- The paper introduces a memory-based framework that aligns visually similar instance pairs to enhance cross-domain object detection, showing improvements such as a 4.2% mAP increase under foggy conditions.
- It employs dual-memory mechanisms for foreground and background alignment, effectively decoupling instances from mini-batch limitations and refining domain adaptation.
- Empirical evaluations on benchmarks like Foggy Cityscapes and Sim10k demonstrate significant gains over existing methods, establishing a new standard for robust object detection.
Visually Similar Pair Alignment for Robust Cross-Domain Object Detection
Introduction
Domain gaps between source and target distributions remain a crucial bottleneck in deploying object detectors in real-world settings, where data from the operational environment often differ significantly from labeled training datasets. Existing Unsupervised Domain Adaptation (UDA) methods typically attempt to align features across domains, yet instance-level misalignments—such as aligning visually dissimilar objects within the same category—can profoundly impair adaptation. The paper "Visually Similar Pair Alignment for Robust Cross-Domain Object Detection" (2504.06607) provides an integrated framework that directly tackles this challenge by focusing alignment on visually similar instance pairs, thereby prioritizing domain-invariant alignment over intra-class visual variation.
Examining the Hypothesis: Importance of Visual Similarity in Alignment
A fundamental claim of this work is experimentally validating that effective cross-domain adaptation relies on aligning source and target instances that are visually similar, rather than merely sharing the same semantic category. To disambiguate domain shift effects from intra-class visual variation, a new dataset, AugSim10k → FoggyAugSim10k, is introduced, where source objects are systematically modified in color and orientation, and target images are derived from the source with fixed-intensity fog (Figure 1).
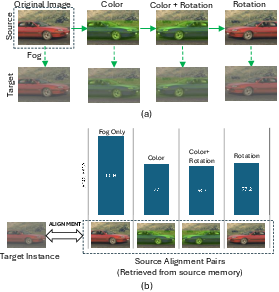
Figure 1: The cross-domain dataset AugSim10k → FoggyAugSim10k allows disentangled analysis of color, orientation, and domain shifts in object detection adaptation.
Empirical analysis reveals that aligning source-target pairs differing exclusively in domain characteristics (e.g., fog) yields substantially higher detection accuracy than aligning instances with color or orientation variations. A measured improvement of 4.2% is observed when only domain shift is present, substantiating the pivotal role of visual similarity in alignment.
Methodology
The proposed framework augments the prior MILA architecture with several crucial improvements centering on memory-based, visually-driven instance alignment.
Network Architecture Overview
The architecture incorporates a dual-memory mechanism: a foreground memory storing all labeled object features from the source domain, and a background memory capturing non-object context features. These memory banks decouple instance alignment from the limitations of mini-batch sampling, providing a persistent, large-scale feature repository (Figure 2).
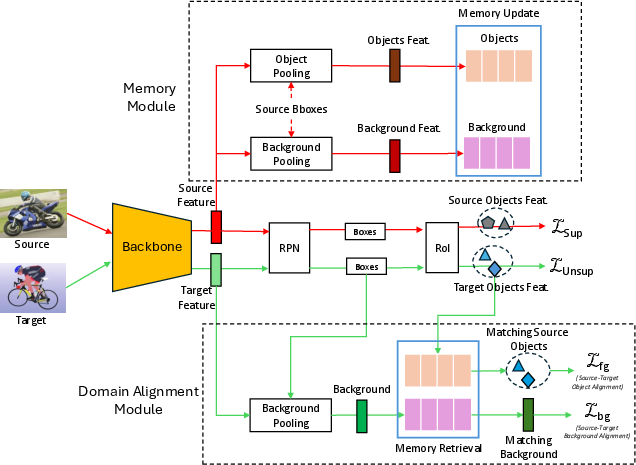
Figure 2: Architecture comprising memory modules and visual similarity-based foreground/background domain alignment units.
Detection heads extract features for both predicted and detected regions in the target domain, which are then matched with their most visually cognate counterparts from source domain memory. This process is conducted separately for foreground and background, fostering class-aware and domain-aware alignment.
Memory-Based Foreground and Background Alignment
Foreground memory aligns target instance features with their most visually similar source instances within the same class using a similarity-weighted triplet loss. For background, the alignment is adversarial—source and target backgrounds are aligned via a domain discriminator, but the retrieval process ensures alignment focuses solely on domain differences rather than irrelevant visual context.
A crucial design aspect is the use of subsampled coreset strategies to efficiently manage memory size without incurring significant accuracy penalties.
Experimental Results
The framework is evaluated on multiple challenging UDA detection benchmarks:
- Adverse Weather: Cityscapes → Foggy Cityscapes
- Synthetic-to-Real: Sim10k → Cityscapes
- Real-to-Artistic: Pascal VOC → Comic2k
Across these scenarios, the system consistently establishes new state-of-the-art results. Notably, the method achieves 53.1% mAP on Foggy Cityscapes and 62.3% mAP on Sim10k, outperforming previous best methods (including MILA and CMT) by up to 4.1 percentage points in mAP. This performance margin is especially accentuated in under-represented classes, such as ‘train,’ where the method delivers marked accuracy gains due to the expanded alignment capacity afforded by the memory module.
The impact of memory-based versus non-memory alignment strategies is highlighted in Figure 3.
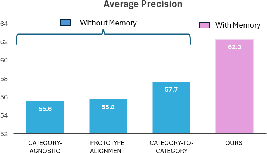
Figure 3: Memory-based visually similar alignment outperforms non-memory C2C schemes by 4.6% mAP.
Additionally, the benefit of aligning both foreground and background features is validated, as depicted in Figure 4.
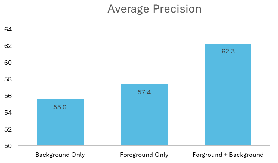
Figure 4: Combined foreground and background alignment yields optimal domain adaptation performance.
Analysis: Subsampling, Confidence, and Loss Sensitivity
Ablation studies demonstrate that greedy coreset-based subsampling can reduce the memory bank footprint by 50–70% with negligible accuracy loss, facilitating scalable deployment (Figure 5).
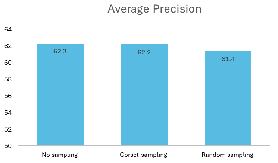
Figure 5: Greedy coreset subsampling of memory banks minimizes computation with minimal impact on mAP.
Performance is sensitive to alignment hyperparameters: optimal detection accuracy is observed for a target detection confidence threshold δ=0.8, and for alignment loss weights λ2=λ3=0.05. Importantly, aligning only the single most similar pair (K=1) maximizes adaptation performance, supporting the central hypothesis of visual similarity-focused alignment.
Visualizations and Qualitative Assessment
Qualitative results offer further evidence that the proposed method selects source instances differing minimally—if at all—from target proposals in visually salient properties like color and pose, even when considerable intra-class variation exists (Figure 6).

Figure 6: Instance pair visualization underscores the selection of visually matched source-target alignments, capturing subtle intra-class attributes.
Detection visualizations on synthetic-to-real tasks illustrate improved localization and reduced false positives compared to previous SOTA methods (Figure 7).
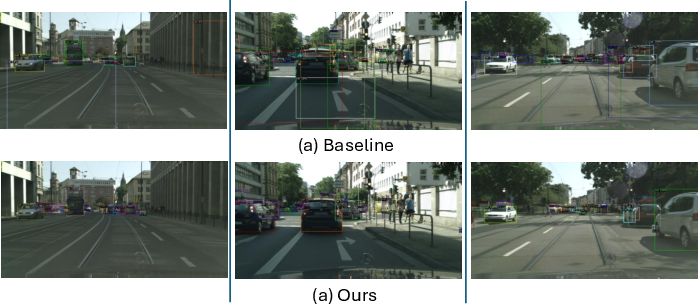
Figure 7: Object detection in synthetic-to-real transfer: the proposed system demonstrates improved localization and robustness versus MILA baseline.
Theoretical and Practical Implications
The results invalidate the practice of relying solely on semantic or prototype-based alignment in cross-domain object detection, spotlighting the necessity to incorporate visual similarity constraints. Practically, this suggests that memory-augmented models provide a scalable mechanism for robust alignment in scenarios with significant intra-class variation and sparse minor classes.
The methodological insights port readily to domains requiring fine-grained adaptation (e.g., autonomous driving in adverse conditions or rare-class object detection in medical imaging). The release of the controlled-variation dataset further enables rigorous analysis of adaptation dynamics in future work.
Conclusion
This work provides both theoretical justification and empirical evidence that instance-level domain adaptation should privilege visual similarity over mere category congruence. The proposed memory-based visually similar pair alignment framework, which extends MILA to background context and incorporates large-scale scalable memory, sets a new empirical standard across several UDA detection benchmarks. This paradigm marks a critical shift towards leveraging fine-grained visual characteristics in cross-domain adaptation and establishes a foundation for further developments in domain generalization, instance retrieval strategies, and robust detector deployment in heterogeneous environments.

