- The paper addresses benchmarking inconsistencies by introducing explicit reward version control and standardized APIs to ensure reproducible multi-task evaluations.
- It demonstrates that V2 rewards, with normalized returns, significantly improve convergence and success rates across various RL algorithms.
- The introduction of intermediate benchmarks (MT25/ML25) and custom task sets enables detailed ablation studies and scalable evaluations for advancing RL research.
The paper "Meta-World+: An Improved, Standardized, RL Benchmark" (2505.11289) directly addresses longstanding issues in multi-task and meta-reinforcement learning (RL) benchmarking with Meta-World, a suite widely used for evaluating agents on diverse robotic manipulation tasks. RL research's demand for agents capable of transferring and generalizing across tasks has led to heavy reliance on benchmark environments for empirical advancement. However, Meta-World has accumulated undocumented modifications and version mismatches—particularly in reward functions—undermining fair algorithmic comparison and impeding progress towards generalizable RL.
The work focuses on repairing this fragmented landscape by: i) providing empirical clarity on how reward version drift distorts performance evaluation, ii) introducing implementation and API improvements enabling explicit control and reproducibility, and iii) expanding the diversity and flexibility of benchmark task sets. These interventions are essential for the community to compare advances in multi-task and meta-RL under controlled conditions.
Benchmark Design, Reward Scaling, and Version Discrepancy
A key empirical contribution involves disentangling the historical confusion between the V1 and V2 reward function families. The initial V1 rewards were constructed through sequential task mutation, leading to wide intra-task return magnitude variability and optimization inconsistencies. V2 rewards, in contrast, leverage fuzzy geometric constraints to ensure returns are both Markovian and approximately normalized across tasks, motivated by the observation that reward scale inconsistency impedes stable multi-task learning dynamics. This decision aligns with prior evidence that that performance and representation sharing in multi-task RL are highly sensitive to reward scaling and gradients' inter-task directional alignment.
The paper illustrates these discrepancies and their impact through learning curves and per-task return statistics.
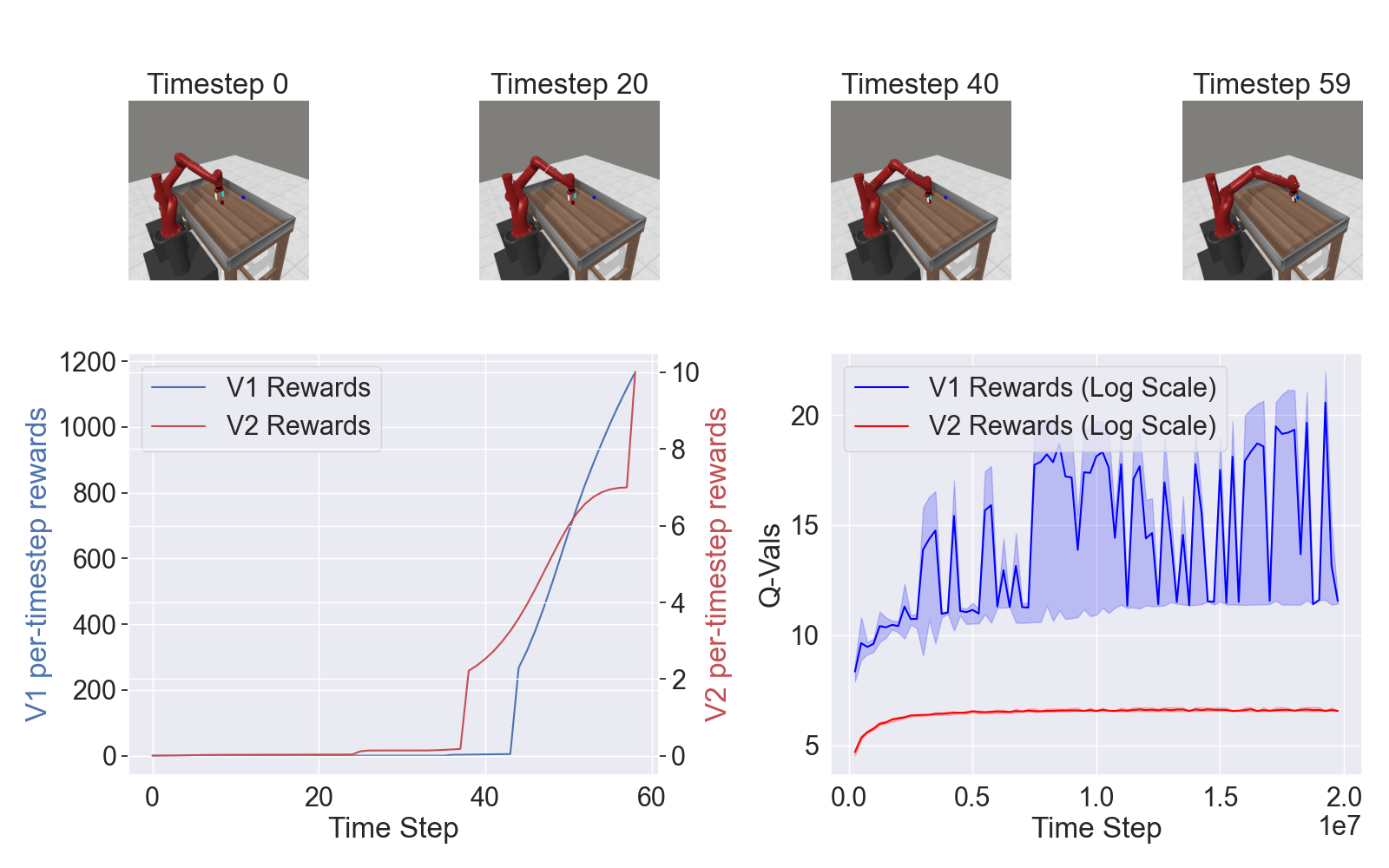
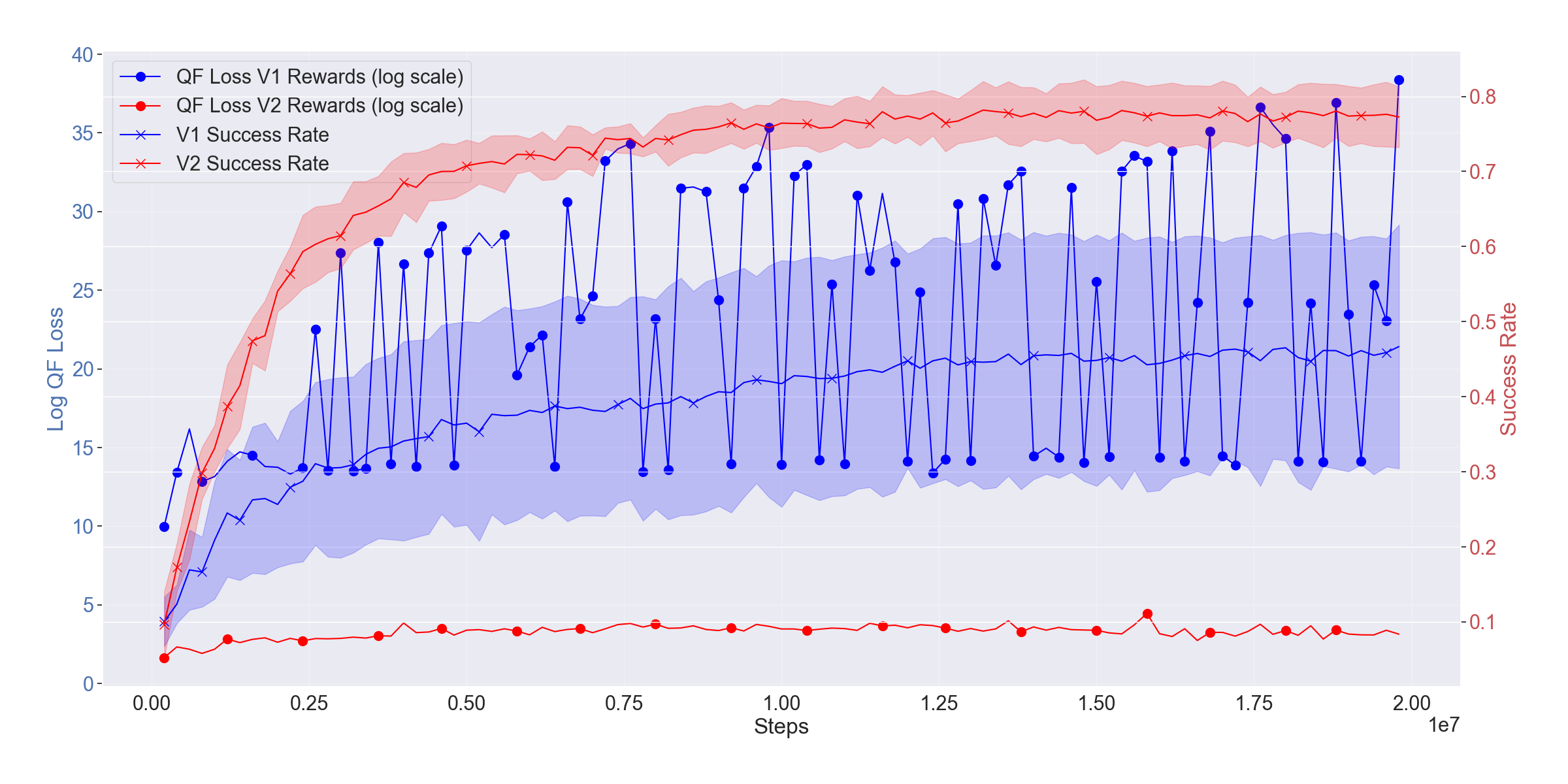
Figure 1: Tasks included in Meta-World, illustrating the breadth of Sawyer-based manipulation scenarios targeted by multi-task and meta-RL approaches.
Detailed comparisons of learning dynamics further demonstrate how V2 rewards enhance optimization:
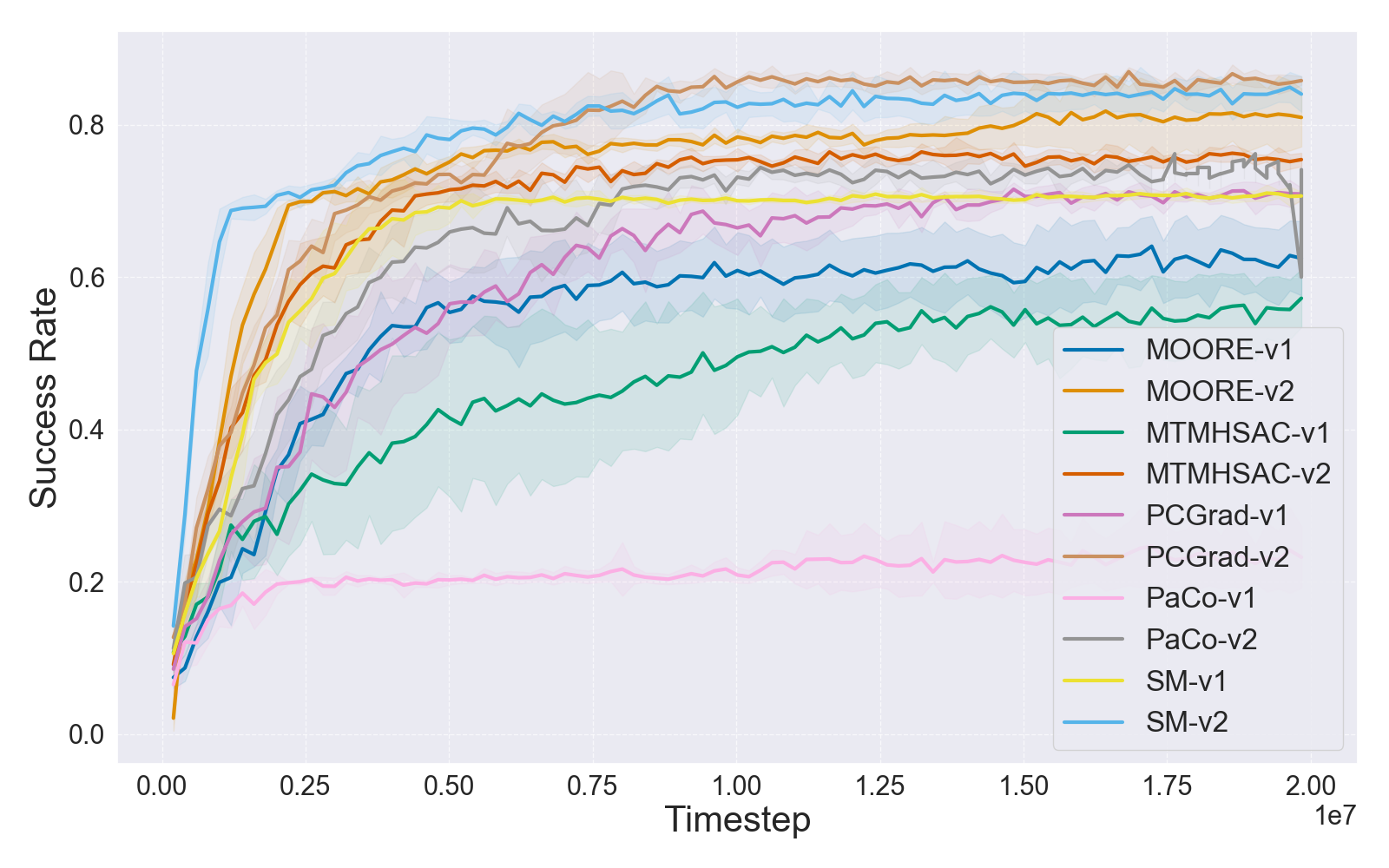
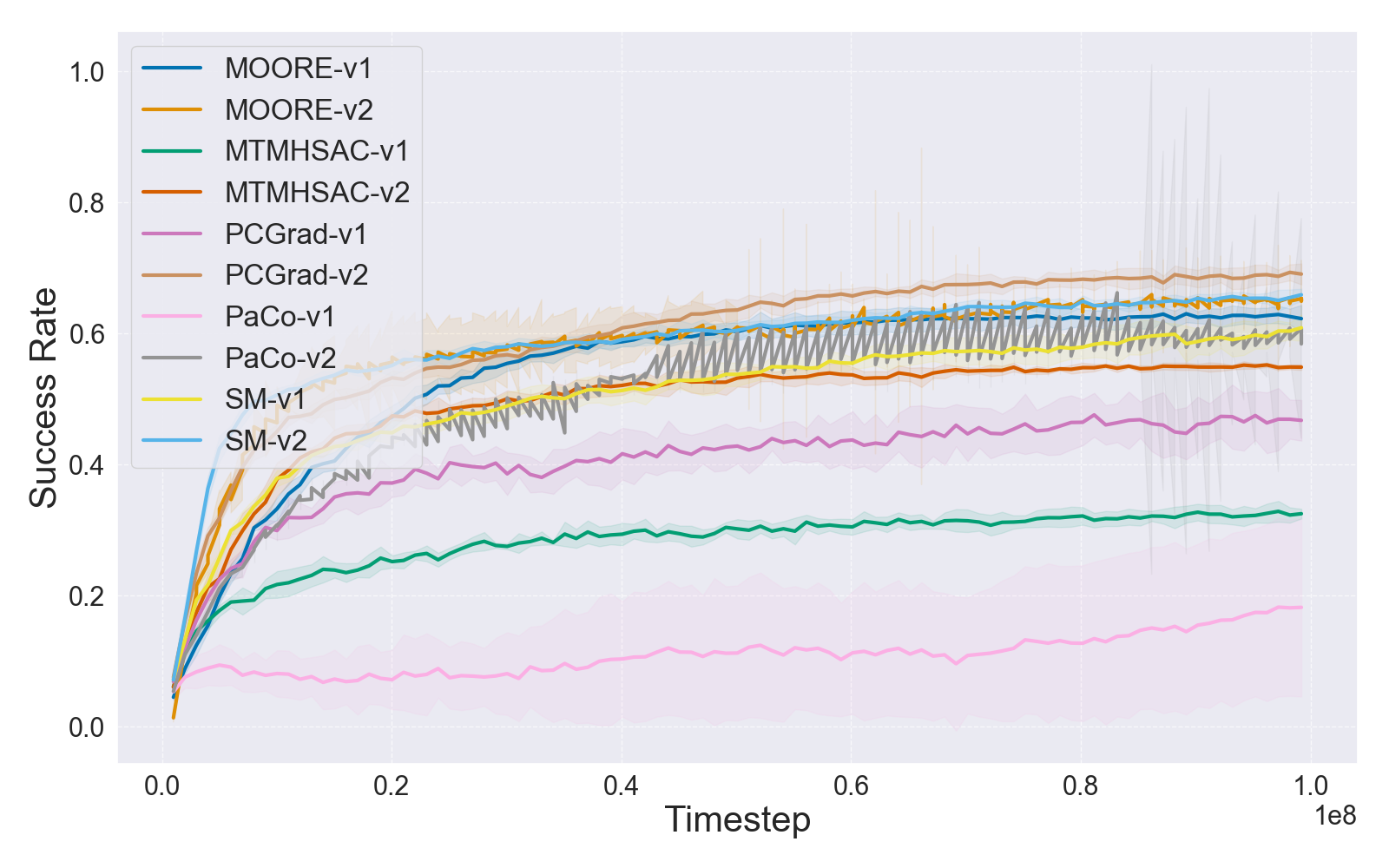
Figure 2: Per-timestep rewards (V1 vs. V2) for pick-place and corresponding Q-function loss and mean success rates for MTMHSAC, evidencing superior convergence and success rates with V2.
Empirical results on MT10 and MT50 reveal that all tested state-of-the-art multi-task algorithms (PCGrad, Soft Modularization, Parameter Compositional, MTMHSAC, MOORE) achieve significantly higher mean success rates under V2. Optimization becomes increasingly difficult as the number of tasks increases or reward scales diverge, confirming the brittle nature of multi-task RL under arbitrary reward normalization.
Learning curves for both small (MT10) and large (MT50) benchmarks solidify the claim that reward function drift misguides comparative evaluation and can invert perceived method rankings.
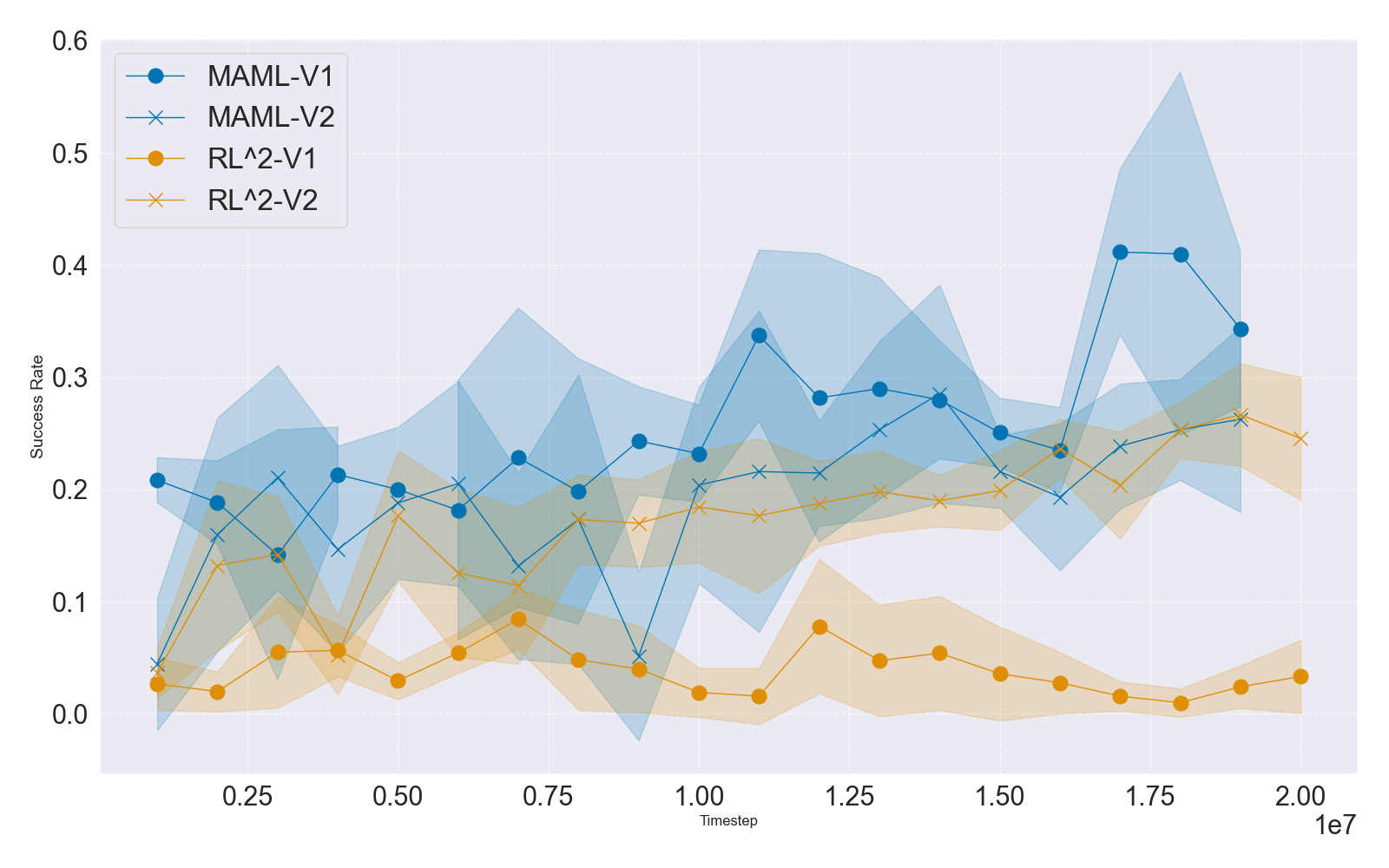
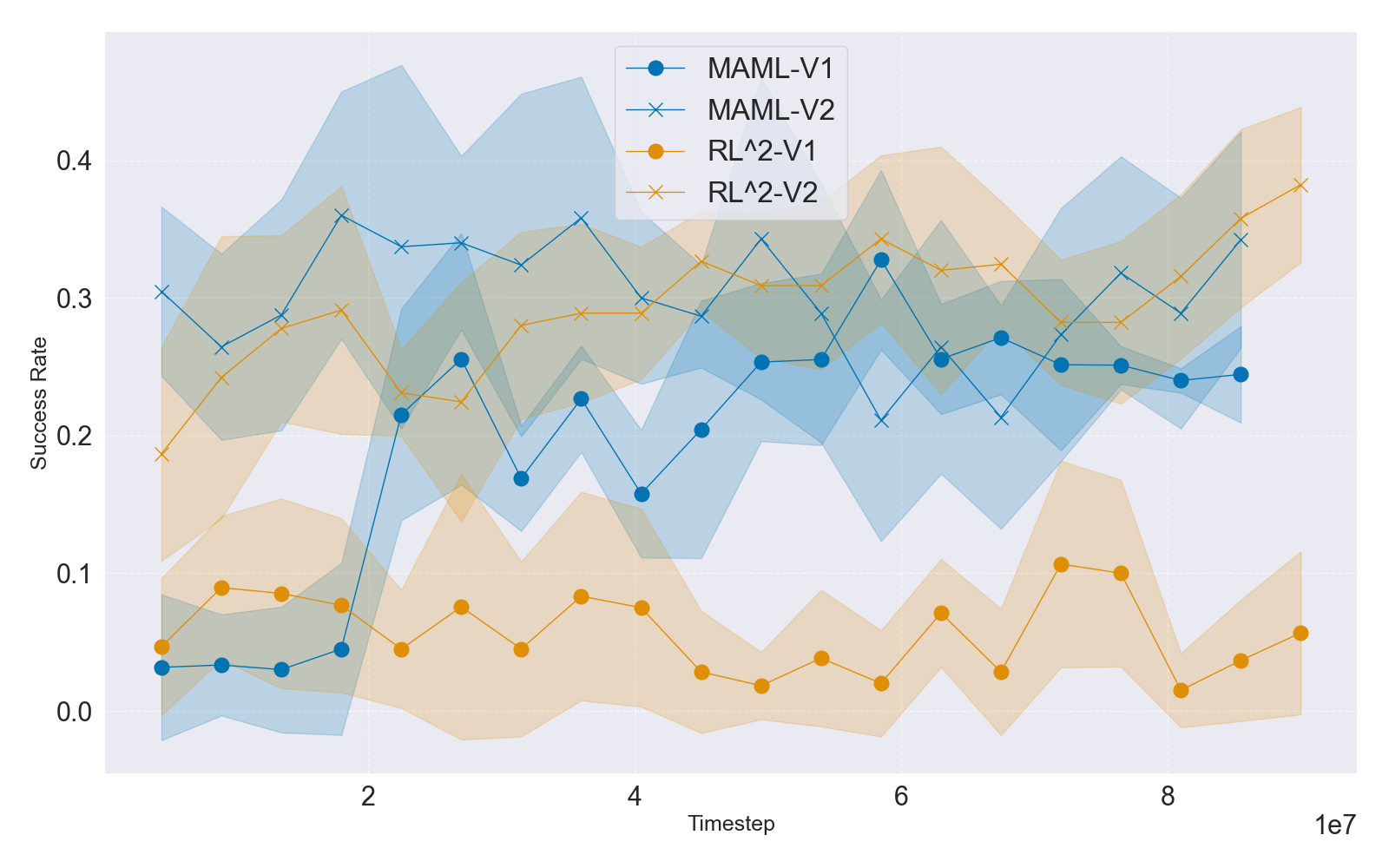
Figure 3: IQM learning curves for MT10 and MT50 task sets under V1 and V2 rewards, indicating boosting effect of V2 reward normalization on performance and convergence.
The study further investigates meta-RL, focusing on Model-Agnostic Meta-Learning (MAML) and RL2, in the ML10 and ML45 settings. Unlike value-based multi-task RL (heavily reliant on Q-function stability), meta-RL methods—using policy gradients and linear feature baselines—demonstrate relatively muted sensitivity to reward versioning, except when raw episode rewards (as in RL2) leak into observation spaces, causing optimization failures for non-normalized rewards. Nonetheless, overall success rates remain modest, with most algorithms struggling with both parametric and class diversity expansion in ML10/ML45.
Success rate trajectories over task set sizes and reward families provide strong evidence that the major bottleneck in meta-RL remains generalizing beyond parametric/task variation, an observation concordant with recent transformer-based approaches [grigsby2024amago].
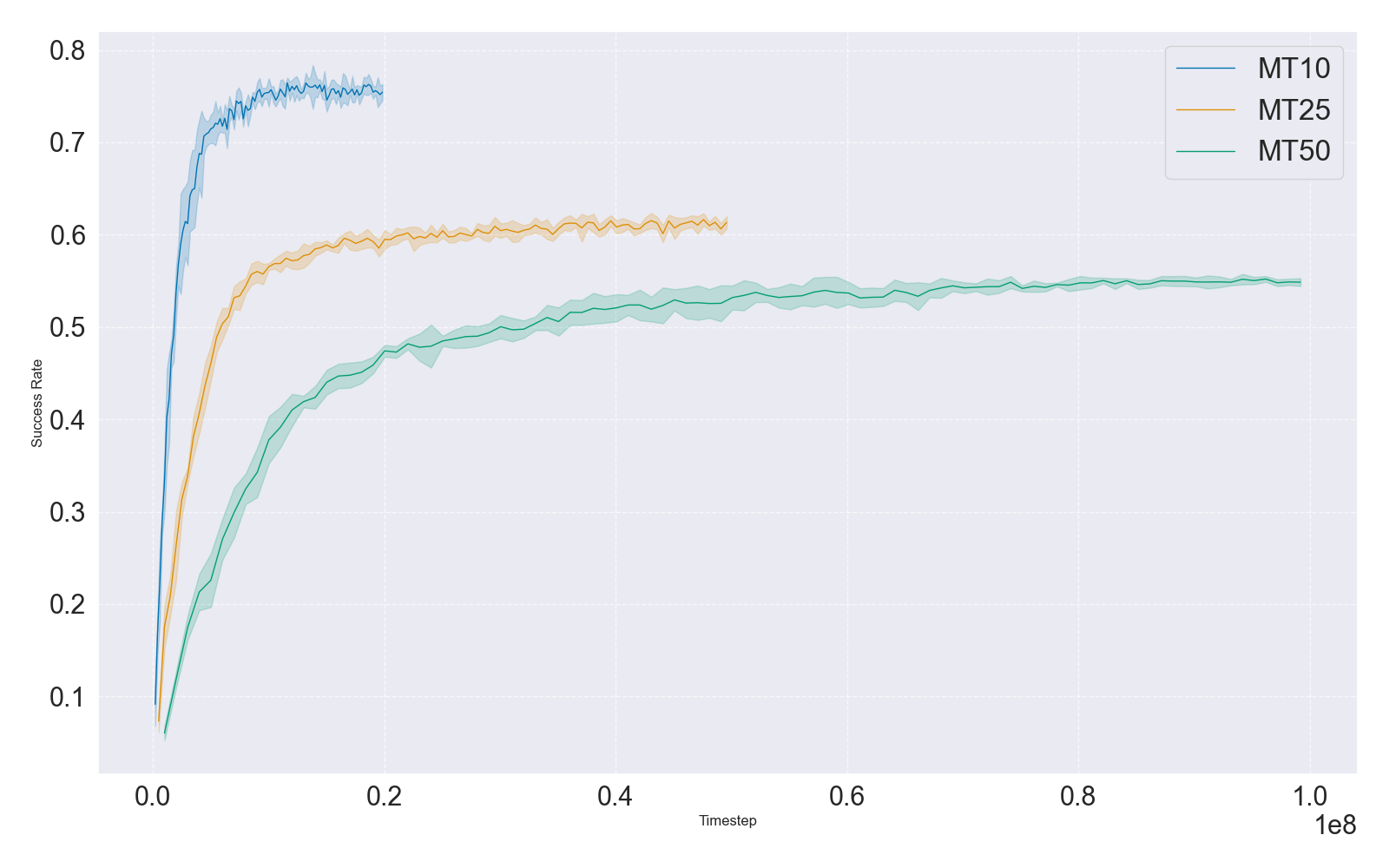
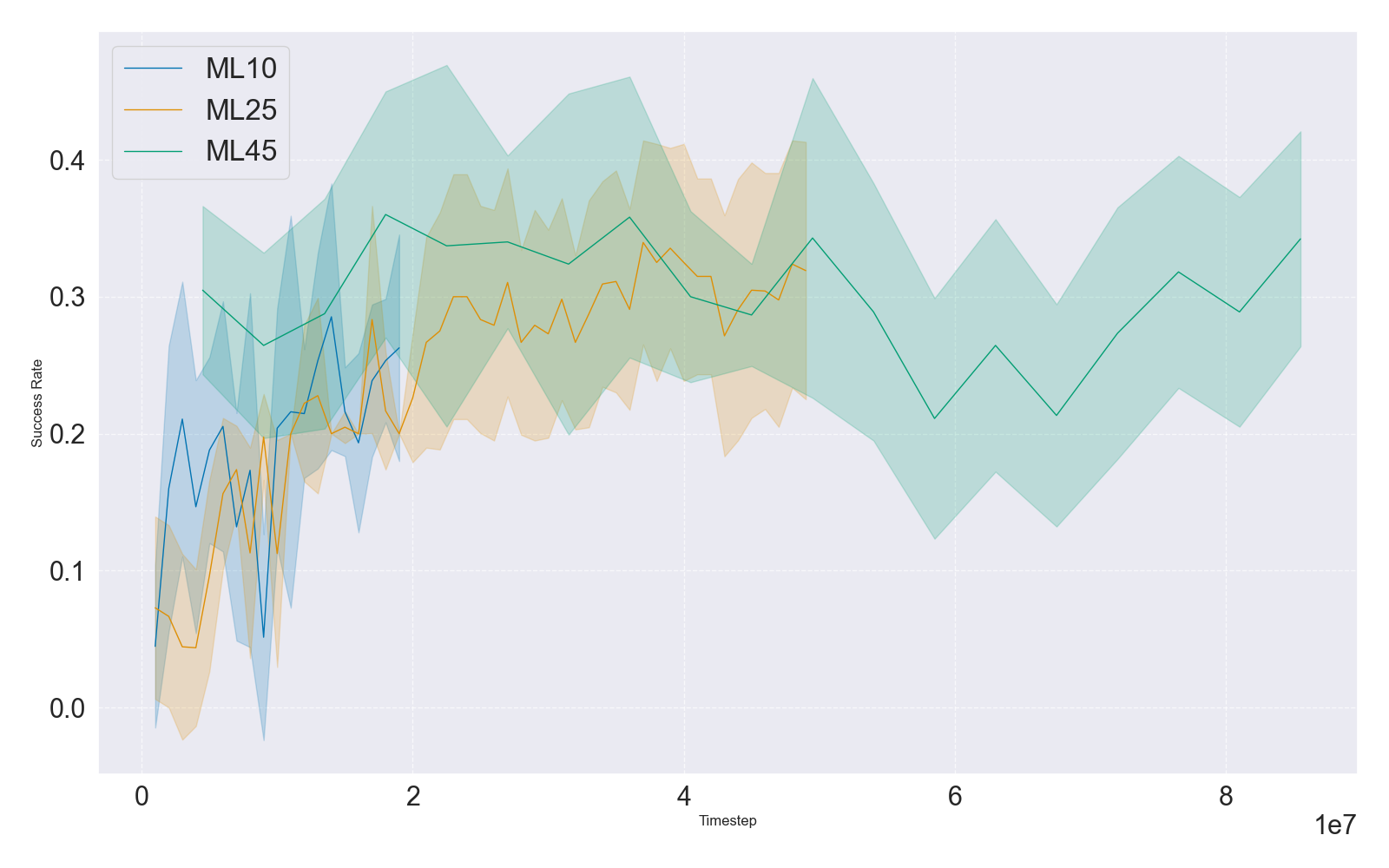
Figure 4: IQM-based mean test success rates during ML10/ML45 benchmark training for MAML and RL2 with V1/V2 rewards, underscoring muted reward sensitivity but overall low generalization.
Impact of Task Set Size and Customization
To mediate computational cost and benchmarking flexibility, the work introduces new MT25 and ML25 benchmarks and supports user-defined custom task sets. The introduction of intermediate-sized benchmarks (MT25/ML25) mediates sample complexity and enables more granular ablation studies, rapid prototyping, and fine-tuned investigation of transfer and generalization.
Scaling experiments indicate that as task-set size increases, success rates for fixed-capacity networks decline, implicating model capacity and architecture choice as prevailing obstacles. This insight directs future method development towards architectural innovations or parameter scaling regimes compatible with continually growing task distributions.

Figure 5: Success rates in multi-task (MTMHSAC) and meta-RL (MAML) as a function of task set size (MT10/25/50, ML10/25/45), demonstrating rate drop-off in multi-task setting due to capacity bottlenecks and relative insensitivity for MAML in meta-RL.
API, Integration, and Reproducibility
A critical design improvement involves the integration of Meta-World with the Gymnasium API, displacing previous ad hoc interfaces and ensuring compatibility with widely adopted RL pipelines. The new API permits explicit reward version selection, seamless creation of custom benchmarks, and direct backward compatibility with legacy Meta-World results. The result is a standardized codebase ensuring that all future empirical claims are directly traceable to the explicit benchmark configuration.
Implications and Future Directions
The findings of this work entail several crucial implications. First, benchmark codebases that fail to enforce explicit versioning and clear documentation create irreproducible research environments and can result in erroneous or misleading conclusions about algorithmic advance. This motivates a norm wherein benchmark releases emphasize transparent versioning, reward function discipline, and comprehensive reporting to foster robust cumulative science in RL.
Second, the demonstrated impact of reward normalization necessitates that future benchmarks systematically calibrate and document reward construction. Furthermore, compositional task sets and attributes such as embodiment diversity, reward type heterogeneity, and instruction-following (including language-induced) tasks can now be more systematically explored within the new Meta-World+ infrastructure. This opens promising directions for research at the intersection of representation learning, curriculum design, and synthetic skill composition.
From a theoretical perspective, the clear link between successful multi-task RL and Q-value estimation accuracy under normalized reward distributions provides motivation for enhanced architectures (e.g., mixture-of-experts, modular Q-networks) consistent with continual learning findings [mclean2025multitask, obando-ceron24b]. In meta-RL, the limited progress observed reinforces the necessity for methods that can interpolate between parametric variation and open-ended compositionality, potentially integrating domain randomization and transformer-based architectures.
Conclusion
Meta-World+ (2505.11289) establishes a rigorous benchmark foundation for multi-task and meta-RL, resolving longstanding obstacles to systematic algorithmic comparison. By providing explicit reward version control, streamlined and standardized APIs, and expanded task diversity, the work enables legitimate empirical progress critical to advancing generalizable RL. The presented analyses conclusively demonstrate that variations in benchmark construction (especially reward scaling) can overshadow genuine algorithmic effects, emphasizing the necessity for explicit versioning and open protocol documentation. As a result, Meta-World+ not only advances experimental practice but also lays the groundwork for disciplined research on task compositionality and cross-domain RL transfer.