- The paper introduces a bSQH algorithm that reformulates CNN training as an optimal control problem using a discrete-time Pontryagin maximum principle.
- The algorithm employs layered forward and backward sweeps to maximize an augmented Hamiltonian, ensuring loss reduction without classical gradients.
- Numerical results show that the method achieves high sparsity and computational efficiency, making it suitable for resource-constrained applications.
The Pontryagin Maximum Principle for Training Convolutional Neural Networks
Introduction
The paper "The Pontryagin Maximum Principle for Training Convolutional Neural Networks" introduces a batch sequential quadratic Hamiltonian (bSQH) algorithm for training convolutional neural networks (CNNs) using L0-based regularization. This algorithm leverages a discrete-time Pontryagin maximum principle (PMP) framework to optimize CNN training processes, particularly focusing on sparsity and computational efficiency. The key innovation involves forward and backward sweeps with layer-wise approximate maximization of an augmented Hamiltonian function.
Methodology
Theoretical Framework
The bSQH algorithm is grounded in the discrete-time Pontryagin maximum principle, enabling the formulation of optimal control problems in the neural network training context. It uses a Hamilton-Pontryagin (HP) function to derive optimality conditions without differentiability assumptions. This approach diverges from classical gradient-based methods by employing a generalized backpropagation algorithm that maximizes an auxiliary Hamiltonian function across network layers.
Algorithm Implementation
The bSQH algorithm is implemented through iterative updates involving sequence approximations. The strategy includes augmenting the Hamiltonian function to enforce the convergence of solutions, with the augmentation parameter selected adaptively. This method ensures monotonic decrease in loss functional value, facilitating efficient parameter updates without relying on gradient information. Specifically, the bSQH algorithm can accommodate non-continuous regularizers and handle discrete parameter spaces.
Numerical Results
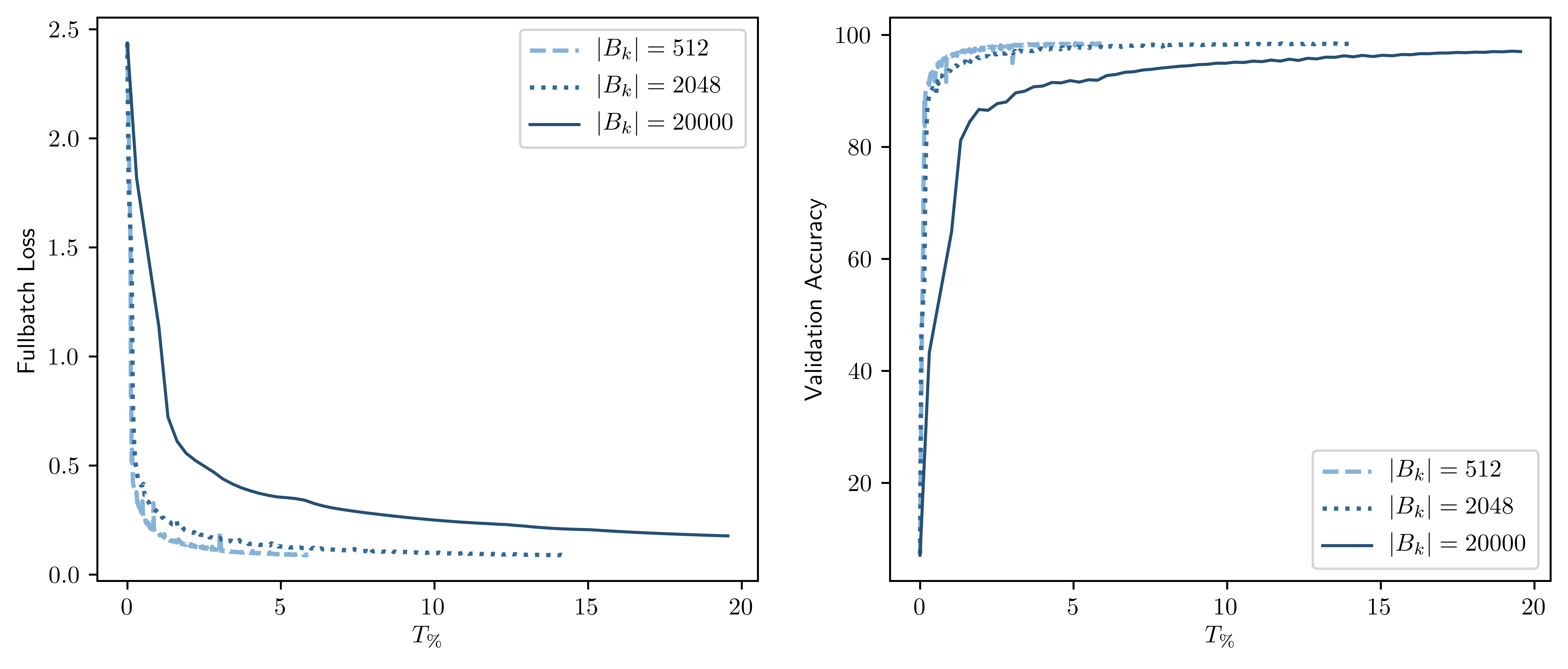
Figure 1: Loss and accuracy curves for the first 1000 iterations and with respect to the relative GPU-time of the bSQH method with μ=1.1 and the strategy \eqref{eqn: MA}.
The paper presents extensive numerical experiments demonstrating the bSQH algorithm's effectiveness in training sparse CNNs. When applied to image classification tasks, particularly with medical images, the algorithm showcases its ability to produce models with high sparsity while maintaining competitive accuracy levels. The computational efficiency of the bSQH technique is emphasized, showing significant improvement in training times compared to traditional full-batch methods.
Figure 2: Samples from the OrganAMNIST dataset with corresponding labels.
Application and Implications
The application of the bSQH method to CNNs, including non-residual architectures like LeNet-5, showcases the potential for scalability and flexibility in real-world applications. By addressing over-parameterization through sparse learning, bSQH reduces the memory footprint and enhances the computational efficiency of trained models, crucial for deployment in resource-constrained environments.
Conclusion
The bSQH algorithm represents a promising advance in the training of convolutional neural networks by framing the learning process as an optimal control problem. The incorporation of the Pontryagin maximum principle facilitates the development of robust algorithms capable of handling sparsity and computational challenges in deep learning. Future work may explore further extensions to more complex network architectures and larger-scale datasets, continuing to bridge optimal control theory with machine learning advancements.