- The paper identifies limitations in current MLLMs, highlighting deficiencies in spatial annotations and position embeddings critical for relational reasoning.
- The paper proposes novel recipes including enriched training data and hybrid embedding techniques to improve both relational and transformation reasoning.
- Empirical evaluations on models like Qwen-2VL demonstrate that new training objectives and architectural modifications yield improved performance in spatial tasks.
Advancing Spatial Reasoning in Multimodal LLMs
The paper "Scaling and Beyond: Advancing Spatial Reasoning in MLLMs Requires New Recipes" (2504.15037) addresses the limitations in spatial reasoning capabilities of Multimodal LLMs (MLLMs) and proposes new development approaches to enhance these capabilities.
Introduction
Multimodal LLMs (MLLMs) have shown promising results in general vision-language tasks but exhibit significant shortcomings in spatial reasoning. Spatial reasoning, a critical component of human cognition, involves understanding and reasoning about spatial relationships among objects and their interactions in the environment. Current strategies focusing solely on scaling existing architectures fail to naturally instill these capabilities into MLLMs. Instead, this paper calls for foundational changes in the development approaches, covering training data, architecture design, and reasoning strategies to improve spatial reasoning.
Spatial Reasoning Framework
The study breaks down spatial reasoning in MLLMs into two primary capabilities: Relational Reasoning and Transformation Reasoning. Relational Reasoning involves understanding spatial relationships (e.g., positional and orientational) between objects. On the other hand, Transformation Reasoning addresses dynamic changes in spatial configurations like rotations and translations. Together, these capabilities form a comprehensive framework needed for MLLMs to interact effectively with our physical world.
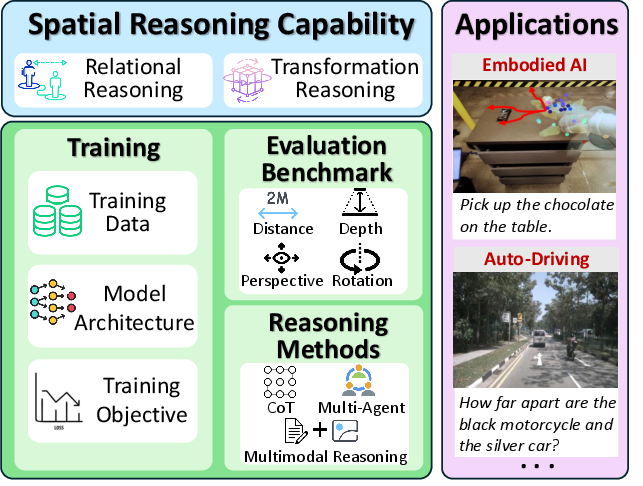
Figure 1: By defining spatial reasoning in MLLMs and analyzing limitations in the current recipe, we advocate for new recipes to enhance spatial reasoning, unlocking the potential for applications.
Training Data and Architectural Considerations
Training Data
The paper highlights critical deficiencies in current pre-training datasets, particularly in spatial annotations. Standard datasets like LAION-2B and CC-3M provide insufficient spatial context, impacting models' ability to perform relational reasoning. The authors suggest incorporating richer spatial annotations and considering alternative spatial representation schemes, such as topological ones, to overcome current limitations.
Model Architecture
The architecture of MLLMs plays a vital role in spatial reasoning. The vision encoder, connector, and LLM backbone need enhancements to better retain and process spatial information. The vision encoder depends heavily on position embeddings to maintain spatial context. Current methods like Absolute and Relative Position Embeddings show limitations in handling spatial transformations. Innovative solutions are needed, such as hybrid embedding methods that cover both absolute and relative aspects.
Connector and Backbone
Connectors are crucial for preserving spatial fidelity when aligning visual and language modalities. Novel connectors that balance information preservation and computational efficiency are necessary. The focus also needs to shift towards enhancing position embeddings and designing attention mechanisms that align with the spatial information processing needs in the LLM backbone.
Training Objective and Evaluation
The current training objectives like cross-entropy loss fail to incorporate spatial constraints necessary for effective spatial reasoning. The integration of multimodal supervision during training remains largely unexploited. The paper suggests exploring spatially aware loss functions that can guide models to better understand and reason about spatial arrangements.
Existing evaluation benchmarks do not sufficiently correlate MLLMs' spatial reasoning capabilities with real-world applications. The authors propose developing comprehensive evaluation frameworks that link improved spatial reasoning directly to performance in practical scenarios like Embodied AI.
Reasoning Methods and Case Study
Recent advancements in reasoning methods, including multimodal reasoning traces and agentic reasoning, expand traditional approaches limited to direct prediction. Multimodal Visualization-of-Thought is proposed, which offers new avenues for MLLMs to incorporate more explicit reasoning paths.
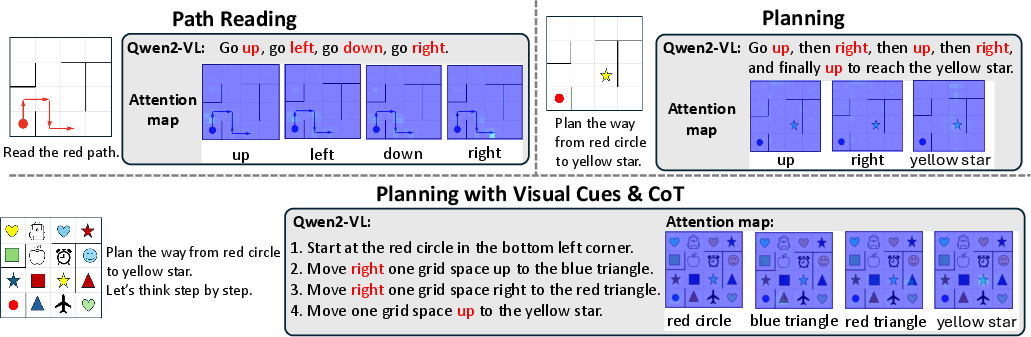
Figure 2: The responses and attention visualization of Qwen-2VL on path reading and planning tasks. The attention maps provide insights into the model's spatial reasoning ability, highlighting how it attends to visual elements during task execution.
A case study involving Qwen-2VL and LLaVa 1.5 models highlights both successes and limitations in spatial reasoning tasks like Path Reading and Planning. The study illustrates how current models predominantly focus on object-level information, supporting the need for new recipes to improve spatial reasoning.
Conclusion
This paper identifies critical gaps in current MLLM methodologies concerning spatial reasoning capabilities. It argues for new recipes in architecture design, training data, and training objectives to substantially enhance MLLMs' spatial reasoning prowess. Addressing these gaps will allow MLLMs to achieve more human-like interaction and understanding in complex, spatially nuanced environments, paving the way for their application in increasingly diverse and demanding real-world scenarios.