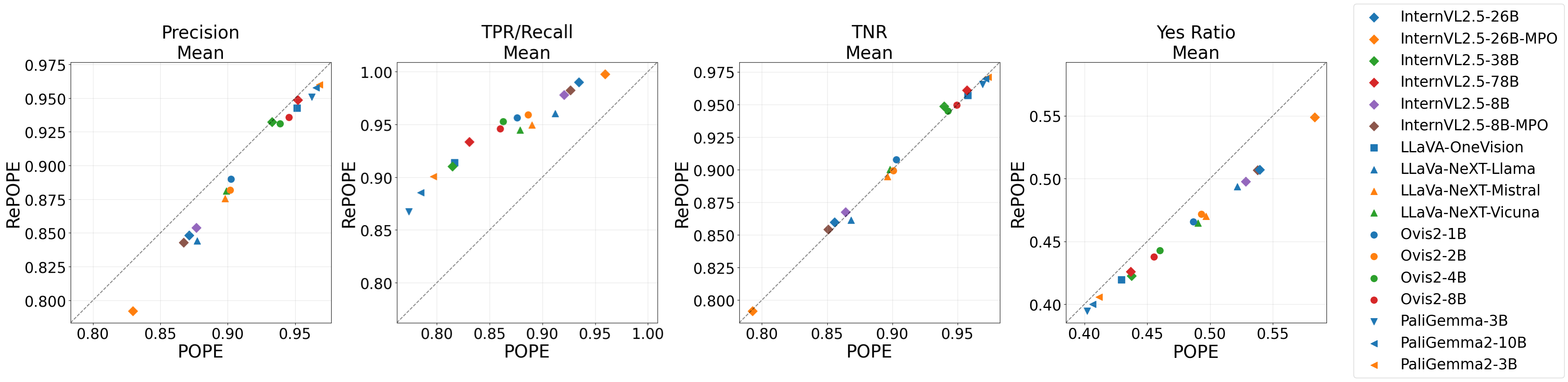
- The paper introduces RePOPE, a re-annotation of POPE that corrects MSCOCO errors to better assess object hallucination in vision-language models.
- It employs a consensus-based labeling method (Yes, No, Ambiguous) revealing significant changes in F1 scores and model rankings.
- Results emphasize that improved label quality markedly affects model performance, underscoring the need for meticulous dataset curation.
Overview of the Paper "RePOPE: Impact of Annotation Errors on the POPE Benchmark" (2504.15707)
The paper introduces RePOPE, a revised label set for the frequently used object hallucination benchmark, POPE, and evaluates the impact of annotation errors from the MSCOCO dataset on model rankings. By re-annotating benchmark images, this research identifies significant shifts in model rankings when using RePOPE, emphasizing the importance of label quality in performance evaluation.
Introduction to POPE and RePOPE
The POPE benchmark is commonly utilized in evaluating object hallucinations of Vision-LLMs (VLMs). It involves a binary classification task where models are asked if a specified object is present in an image. The benchmark is primarily based on 500 images from the MSCOCO dataset, recognized for exhaustive annotation of 80 object classes but known to contain annotation errors. The paper introduces RePOPE, which re-annotates these images to correct label errors and assesses the impact of these corrections on model performance.



Figure 1: RePOPE annotation examples demonstrating errors and inconsistencies in the original POPE labels.
Methodology
Construction of RePOPE
RePOPE is constructed by re-annotating all images from POPE, assigning labels of "Yes", "No", or "Ambiguous", relying on consensus from two human labelers. The ambiguity arises in cases where object presence is subjective or inconsistently annotated in MSCOCO, leading to significant revisions in the dataset.
Evaluation Approach
Models are evaluated on both POPE and the revised RePOPE label sets. This allows a comparative analysis of the effect of annotation errors. The evaluation considers different subsets of data: random, popular, and adversarial, based on how non-annotated objects are selected.
Experimental Results
The findings reveal notable changes in performance metrics, particularly in F1 scores and ranking of models when evaluated on RePOPE versus POPE:
- True Positives (TP) and False Positives (FP): Re-labeling substantially decreased TPs across all models while showing varying effects on FPs, especially in the adversarial subset where FPs decreased slightly due to a higher prevalence of true object presence errors (Figure 2).
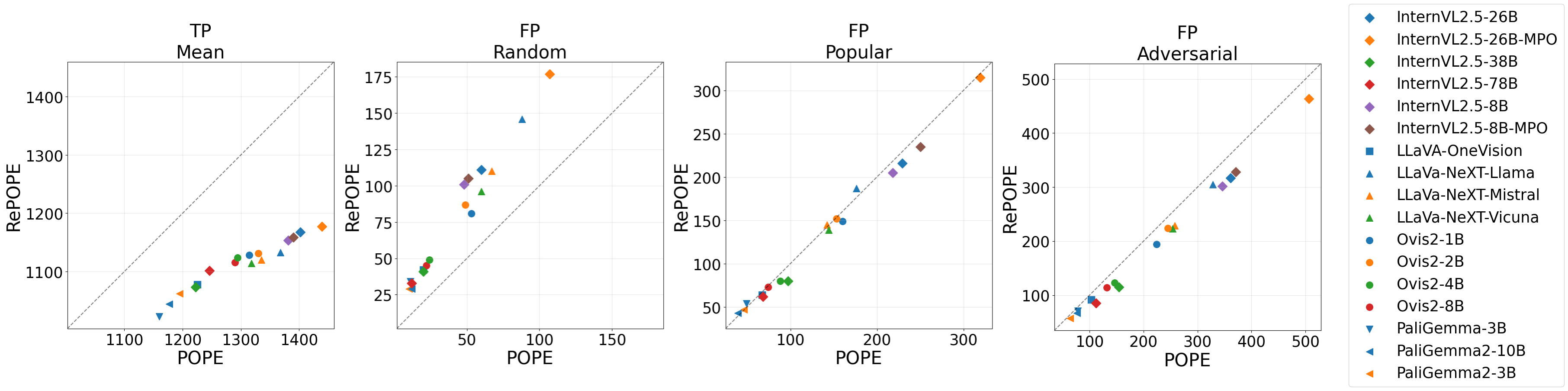
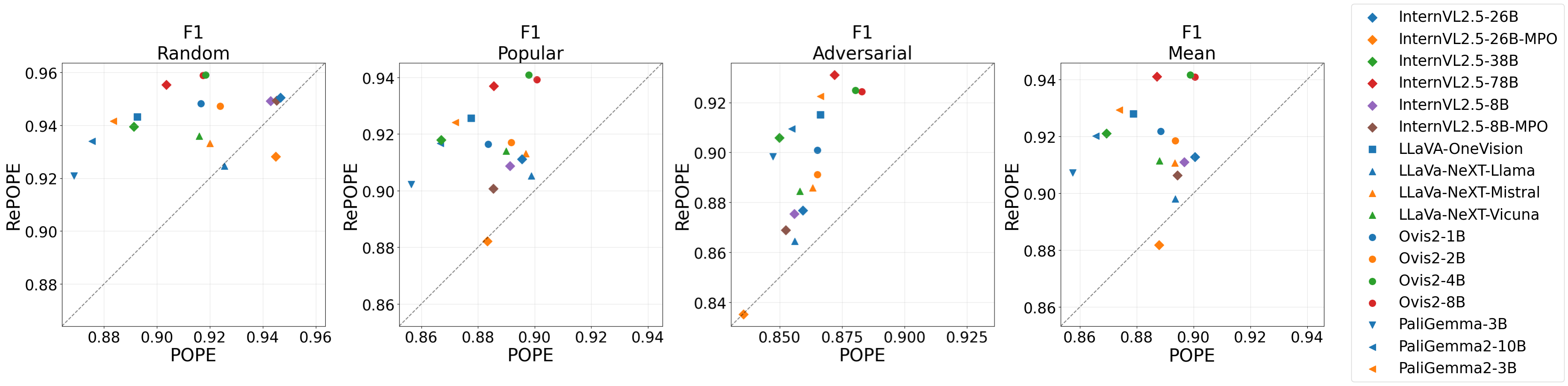
Figure 2: POPE vs. RePOPE displaying significant reductions in TP and variable patterns in FP across subsets.
Implications of the Research
The study highlights the critical role of accurate data labeling in benchmarking VLMs and detecting object hallucinations. The introduction of RePOPE offers a more reliable means to assess model vulnerabilities and suggests that reliance on datasets like POPE might lead to misleading evaluations due to annotation errors.
The re-annotated dataset impacts benchmark saturation and suggests evaluating additional benchmarks such as DASH-B for more comprehensive assessments.
Conclusion
RePOPE corrects annotation errors within POPE, extensively affecting the F1 rankings of evaluated models. This reveals the dependency of VLM performance evaluations on the quality of dataset annotations, thereby necessitating improvements in dataset curation. Subsequent studies are encouraged to build upon this revised benchmarking methodology to ensure more robust model evaluations.
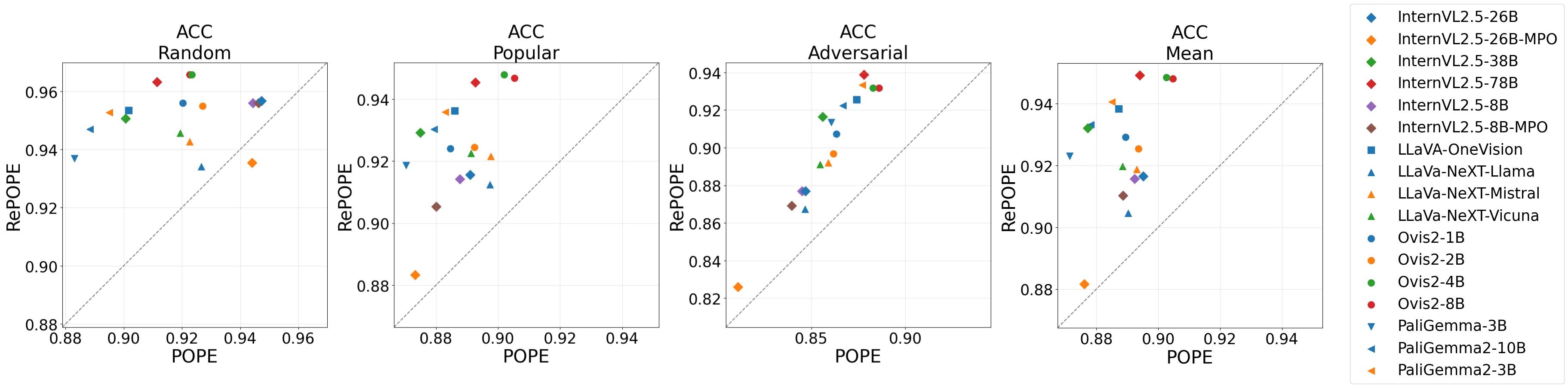
Figure 4: POPE vs. RePOPE highlighting how accuracy measurements need careful interpretation due to the imbalance in RePOPE.