- The paper presents a technique that bypasses the fully-connected layer using an 8-channel bottleneck to enhance phonotactic generalization.
- It demonstrates that convolutional layers in a modified WaveGAN can robustly model lexically-independent phonetic dependencies with measurable VOT consistency.
- The approach underscores the potential for reduced model complexity to yield more interpretable, cognitively realistic representations in generative CNNs.
A Technique for Isolating Lexically-Independent Phonetic Dependencies in Generative CNNs
Introduction
The paper investigates the capacity of generative convolutional neural networks (CNNs) to represent phonotactic generalizations independently from lexical constraints. Phonotactics play a crucial role in determining acceptable sound sequences, often operating independently of the lexicon. The study does not just focus on the conventional fully-connected layer (FC) of CNNs but proposes a method to bypass it for uncovering phonetic generalizations in a lexically-invariant manner.
Methodology
Model Architecture and Training
The research employs a WaveGAN-based generative model architecture, with a particular innovation of exploiting convolutional blocks over the traditional FC layers. The key hypothesis is that convolutional layers, due to their inherent translation-invariance, can capture phonetic dependencies without being anchored to fixed lexical templates. By drastically reducing the number of channels in the FC — from 1024 to 8 — the study introduces a bottleneck ensuring significant compression of information, thereby hypothesizing a model which simplifies the resultant phonetic interpretations.
Experimentation
Two sets of models were trained on distinct training data comprising words with varying phonotactic restrictions. The pivotal experiment involves bypassing the FC by injecting random feature maps into the convolutional layers, potentially revealing patterns of linguistic generalization not constrained by lexical configurations.
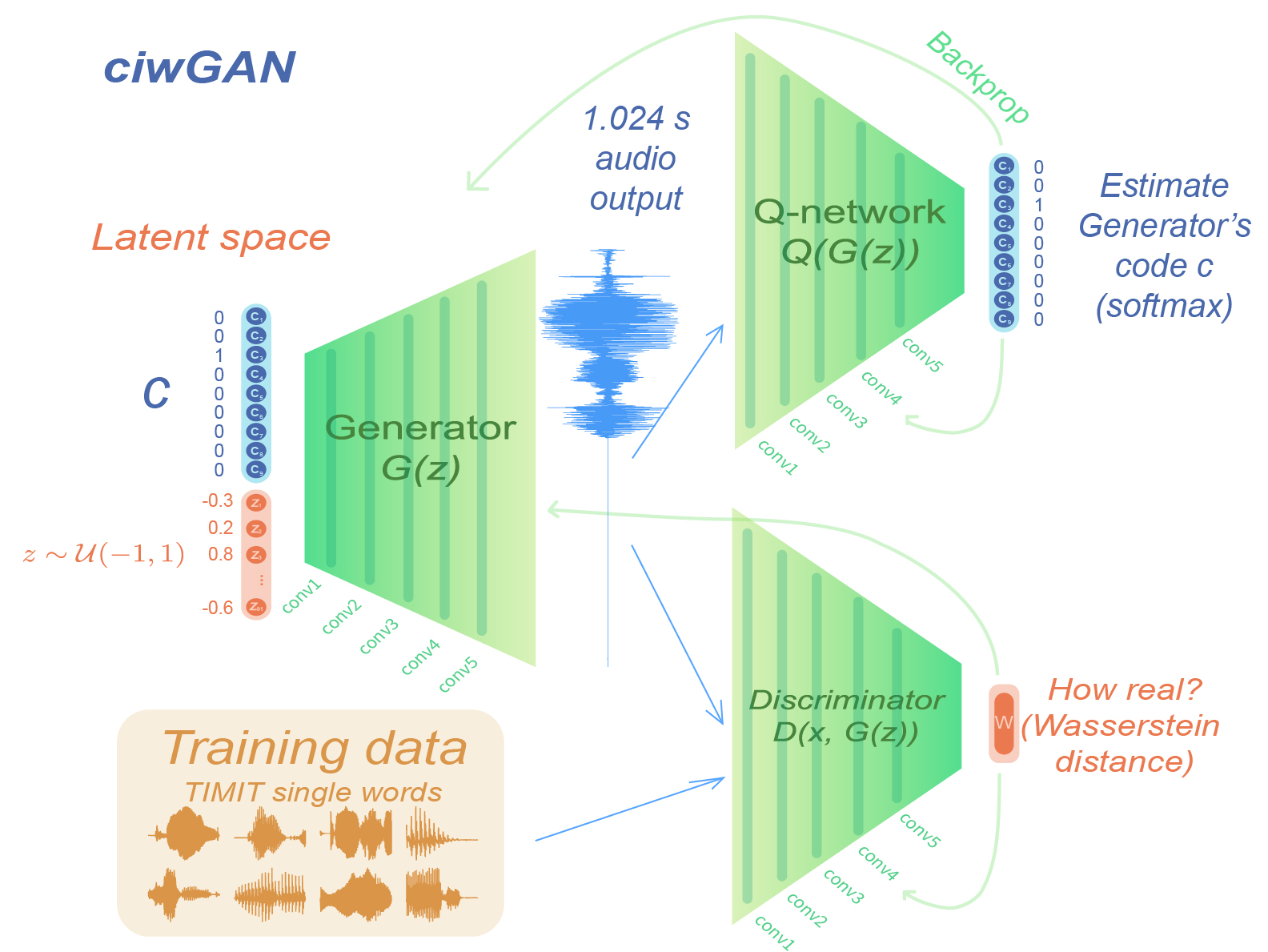
Figure 1: Schematic of ciwGAN architecture, illustrating the bypassing of the FC for generating feature maps from a uniform distribution.
Results
Qualitative and Quantitative Observations
The models with a narrow FC bottleneck successfully produced linguistically interpretable outputs. Specifically, the 8-channel model demonstrated variability and structured waveforms (Figure 2). In contrast, models with the original 1024-channels failed to generate meaningful phonetic patterns, suggesting that the 1024-channel architecture might overfit to its training conditions.
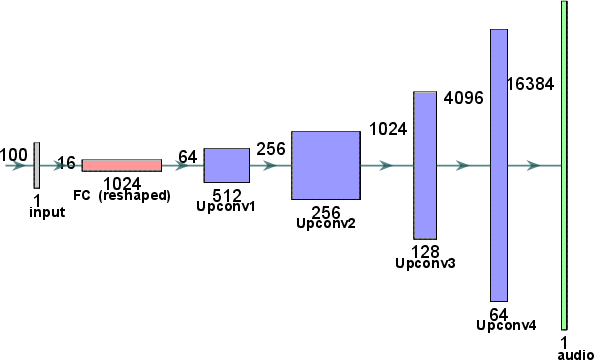
Figure 2: Generator architecture in WaveGAN-based models, highlighting architecture changes from 1024x16 to 8x16.
Phonotactic Generalization
Interestingly, the results revealed that without the FC, the generalization patterns of phonetic dependencies were preserved, demonstrating that the convolutional layers alone can capture certain phonotactic restrictions. This finding was evidenced by consistent VOT measures across the 8-channel model outputs, aligning with the training data (Figure 3).
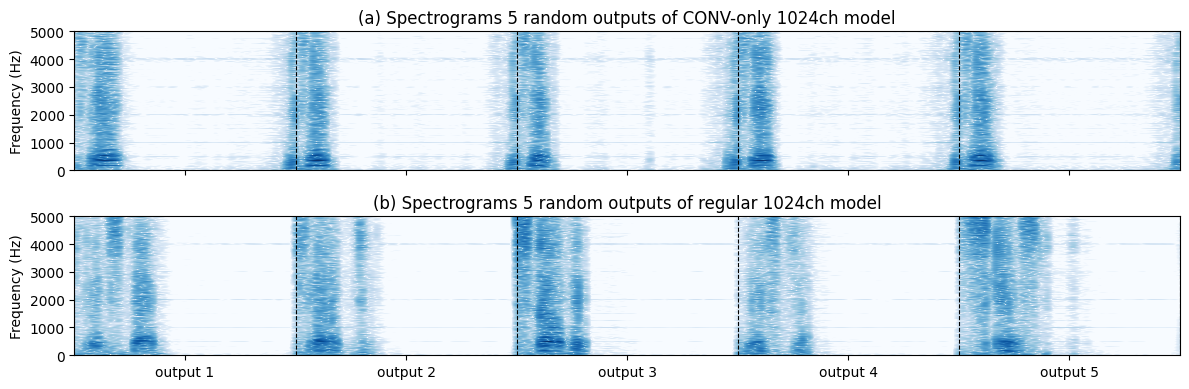
Figure 3: Direct comparison of spectrograms showing the notable difference between 8ch and 1024ch model outputs in Conv-only conditions.
Implications
The results illustrate that convolutional layers can encode phonotactic-like structures independently, aligning with linguistic data even in the absence of FC-imposed lexical structures. This offers an interpretative advantage for phonological cognitive modeling, suggesting that simpler, reduced-dimension FC models might better simulate certain cognitive aspects of speech production. These findings encourage further exploration into reducing model complexity for enhanced interpretability and cognitive realism, particularly in CNNs used for linguistic tasks.
Conclusion
This study presents a novel method for investigating lexically-independent phonetic dependencies in CNNs by modifying the architecture to reduce FC involvement. The evidence suggests convolutional layers effectively model local phonetic patterns, supporting potential applications in linguistic and cognitive modeling. This approach may be expanded further to explore latent space behaviors and interpretability in generative models, advancing our understanding of phonological processing in AI.