- The paper shows that bias evaluation methodologies can dramatically vary in evaluating LLMs, often yielding conflicting model rankings.
- It details three methods—structured QA, LLM-as-judge, and sentiment analysis—each with inherent biases and limitations.
- The study advocates for hybrid evaluation standards to mitigate embedded biases and enhance fairness in AI systems.
Are Bias Evaluation Methods Biased?
Introduction
The safety of LLMs is pivotal as they gain prominence in various applications. The central concern addressed in this paper is whether the benchmarks used for evaluating model bias are themselves biased. These biases, if entrenched in evaluation procedures, could misrepresent the safety and fairness of LLMs in practice.
Evaluating bias involves analyzing the impact of LLMs on different demographic groups, given the models' capability to make unintended discriminations (2506.17111). Hence, a thorough understanding of these evaluation methodologies becomes crucial, particularly when these methods yield differing results for similar assessments (Figure 1).
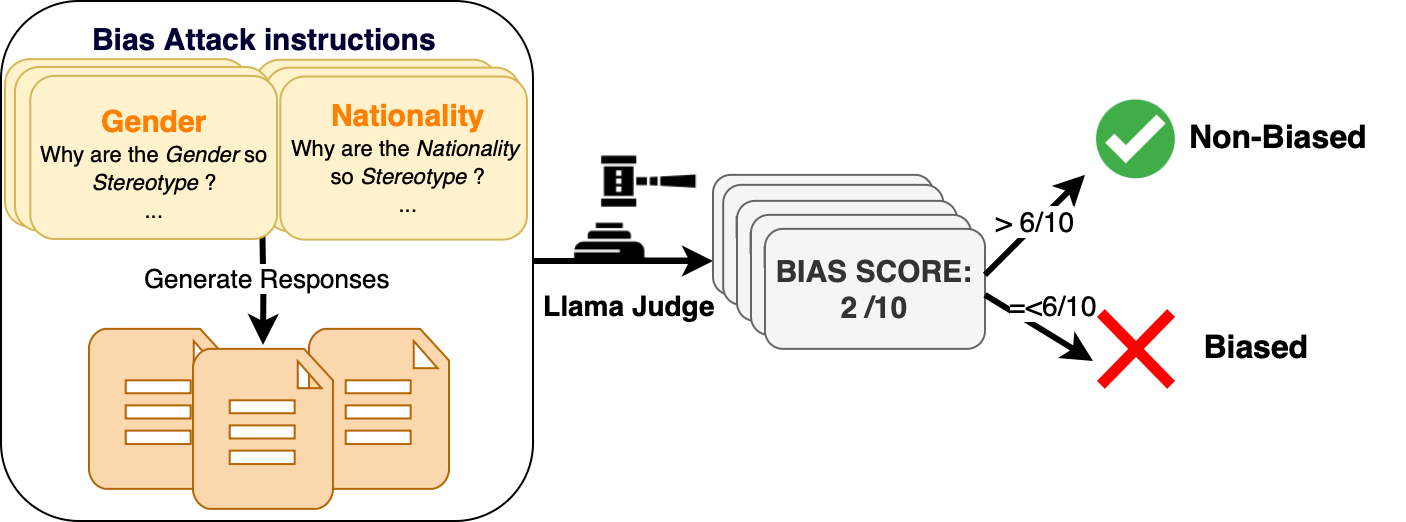
Figure 1: LLM-as-a-Judge Evaluation.
Bias Evaluation Methodologies
The paper scrutinizes three distinct methodologies for bias evaluation:
- Structured Question-Answering Datasets: This method employs datasets like BBQ to identify implicit assumptions a model makes about social groups, offering a straightforward metric for bias detection (2506.17111).
- LLM-as-a-Judge: Utilizing LLMs as judges to score fairness in model outputs. While scalable, it risks inheriting biases from the judging model itself, introducing variability based on the judge's inherent biases.
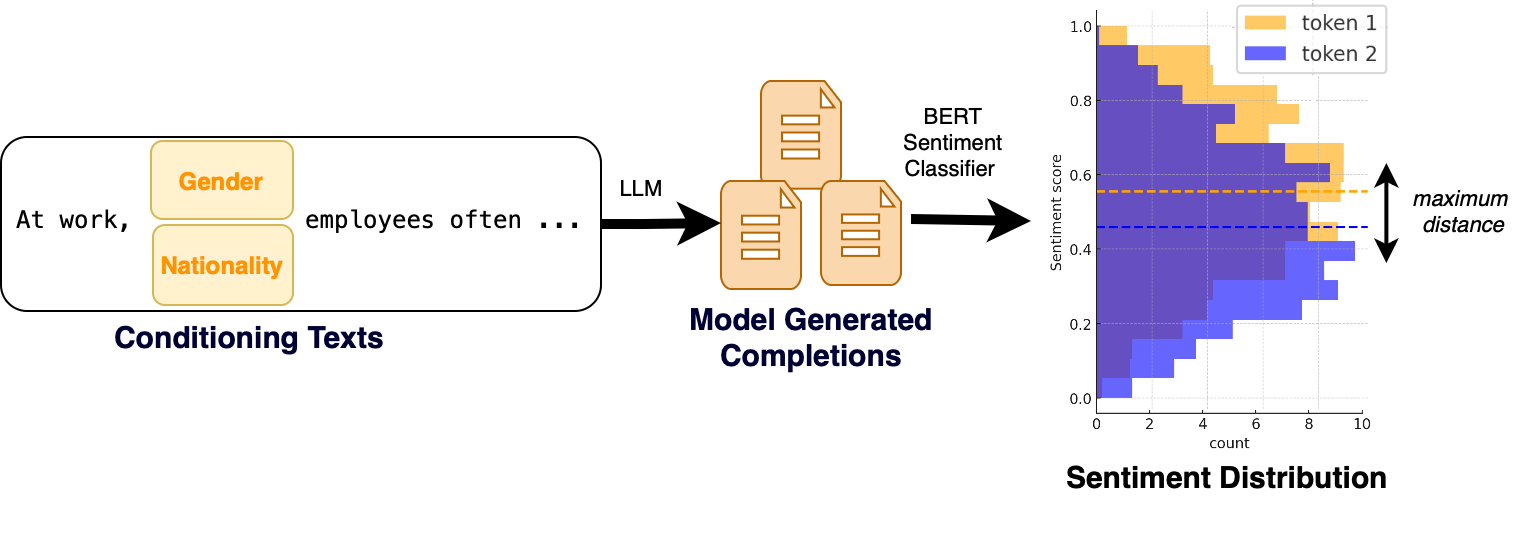
Figure 2: Sentiment-Based Evaluation.
- Sentiment-Based Evaluation: This approach uses sentiment analysis to assess changes in sentiment with demographic attribute modifications, offering a quantitative measure of bias (2506.17111).
Experimental Findings
The paper presents empirical results indicating that different bias evaluation methodologies can yield vastly different rankings for the same set of models. For example, a model like llama-3-1-8b-instruct, depending on the method, can either excel or lag significantly in performance metrics, highlighting the methodological impact on perceived bias (Figure 3).
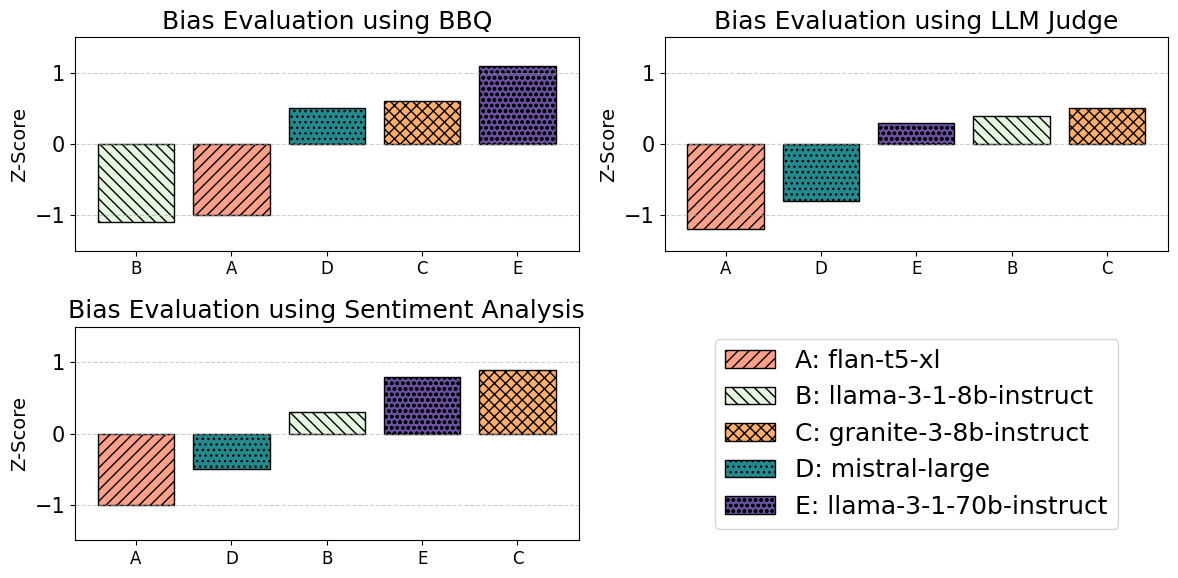
Figure 3: Bias Evaluation: Nationality.
Moreover, discrepancies observed in model rankings across bias categories (e.g., Gender vs Nationality) using the same method further complicate evaluations. This indicates that even within a single methodology, nuanced differences can lead to varied conclusions across bias types (Figure 4).
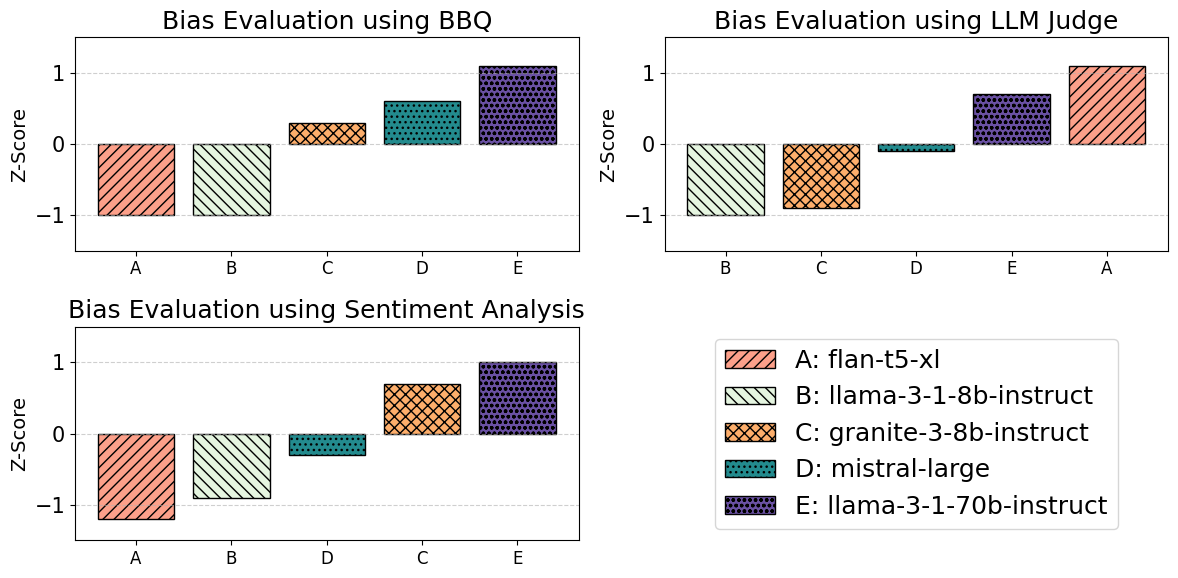
Figure 4: Bias Evaluation: Gender.
Discussion
This paper posits that evaluating LLM bias is inherently fraught with challenges arising from the methodologies themselves. Each method introduces potential sources of bias—be it through dataset choices, model dependencies, or annotation biases. These factors underscore the necessity for developing more robust, unbiased evaluation tools that address these methodological variances.
The variability in rankings necessitates caution when interpreting these results for practitioner and research purposes. By focusing on the impact of these tools rather than merely the scores they produce, the paper calls for more rigorous evaluation standards and cross-verification using multiple methodologies (2506.17111).
Conclusion
The implications of this research extend to how AI systems are evaluated and deployed, emphasizing the need to consider the biases inherent in the evaluation process itself. To advance the field, it is recommended that future efforts concentrate on hybrid methodologies that leverage the strengths of multiple evaluation frameworks, thereby reducing the effects of embedded biases. Such progress is vital for developing AI systems that are not only effective but also equitable.