- The paper introduces adaptive PID control to regulate token usage, balancing reasoning efficiency and accuracy.
- It employs a lightweight redundancy classifier and control vector to detect and mitigate overthinking in chain-of-thought reasoning.
- Experiments on the GSM8K dataset demonstrate a 6% accuracy improvement with a 32% reduction in token usage.
STU-PID: Dynamic Steering for Efficient LLM Reasoning
The paper "STU-PID: Steering Token Usage via PID Controller for Efficient LLM Reasoning" (2506.18831) introduces a novel method for improving the efficiency of LLMs by dynamically adjusting the steering strength during inference, addressing the "overthinking phenomenon" often observed in LLMs employing chain-of-thought (CoT) reasoning. The method, named STU-PID, leverages a PID controller to modulate activation steering based on real-time assessment of reasoning quality, achieving a balance between accuracy and computational cost. The core idea is to use a chunk-level classifier to detect redundant reasoning patterns and provide feedback to the PID controller, which then adjusts the steering intensity.
Background and Motivation
LLMs often generate excessive and redundant reasoning steps, leading to increased computational costs and potential performance degradation (2506.18831). While static steering approaches like SEAL (Chen et al., 7 Apr 2025) have shown promise in calibrating reasoning processes, they lack the adaptability to dynamically adjust intervention strength based on real-time reasoning quality. STU-PID addresses this limitation by introducing a dynamic steering framework that uses PID control to adjust intervention strength based on reasoning quality assessment in real-time.
STU-PID Methodology
The STU-PID framework consists of three main components: a redundancy classifier, a PID controller, and a control vector application mechanism.
- Redundancy Classifier: A lightweight classifier C is trained to detect redundant reasoning patterns at the chunk level. Given a sequence of tokens forming a reasoning chunk, the classifier outputs a probability pred∈[0,1] indicating the likelihood that the chunk represents redundant reasoning. The classifier operates on chunk-level hidden representations extracted from layer l of the model:
pred=C(hlchunk)
where hlchunk represents the mean-pooled hidden states of tokens within a reasoning chunk at layer l.
- PID Controller: The core innovation of STU-PID is the use of a PID controller to dynamically adjust steering strength. The controller maintains three components:
et=pred,t−ptarget
Pt=KP⋅et
It=KI⋅∑i=0tei
Dt=KD⋅(et−et−1)
where ptarget is the desired redundancy probability, and KP, KI, KD are the proportional, integral, and derivative gains, respectively. The steering strength is computed as:
αt=max(0,min(αmax,αt−1+Pt+It+Dt))
- Control Vector Application: Following previous work (Chen et al., 7 Apr 2025), a control vector v is constructed by computing the difference between mean hidden representations of required and redundant reasoning patterns:
v=E[hrequired]−E[hredundant]
This vector is applied during generation when the PID controller determines intervention is necessary.
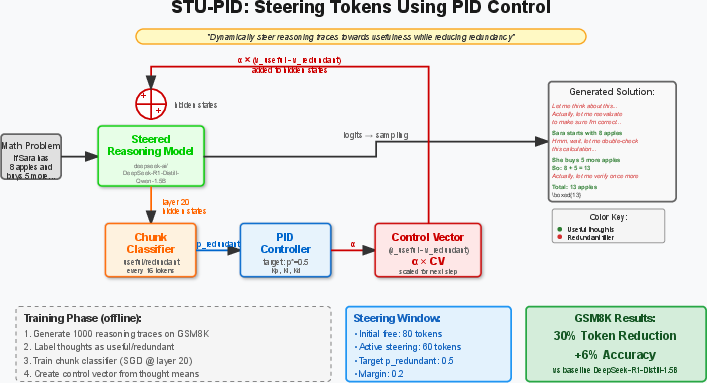
Figure 1: STU-PID Algorithm Flow: The system dynamically adjusts steering strength using a PID controller based on real-time redundancy detection. The classifier analyzes reasoning chunks and provides feedback to the PID controller, which modulates the control vector strength applied to the model's hidden states.
Experimental Results
The authors evaluated STU-PID on the GSM8K dataset using DeepSeek-R1-Distill-Qwen-1.5B as the base model. The results demonstrate that STU-PID achieves a 6% improvement in accuracy while reducing token usage by 32% compared to the baseline model. These results highlight the effectiveness of adaptive steering control in balancing accuracy and computational efficiency.
Implementation Details
The implementation involves offline training and online inference phases. The offline training phase includes data collection, classifier training, control vector extraction, and hyperparameter optimization. The online inference phase dynamically adjusts the steering strength based on the classifier's redundancy predictions, as illustrated in Figure 1. Optimal PID controller parameters were found through hyperparameter optimization: KP=0.01, KI=0.0005, KD=0.005, ptarget=0.3, and αmax=0.40.
Implications and Future Directions
The STU-PID framework offers a promising approach for dynamically calibrating reasoning in LLMs. The adaptive steering behavior of the PID controller allows for intelligent intervention, suppressing unnecessary thoughts while preserving productive reasoning. While the experiments focused on GSM8K, the framework is designed to be task-agnostic and can be adapted to various reasoning patterns. Future work includes large-scale evaluation, multi-domain studies, automated hyperparameter tuning, and integration with training-time optimizations.
Conclusion
STU-PID introduces a novel approach for dynamic adaptive reasoning calibration in large reasoning models using PID control. By dynamically adjusting steering strength based on real-time redundancy detection, STU-PID achieves superior performance compared to static steering methods. The experimental results on GSM8K demonstrate a 6% improvement in accuracy with a 32% reduction in token usage, highlighting the potential of adaptive control mechanisms for efficient reasoning.