- The paper finds that supervised dictionary learning methods (e.g., DiffMean, Probe, ReFT-r1) achieve high ROC AUC (~0.94-0.95) in concept detection, outperforming sparse autoencoders.
- The evaluation shows that prompting and finetuning yield the best model steering scores, while representation-based methods face a trade-off between concept integration and instruction adherence.
- AxBench highlights that joint objective optimization and transferable subspace learning offer promising directions for achieving interpretable and efficient LLM control.
AxBench: Systematic Evaluation of Representation-Based Steering in LLMs
Motivation and Benchmark Design
The paper introduces AxBench, a large-scale benchmark for fine-grained control and interpretability in LLMs via representation-based interventions (2501.17148). The motivation centers on limitations of prompting and parameter-efficient finetuning for steering LLM outputs, specifically their vulnerability to adversarial attacks, dependence on data quality, and lack of interpretability. To address these gaps, interpretability-driven representation steering methods—including sparse autoencoders (SAEs), supervised dictionary learning (SDL), difference-in-means, and others—have been proposed. However, systematic comparison at realistic scale has been lacking.
AxBench evaluates LM control methods across two orthogonal axes: concept detection (classification of hidden representations for concept presence) and model steering (causal intervention to induce specified concepts into long-form generations). The benchmark leverages synthetic data generated by LLMs using curated concept lists and task instructions (Figure 1). Tasks span four layers across two Gemma-family models (Gemma-2-2B and Gemma-2-9B), resulting in eight core tasks with 500 concepts each (Concept500).
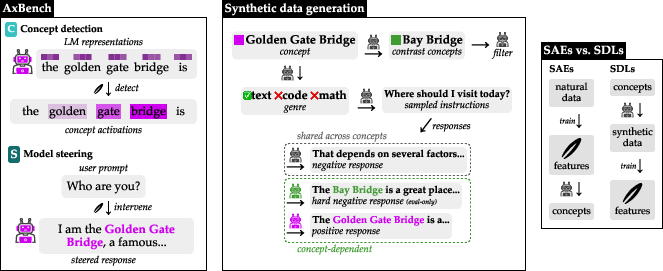
Figure 1: AxBench pipeline, displaying concept-driven synthetic data generation and contrasting SAEs with supervised dictionary learning (SDL).
Methodological Comparison
AxBench evaluates a range of steering approaches:
- SAE and variants: Self-supervised dictionary learning for sparse, monosemantic features.
- DiffMean: Difference-in-means steering vectors, directly computed from positive/negative representation means.
- Probe: Linear probing for discriminative concept classifiers.
- PCA and LAT: Unsupervised dimensionality reduction approaches for subspace discovery.
- Supervised Steering Vector (SSV): Directly trained vector via language modeling objective.
- Rank-1 Representation Finetuning (ReFT-r1): Novel supervised rank-1 dictionary learning combining detection and steering objectives.
- Prompting and Parameter-Efficient Finetuning: Strong baselines including in-context prompting, SFT, LoRA, and LoReFT.
All methods are evaluated using synthetic concept detection data (classification ROC AUC) and steered generations scored by an LM judge (harmonic mean of concept score, instruction following, and fluency).
Empirical Findings
Concept Detection
ROC curves indicate that DiffMean, Probe, and ReFT-r1 are statistically indistinguishable in performance, achieving mean ROC AUCs ≈0.94−0.95 (Figure 2). Prompting and SAE variants lag behind, with unsupervised SAEs substantially underperforming supervised dictionary learning.
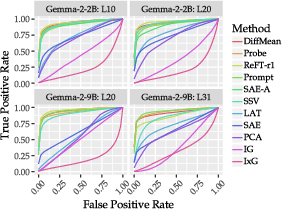
Figure 2: Mean ROC curves for concept detection across all evaluated methods.
Class-imbalance experiments (Figure 3) demonstrate robust performance retention for DiffMean, Probe, and ReFT-r1, while SAE, LAT, and PCA degrade sharply with increasing negative examples.
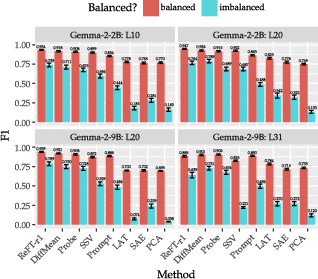
Figure 3: F1 scores under dataset balance for concept detection, evidencing robustness in top-performing supervised methods.
Model Steering
Prompting and finetuning yield the highest steering scores, with ReFT-r1 competitive only in the smaller Gemma-2-2B model but trailing substantially in Gemma-2-9B. DiffMean outperforms SAEs, while all other steering methods—including SSV and unsupervised variants—fail to surpass SAE performance.
Steering factor analysis (Figure 4) reveals a monotonic trade-off: increasing steering magnitude boosts concept score but consistently degrades instruction alignment across all methods. Only ReFT-r1 traces a Pareto-optimal curve maximizing concept integration given instruct performance.
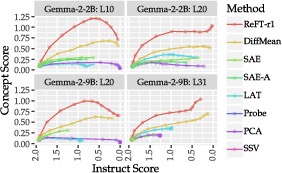
Figure 4: Pareto trade-off between concept and instruction scores as steering factor is varied for each method.
Scaling and Subspace Analysis
Data scaling ablation for ReFT-r1 (Figure 5) shows rapid saturation in both detection and steering metrics after a modest number of examples, implying high efficiency.
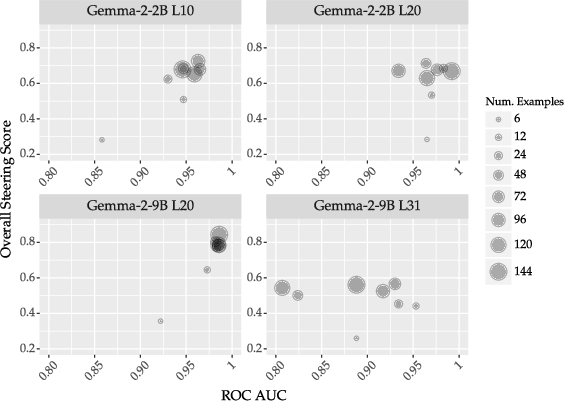
Figure 5: Scaling law for ReFT-r1 demonstrating performance saturation with limited training data.
UMAP projection of learned subspaces by ReFT-r1 reveals well-clustered, genre-consistent concept spaces (Figure 6), highlighting the interpretability potential of SDL methods.
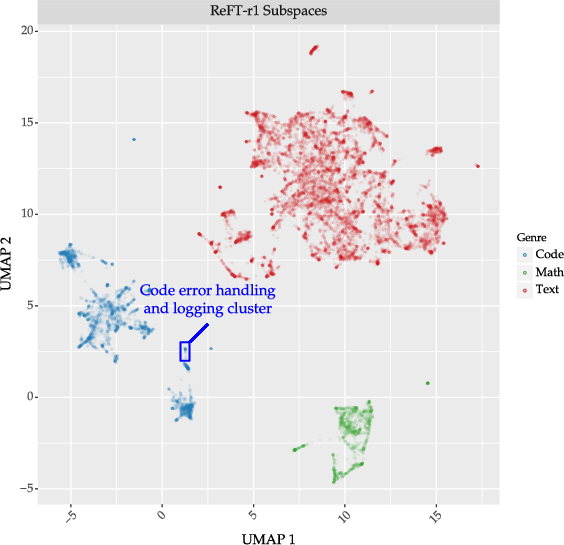
Figure 6: UMAP of ReFT-r1 Concept16K subspaces, exhibiting genre-based clustering in Gemma-2-2B layer 20 residual stream.
Affine transformation experiments (Figures 12–13) suggest robust cross-model transferability of subspaces, with minimal performance drop in concept detection and moderate degradation for steering, showing that shared geometric representation across different LLMs is achievable.
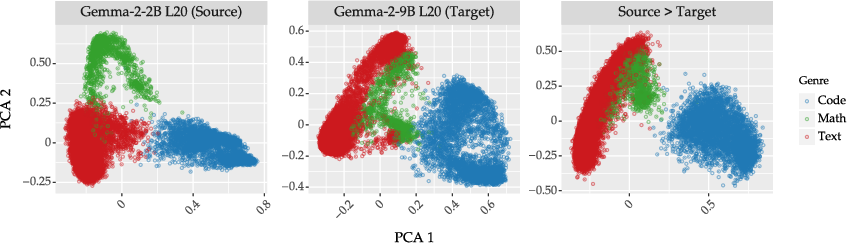
Figure 7: PCA visualization of Concept16K subspaces: direct, Gemma-2-2B → Gemma-2-9B, and affine-transformed.
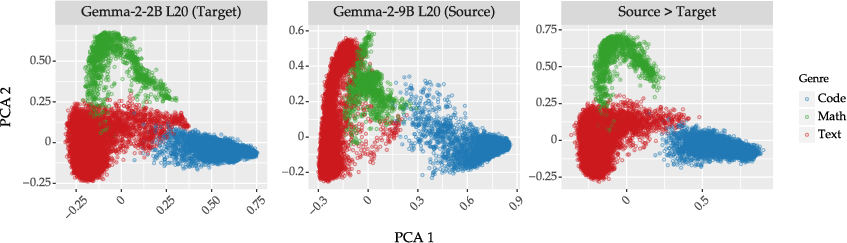
Figure 8: PCA visualization of Concept16K subspaces: direct, Gemma-2-9B → Gemma-2-2B, and affine-transformed.
Discussion and Theoretical Implications
The benchmark establishes that, despite their promise, representation-based steering methods do not surpass standard prompting and finetuning in overall efficacy. Notably, even simple supervised baselines like DiffMean outperform sophisticated unsupervised methods such as SAEs. Supervised dictionary learning (SDL), especially ReFT-r1, is competitive and provides interpretable, extensible alternatives to SAEs, but concept-agnostic scalability (the primary advantage of SAEs) is not matched.
Additionally, the results indicate a clear limitation in current steering paradigms: increasing steering factor impairs instruction adherence (capabilities preservation) for all methods, highlighting a fundamental trade-off not yet mitigated by unsupervised or supervised approaches.
The ability to transfer subspaces across models via affine transformations signals emergent universality in linear representations—a finding consistent with current theoretical work on geometric causal abstraction and monosemanticity. However, steering performance remains sensitive to both model scale and layer selection.
Practical Implications and Future Directions
From a practical standpoint, the benchmark provides rigorous, scalable measurements for LM interpretability and control, facilitating accurate comparison and ablation. SDL methods, particularly ReFT-r1, are viable for efficient, interpretable steering with small, synthetic datasets, supporting rapid extension to new concepts. The open release of data, features, and pipelines further enables reproducibility and downstream application.
Theoretical implications concern the limits of linear representation-based control: current methods do not offer practical superiority over prompting and finetuning, but careful joint learning (as in ReFT-r1) narrows the gap. Future work may focus on more robust subspace discovery, improved concept labelling, and the identification of universal representation geometries supporting reliable control across LLM architectures. Additionally, research should target the mitigation of the concept/capabilities trade-off, possibly by exploring higher-rank interventions or hybrid approaches integrating interpretability constraints.
Conclusion
AxBench demonstrates that supervised dictionary learning methods reliably outperform sparse autoencoders in both concept detection and steering, yet they fall short of prompting and finetuning baselines in practical model control. The findings suggest that while representation-based steering is not yet a standalone alternative, advances in joint objective optimization and transferable subspace learning hold promise. Comprehensive, scalable benchmarks like AxBench are necessary to catalyze progress and expose latent bottlenecks in interpretability-driven control of LLMs.