- The paper presents TokBench, a benchmark specifically evaluating visual tokenizers on preserving text and facial details using metrics like T-ACC, T-NED, and F-Sim.
- The methodology compares discrete and continuous models under various compression strategies, revealing key performance differences in reconstruction fidelity.
- The findings indicate that continuous VAEs outperform discrete tokenizers, highlighting the need for improved architectures to enhance detailed visual reconstruction.
TokBench: Evaluating Your Visual Tokenizer Before Visual Generation
The paper introduces TokBench, a benchmark designed to evaluate the reconstruction performance of visual tokenizers, with a particular focus on fine-grained features preservation in two challenging visual elements: text and human faces.
Introduction to Visual Tokenization
The advancement of visual generation models, led by autoregressive and diffusion models, has significantly benefited from the use of visual tokenizers. These tokenizers compress images into discrete tokens, enabling sophisticated sequential prediction capabilities. However, current models often encounter significant challenges in preserving fine-grained visual details, especially for human-sensitive content such as text and facial features. TokBench aims to address and evaluate these limitations effectively.
TokBench Dataset and Metrics
TokBench comprises a curated collection of images and video clips enriched with text and facial content. The dataset features a balanced instance-scale distribution, providing a robust ground for evaluating the reconstruction capabilities of visual tokenizers (Figure 1).
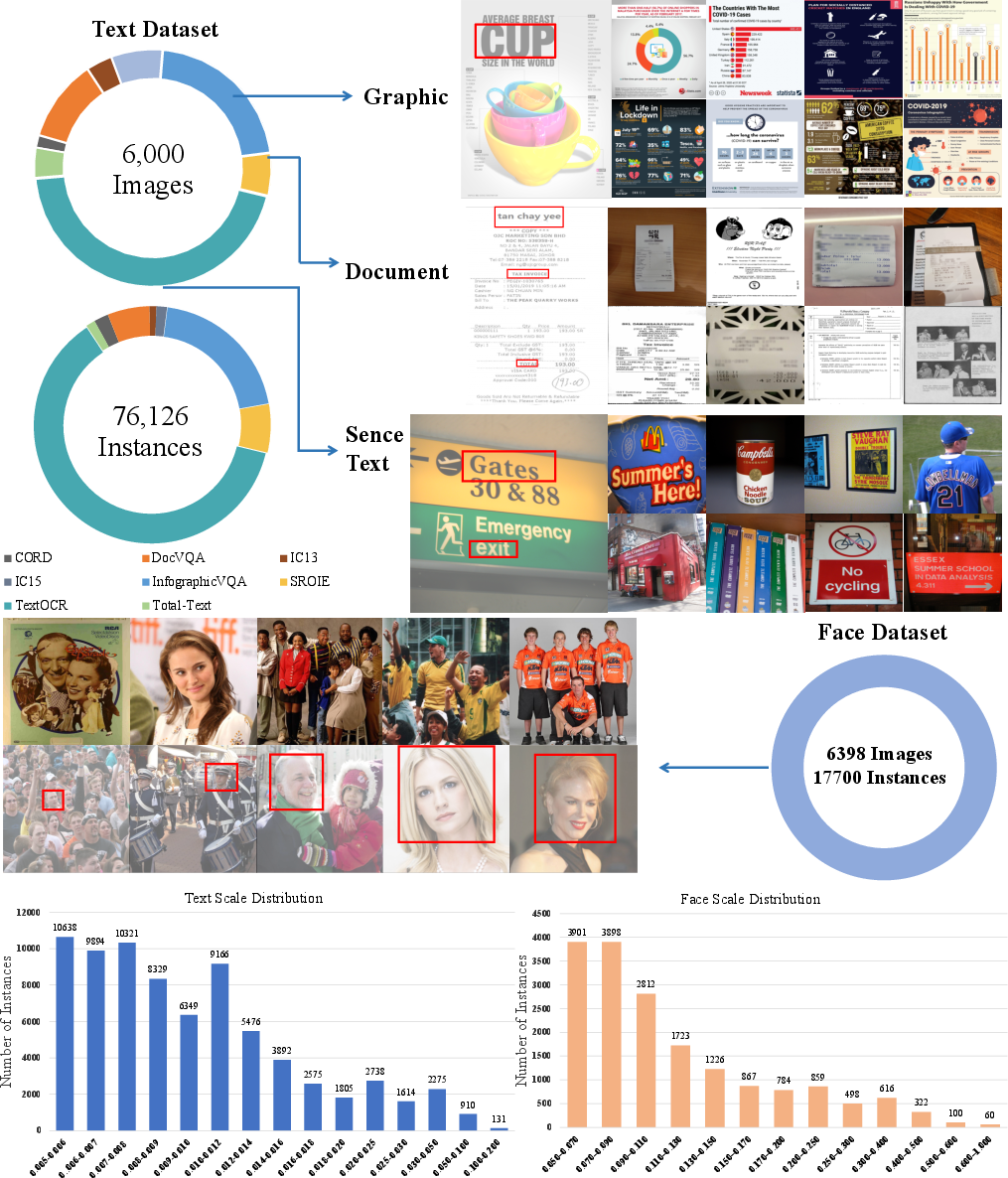
Figure 1: Statistics and Sample Diversity of TokBench-Image. TokBench features a balanced instance-scale distribution with particular emphasis on small-scale face and text instances, presenting significant challenges for existing visual reconstruction approaches.
The benchmark employs specialized metrics to assess reconstruction performance: T-ACC (Text Recognition Accuracy), T-NED (Text Normalized Edit Distance), and F-Sim (Facial Similarity). These metrics focus on readability and identity preservation, diverging from traditional pixel-level and feature-based metrics, which often fail to align with human perceptual assessments (Figure 2).

Figure 2: Comparison of Different Metrics with Human Judgments. In each case, previous metrics (PSNR, SSIM, LPIPS) demonstrate discrepancies with human assessments, whereas our proposed face similarity and text accuracy effectively reflect the reconstruction quality.
Evaluation Framework
TokBench is lightweight, requiring minimal computational resources for evaluation. The benchmark can complete assessments within 4 minutes using just 2GB of memory, offering an efficient and accessible platform for testing visual tokenizers.
Image and Video Analysis
Various approaches to visual tokenization, including discrete VQVAEs and continuous-space VAEs, were evaluated on TokBench. It was demonstrated that continuous VAEs like SD3.5 and FLUX significantly outperform discrete models, particularly in text and face reconstruction tasks (Figure 3).
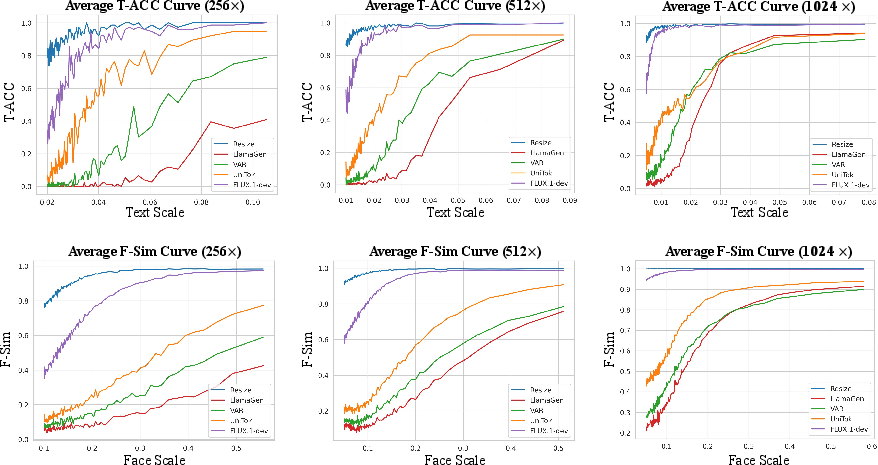
Figure 3: T-ACC and F-Sim metrics across reconstruction resolutions versus target scales. Smaller scales present greater challenges, and even the best-performing VAE show gap for improvement when compared to the ``resize'' upper bound.
Current discrete tokenizers exhibit insufficient performance due to information loss during vector quantization, especially at smaller scales. In contrast, continuous models handle reconstruction fidelity more effectively but still show room for improvement compared to theoretical upper bounds.
Ablation Studies and Additional Insights
Additional experiments revealed that adding text-rich data to training improved performance, although the enhancements were moderate, indicating that architectural design holds more significance than the training dataset composition.
A detailed examination of video tokenization further confirmed that excessive compression in both spatial and temporal dimensions compromises reconstruction quality. Nonetheless, models like Hunyuan-Video and CogVideoX exhibit commendable performance even under competitive compression settings.
Conclusion
TokBench provides an innovative benchmark explicitly tailored to evaluate visual tokenizers' reconstruction quality with a focus on text and facial features. It complements traditional evaluation metrics by offering a more pertinent assessment aligned with human perceptual standards. The results emphasize the need for improved architectures capable of preserving critical hierarchies of visual details, pointing towards potential research directions in model architecture and training methodologies. The paper serves as a crucial resource for advancing developments in visual tokenization and reconstruction fidelity.

