- The paper shows that increasing demonstration examples in VLMs often degrades performance under distribution shifts, questioning conventional MM-ICL practices.
- It introduces a MM-ICL with Reasoning pipeline that augments demonstrations with rationales to enhance task-specific learning.
- Experiments reveal limited sensitivity of VLMs to additional reasoning, highlighting a need for more advanced architectures and training methods.
Mimicking or Reasoning: Rethinking Multi-Modal In-Context Learning in Vision-LLMs
Introduction
Vision-LLMs (VLMs) have garnered attention due to their purported ability to perform multi-modal in-context learning (MM-ICL), a process analogous to that seen in LLMs. This paper examines whether current VLMs genuinely engage in in-context learning (ICL) as opposed to relying on superficial patterns like copying or majority voting. The evaluation employs scenarios characterized by distribution shifts wherein the support examples are derived from datasets different from the queries. Contrary to expectations, the performance of VLMs often deteriorates with increased numbers of demonstrations in such settings. This paper introduces a novel MM-ICL with Reasoning pipeline to assess whether providing additional reasoning information could improve model performance. Extensive experiments indicate limited sensitivity of current VLMs to demonstration-level information, thus questioning their effective use of MM-ICL for learning task-specific strategies.
Introduction
Vision-LLMs, similar to LLMs, are presumed to possess ICL capabilities—learning from a few examples embedded in prompts without parameter updates. However, discrepancies arise when these models are exposed to distribution shifts, which simulate real-world user scenarios where support examples belong to datasets distinct from queries. Findings reveal that VLM performance often does not improve with more examples under these conditions, prompting a reassessment of the genuine ICL capabilities of contemporary VLMs in MM-ICL applications.

Figure 1: Left: Performance difference between ID and OOD using random retriever. Middle: Performance of different retrieval methods on OK-VQA. ID: OK-VQA as support set. OOD: TextVQA as support set.
Multimodal In-Context Learning Framework
The paper proposes an MM-ICL with a Reasoning pipeline to address the limitations of current models that fail to effectively use demonstration-level information. It suggests augmenting demonstrations with generated rationales to enrich informational content, intending to enhance a model's capacity to grasp task-solving methodologies rather than superficial details. This methodology aims to bridge the gap identified between true learning and mere pattern matching in VLMs, allowing for more effective multi-modal ICL.
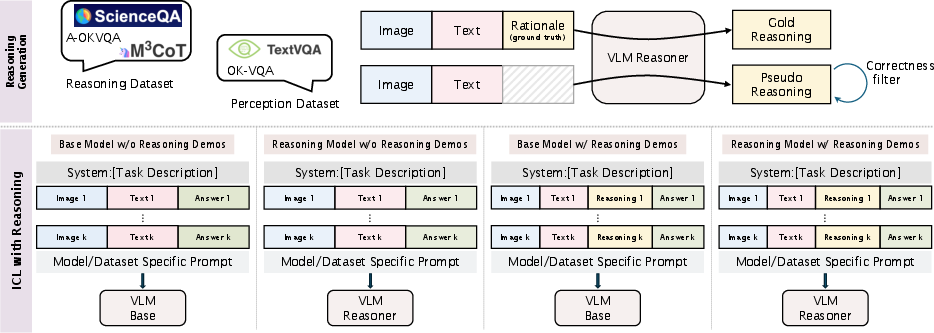
Figure 2: Visualization of Full Pipeline for ICL with VLM Reasoner
Additionally, the paper highlights the importance of the consistent format when integrating reasoning components into prompts for VLMs. Format mismatch can prevent models from effectively utilizing examples if the structure deviates significantly from what the models are trained to handle.
Implications for Perception and Reasoning Tasks
The research divides MM-ICL tasks into two broad classes: Case I, well-defined tasks without demonstrations, includes tasks like Visual Question Answering (VQA) and Image Captioning, where instructions are clear even without examples. In contrast, Case II encompasses ill-defined tasks that require demonstrations for clarity, such as complex reasoning tasks involving operator induction or open-ended object recognition.
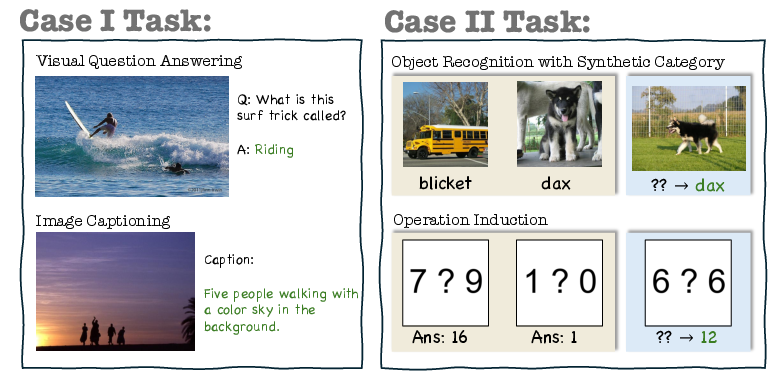
Figure 3: Demonstration of examples from Case I/II tasks. Case II problems are ill-defined if no demos are given.
Reevaluating Multimodal ICL Success
The study further investigates whether the lack of performance enhancement in MM-ICL is due to superficial pattern matching by VLMs, rather than true learning. By testing the models in OOD settings where support examples stem from different distribution datasets, it becomes apparent that accuracy does not consistently benefit from increased demonstration, particularly in settings where the demonstration data is less relevant due to distribution shifts.
One significant factor considered was the response format. Discrepancies in answer formatting between ID and OOD supports could inadvertently influence the performance gains attributed to MM-ICL, with models being sensitive to the answer format rather than content.

Figure 4: Success and failure of MM-ICL with IDEFICS2.
The study suggests that improvements in VLM MM-ICL models can be derived from shifting focus from multimodal ICL performance claims to understanding the underlying mechanisms and improving the models' ability to extract actionable information from examples across varying modalities.
Conclusion
This research underscores the necessity to rethink the MM-ICL capabilities of vision-LLMs against a backdrop of biased assumptions favored by distribution-segmented datasets. Despite advances like reasoning-augmented pipelines, current state-of-the-art VLMs demonstrate minimal sensitivity to enhanced demonstration information, retrieval strategies, and sample size from the support set. This exposes an inherent weakness in the current multi-modal foundation models regarding their learning efficiency from demonstration examples.
Future directions should focus on developing more sophisticated architectures, alongside reasoning-aware retrieval protocols, training methodologies that promote cross-modal reasoning, and evaluation strategies incorporating LLM judges for diverse problem types, to holistically enhance the reasoning capabilities of VLMs. These explorations may facilitate progress towards more generalizable AI systems that can adeptly tackle complex real-world visual-language problems beyond their present capability level.

