address catastrophic forgetting, Bisecle integrates a multi-directional supervision module inspired by the hippocampus's rapid binding mechanism. This module captures cross-modal relationships through auxiliary tasks such as question prediction from video and answer, and video reconstruction from question and answer. These tasks facilitate the binding of causal relationships and enhance multimodal understanding.
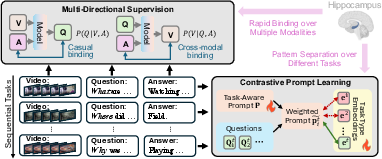
Figure 2: The sketch map to explain the two modules in Bisecle, multi-directional supervision and contrastive prompt learning.
Pattern Separation-Inspired Contrastive Prompt Learning
Bisecle tackles update conflicts using contrastive prompt learning. Drawing from the concept of pattern separation in the brain, it employs task-specific embeddings to guide the learning of shared prompts. This method ensures distinct task knowledge encoding while preventing interference among different task adaptations, optimizing the generalization across sequential tasks.
Experiments
Extensive experiments were conducted on three VideoQA benchmarks: NExT-QA, DramaQA, and STAR. Bisecle demonstrated superior performance in terms of accuracy and reduced forgetting rates compared to existing methods. Notably, Bisecle showed robustness across varying data sizes and achieved effective parameter efficiency even in low-resource settings.
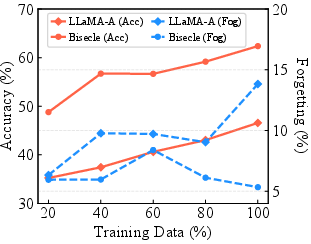
Figure 3: Performance on different sizes of training datasets.
Implications and Future Work
The insights gained from Bisecle provide a strong basis for the design of biologically inspired AI systems. The notable improvements in handling continual learning challenges illustrate the potential applicability beyond video understanding, extending to various multimodal domains. Future developments could explore adapting these principles to task-free continual learning settings and more diverse, dynamic environments.
Conclusion
Bisecle effectively addresses the critical challenges in continual learning for video LLMs by harnessing neurobiological principles, specifically rapid binding and pattern separation. Its successful application to video understanding tasks, coupled with promising empirical results, marks a significant step towards robust, memory-efficient learning in AI systems.