- The paper presents a comprehensive hierarchical dataset with 15,842 facial images and 49,919 VQA pairs to evaluate MLLMs in facial perception.
- The paper employs rigorous manual annotation from 200 trained annotators across diverse views and question types to ensure high-quality labels.
- The paper's evaluation shows that while models like GPT-4o perform robustly overall, significant gaps remain in recognizing nuanced facial attributes.
FaceBench: A Comprehensive Benchmark for Multi-View Multi-Level Facial Attribute Analysis
FaceBench provides a groundbreaking framework for evaluating Multimodal LLMs (MLLMs) in facial perception. It extends the current capabilities of these models by presenting a multi-view, multi-level benchmarking dataset with a hierarchical facial attribute structure, enhancing the scope of analysis possible in face perception tasks.
Hierarchical Facial Attribute Structure
FaceBench introduces a hierarchical structure that categorizes facial attributes across five distinct views: Appearance, Accessories, Surrounding, Psychology, and Identity. This categorization facilitates an in-depth analysis of facial perception by enabling the evaluation of both fundamental and nuanced facial features. Each view comprises multiple levels: coarse-grained Level 1 attributes such as "eyes" and "hair," intermediate Level 2 components like "pupil" or "earlobe," and fine-grained Level 3 distinctions based on size, color, shape, or type.
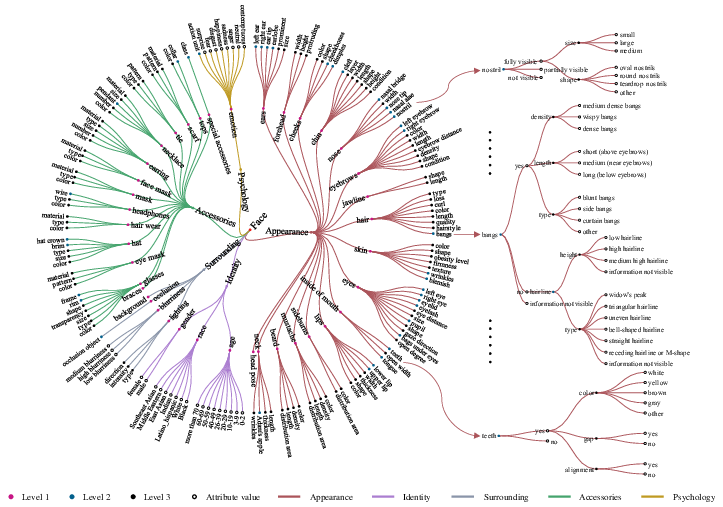
Figure 1: Hierarchical organization of facial attributes.
This detailed taxonomy allows for a robust analysis that parallels human perception, capturing the complexity and granularity necessary for comprehensive facial recognition tasks. By integrating over 210 attributes and 700 attribute values, the structure forms the backbone of the FaceBench dataset.
Dataset Collection and Annotation
FaceBench comprises 15,842 facial images, meticulously gathered from diverse datasets and incorporating a broad range of VQA (Visual Question Answering) pairs. This dataset includes images representing the view perspectives of Identity, Psychology, Appearance, Accessories, and Surrounding. It divides into a test set containing 49,919 VQA pairs and a dedicated training set with 23,841 pairs.
The dataset utilizes a variety of question types—True/False, Single-Choice, Multiple-Choice, and Open-Ended—developed from predefined templates to ensure comprehensive coverage of the hierarchical structure.
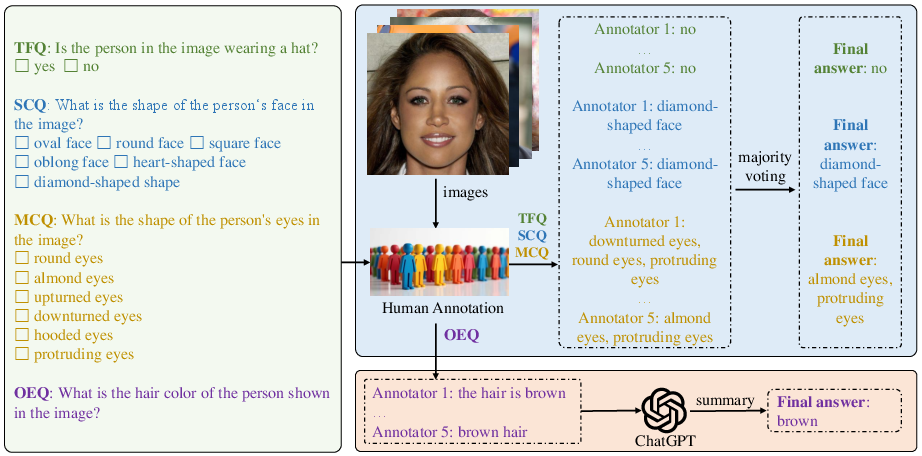
Figure 2: Question types and human annotation workflow for building our dataset.
The process involves rigorous manual annotation, ensuring high-quality labels through the use of 200 trained annotators. This extensive effort is aimed at reducing labeling errors and guaranteeing that annotations closely match human perception, bolstered by a multi-layered quality control process.
Evaluation of Multimodal Models
FaceBench extensively evaluates a range of cutting-edge MLLMs, measuring their ability to process and interpret facial attributes across the specified views and levels. Baseline tests on prominent models like GPT-4o and Face-LLaVA—a fine-tuned version of LLaVA—demonstrate considerable variability in their efficacy at recognizing different facial characteristics.

Figure 3: Samples from our FaceBench dataset.
Results and Insights
The results showcase that while certain commercial models such as GPT-4o deliver robust overall performance, significant gaps remain, particularly in recognizing nuanced and complex facial attributes. The Face-LLaVA model, although trained on a limited dataset, shows promising improvements over existing open-source frameworks by attaining competitive results against commercial models.
Tables of results underscore a diverse range of performance across multiple attribute views, revealing critical insights into the strengths and weakness of current MLLMs. These findings highlight the ongoing challenges in the field of facial perception, emphasizing the need for more advanced datasets and model architectures to achieve human-level understanding.
Conclusion
FaceBench represents a substantial advance in the evaluation of MLLMs for facial perception tasks. By incorporating a hierarchical, multi-view, multi-level approach to facial attributes, it provides a comprehensive platform for testing and enhancing model performance in this domain. Future enhancements based on the insights from FaceBench could steer the development of more sophisticated and human-like perceptual models, thereby pushing the boundaries of what is achievable in AI-driven facial recognition and analysis.

