- The paper presents a novel sparse autoencoder approach that precisely aligns topics in LLMs by scoring neurons based on semantic similarity.
- The swap method dynamically adjusts SAE outputs, reducing contamination and reconstruction errors compared to traditional clamping techniques.
- The approach showcases scalability and efficiency by eliminating extensive parameter tuning while reducing computational costs in topic alignment.
Enabling Precise Topic Alignment in LLMs Via Sparse Autoencoders
Overview
This paper explores the utility of Sparse Autoencoders (SAEs) for enhancing topic alignment in LLMs. The primary aim is to achieve precise alignment for any topic without extensive parameter tuning, by leveraging the observational and modification capabilities of SAEs. This approach involves scoring each SAE neuron by its semantic similarity to an alignment text and modifying SAE-layer-level outputs by emphasizing topic-aligned neurons. The authors evaluate this approach using various public datasets, including Amazon reviews, Medicine, and Sycophancy, and across different models such as GPT2 and Gemma.
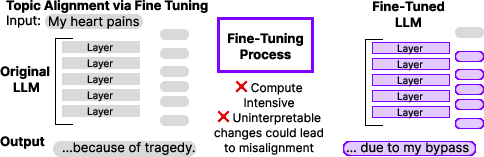
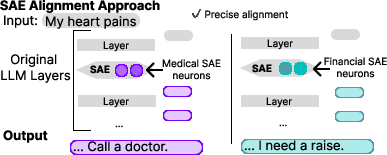
Figure 1: Overview of existing vs. proposed topic alignment approaches.
Sparse Autoencoders for Topic Alignment
SAEs, drawn from Mechanistic Interpretability (MI), have demonstrated potential in identifying interpretable neurons within LLM layers. These neurons correspond to individual topics, thus offering a more efficient approach to modification than fine-tuning whole models. SAEs decompose the layer output and allow precise topic alignment through controlled manipulation.
Recent advances show that SAEs can encode layer outputs into SAE neurons showing individual human-like concepts, allowing SAE neurons to guide model outputs with more precision than other methods that might produce unintended alignments.
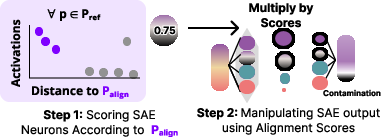
Figure 2: SAE mechanics illustrating neuron encodings related to specific topics.
Methodology
SAE Neuron Scoring
The approach leverages a large reference set (ref) to calculate scores for each SAE neuron, reflecting its semantic similarity to alignment topics (align). The scores penalize neurons activated by unrelated prompts, ensuring neurons highly relevant to align are prioritized.
Modifying SAE Outputs
Two primary methods are employed: the clamping approach, which sets specific high-scoring SAE neurons to high values, and a swap approach that modifies SAE outputs based on calculated neuron scores. The swap method is particularly noteworthy due to its context-sensitive adjustments, avoiding unnecessary garbled outputs.
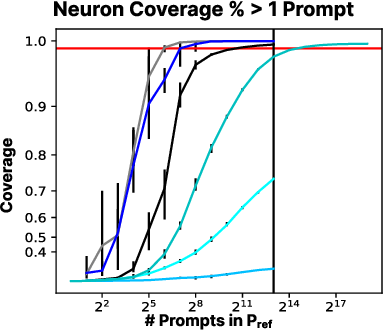
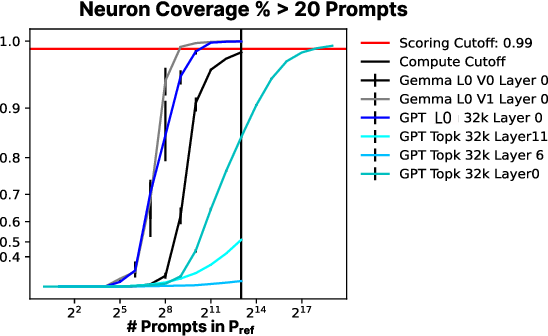
Figure 3: Percentage of SAE neurons activated across different configurations.
Experimental Results
Experiments focused on evaluating the performance of neuron scores, layer outputs, and full model-generated outputs. Notably, the swap approach demonstrated lower contamination and reconstruction errors compared to the clamp baseline, indicating better alignment with desired topics.
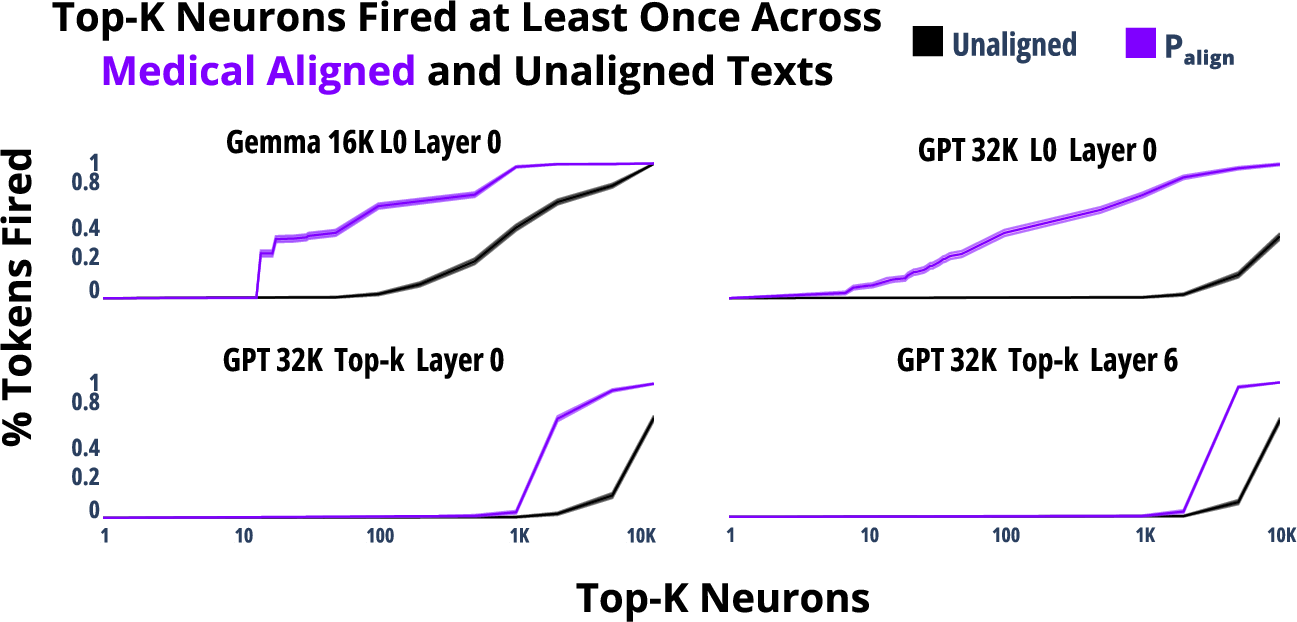
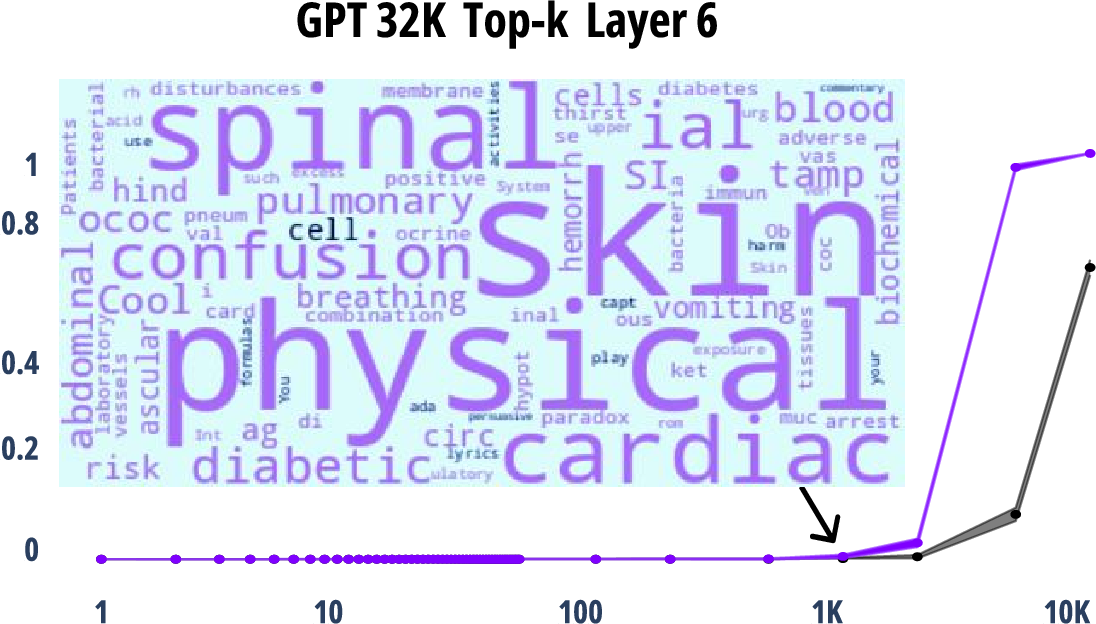
Figure 4: Observations on neuron activation across different alignment topics.
Layer-Level Output Analysis
The layer-level analysis highlights the swap approach for its dynamic adjustments based on incoming token context, resulting in better topic alignment, especially with aligned input texts. This adaptive technique showcases potential for more effective alignment across diverse operational scenarios.

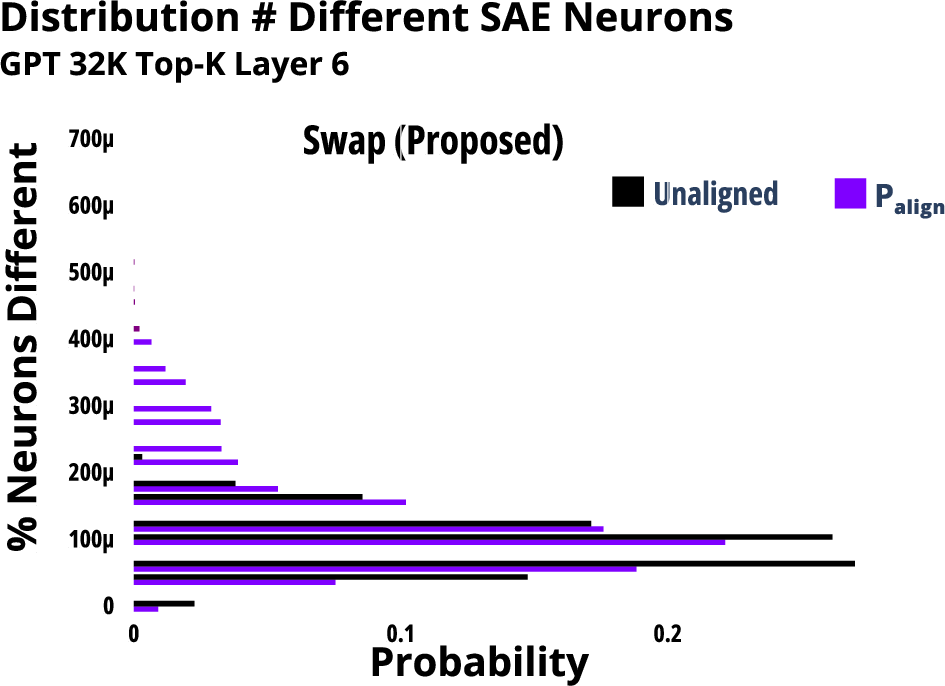
Figure 5: Metrics for Clamp Approach compared against Swap and Original approaches.
Implementation Considerations
The computational efficiency of the SAE-based approach presents a viable alternative to classic fine-tuning strategies, with significant reductions in training and inference times due to mechanistic interpretability properties of SAEs. Furthermore, these methods require no parameter tuning, enhancing scalability and adaptability.
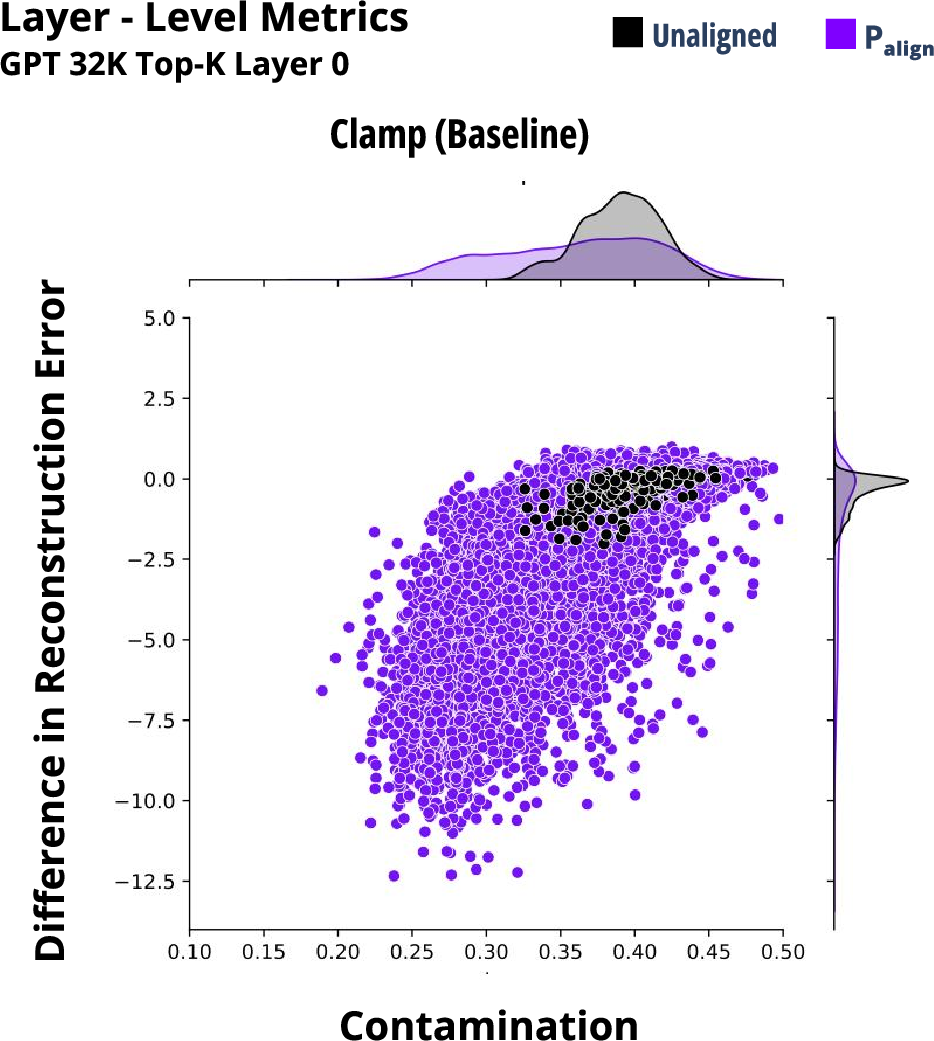
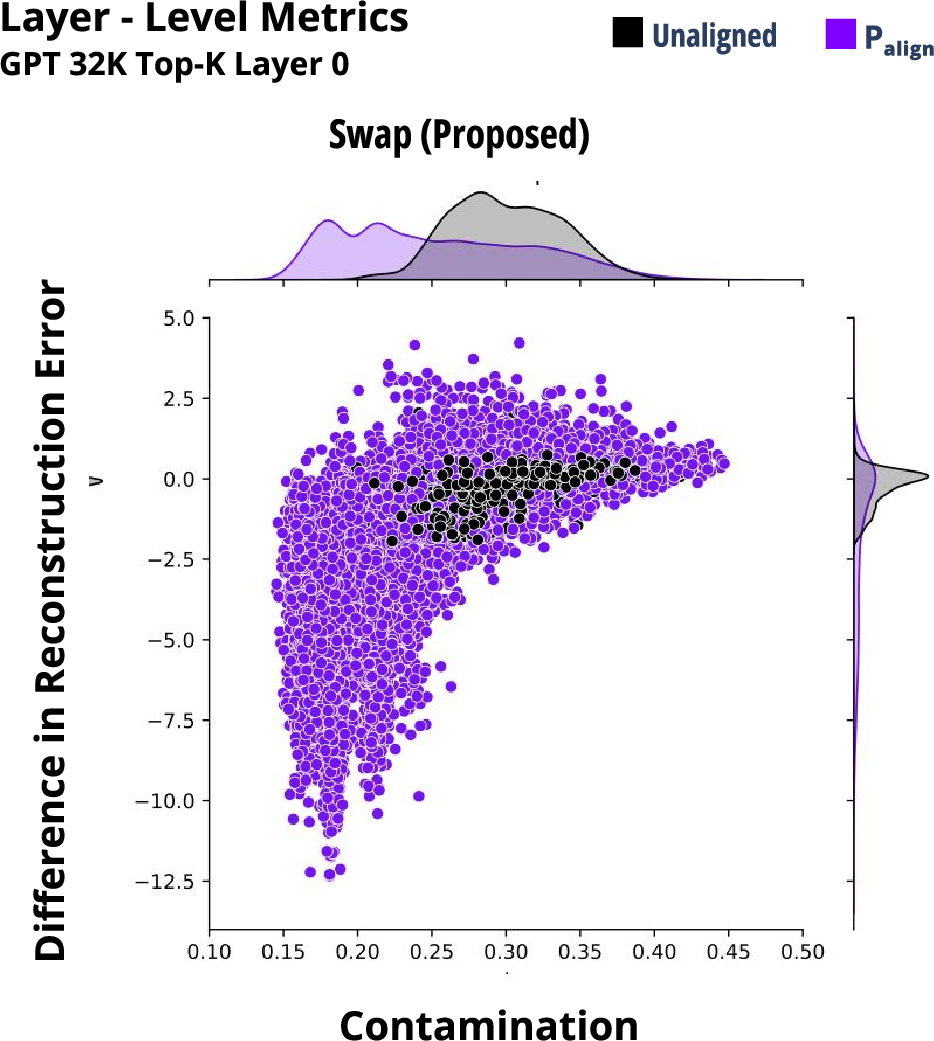
Figure 6: Computational costs breakdown for SAE approaches.
Conclusion
This research validates the promising potential of SAEs for precise topic alignment within LLMs. The innovative scoring and modification techniques allow for improved control and efficiency over traditional methods. Future efforts can explore enhancing SAE representational power and refine scoring mechanisms for even broader applications and real-time adaptations.

