- The paper introduces a multimodal benchmark (ADS-Edit) that enables efficient knowledge editing in ADS models to tackle traffic knowledge misunderstandings.
- It employs a tri-axis framework covering perception, understanding, and decision-making with diverse modalities such as video and multi-view images.
- Experimental results reveal that methods like GRACE and WISE show trade-offs in reliability, generality, and locality, highlighting areas for improvement.
ADS-Edit: A Multimodal Knowledge Editing Dataset for Autonomous Driving Systems
Introduction
Large Multimodal Models (LMMs) have demonstrated potential in various domains, including Autonomous Driving Systems (ADS). However, directly applying LMMs to ADS poses significant challenges due to traffic knowledge misunderstandings, complex road conditions, and diverse vehicular motion states. The paper proposes a knowledge editing approach to address these challenges by enabling model updates without extensive retraining. The authors introduce ADS-Edit, a multimodal knowledge editing dataset specifically designed for ADS, which includes various real-world scenarios, data types, and evaluation metrics.
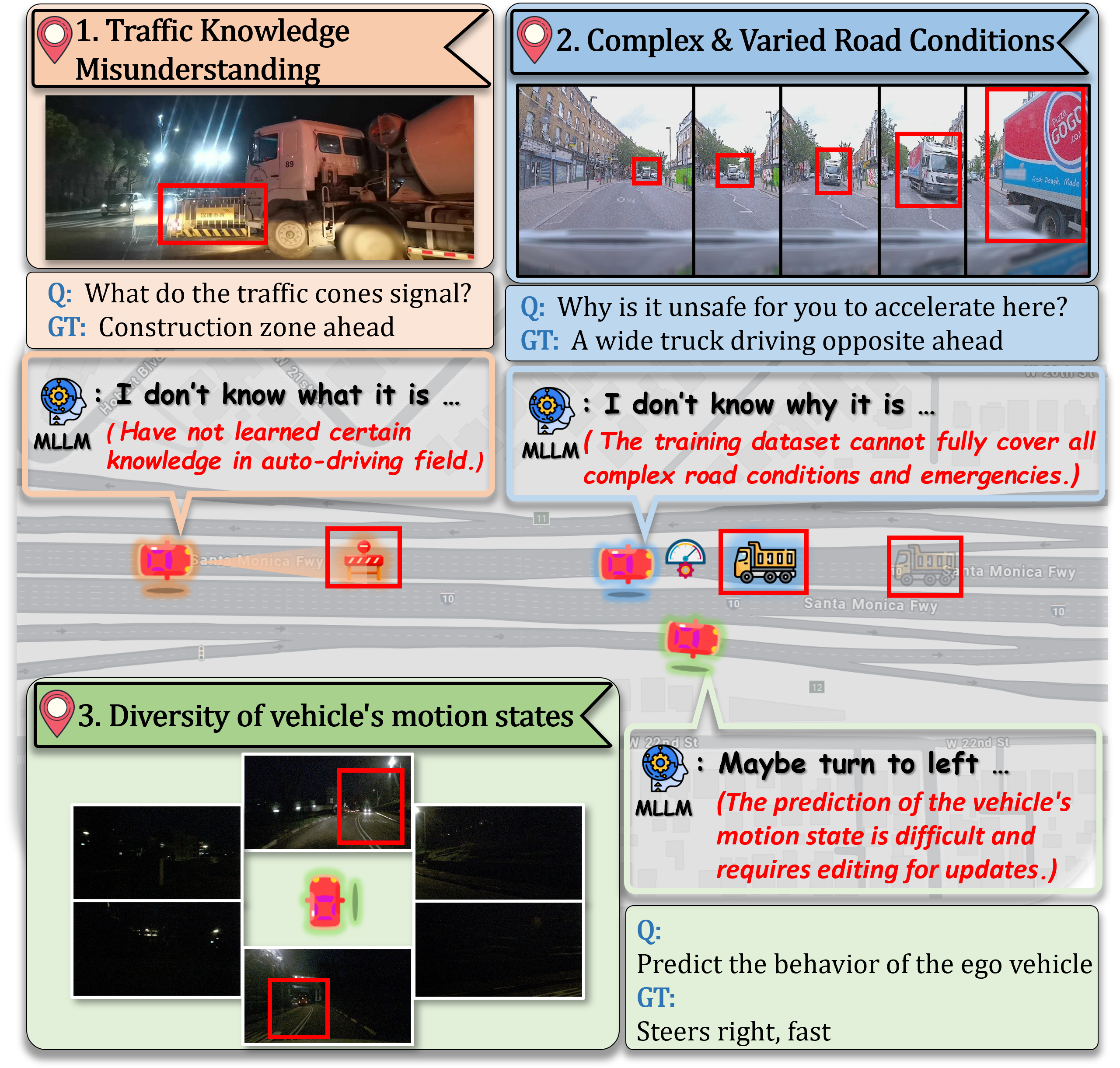
Figure 1: Direct application of LMMs in Autonomous Driving Systems faces several challenges, including the misunderstanding of traffic knowledge, the complex and varied road conditions, and the diversity of vehicle's motion states. Knowledge Editing that enables efficient, continuous, and precise updates to knowledge can effectively address these challenges.
Benchmark Construction
ADS-Edit is constructed around three key scenario types and data types. The benchmark is organized along three axes: perception, understanding, and decision-making, which assess LMM capabilities from basic recognition to complex reasoning. The input modalities include video, multi-view images, and single images. Metrics such as reliability, generality, and locality are designed to evaluate knowledge editing methods within this framework.
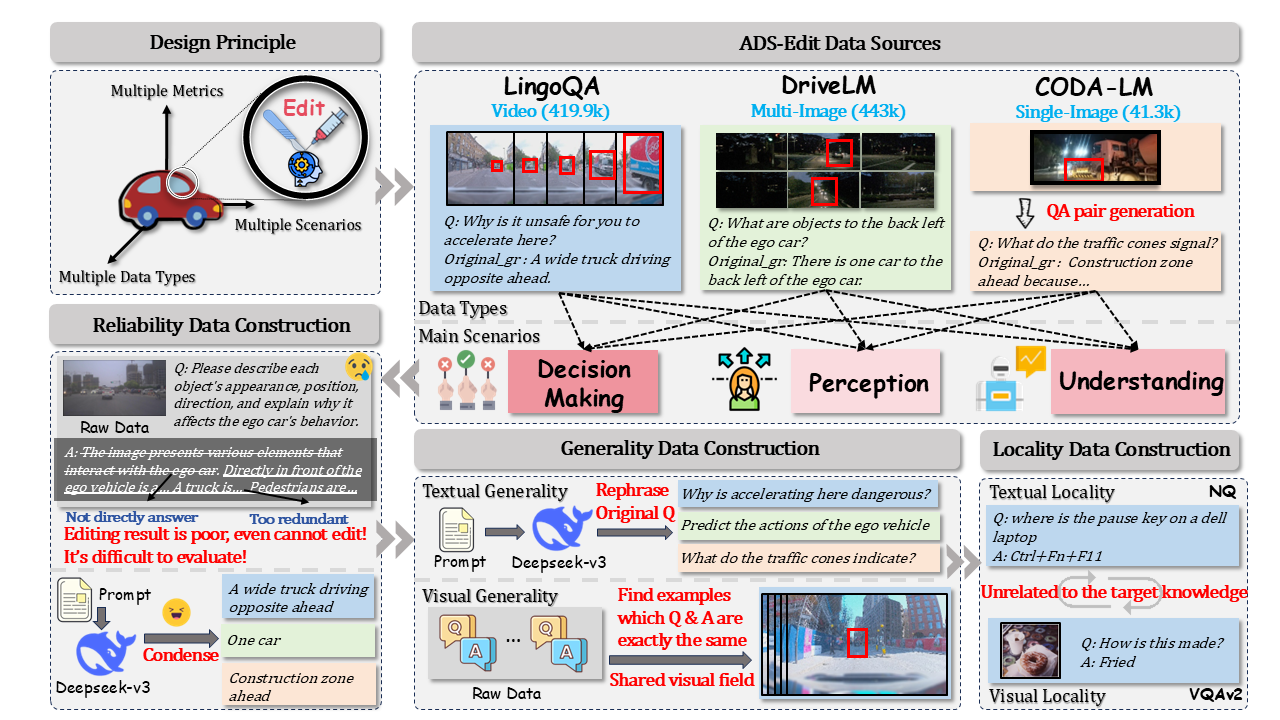
Figure 2: The overview of ADS-Edit construction pipeline.
Scenario Type and Data Collection
The authors designed a tri-axis framework to comprehensively evaluate LMMs. The scenario types include perception, which examines basic visual capabilities; understanding, which involves recognition of traffic rules; and decision making, which requires the model to synthesize information for driving decisions. The data types are categorized as video, multi-view images, and single images. Data were sourced from established autonomous driving datasets, LingoQA and DriveLM. Scenario classifications ensure that data selected cover a spectrum of real-world challenges faced by ADS.
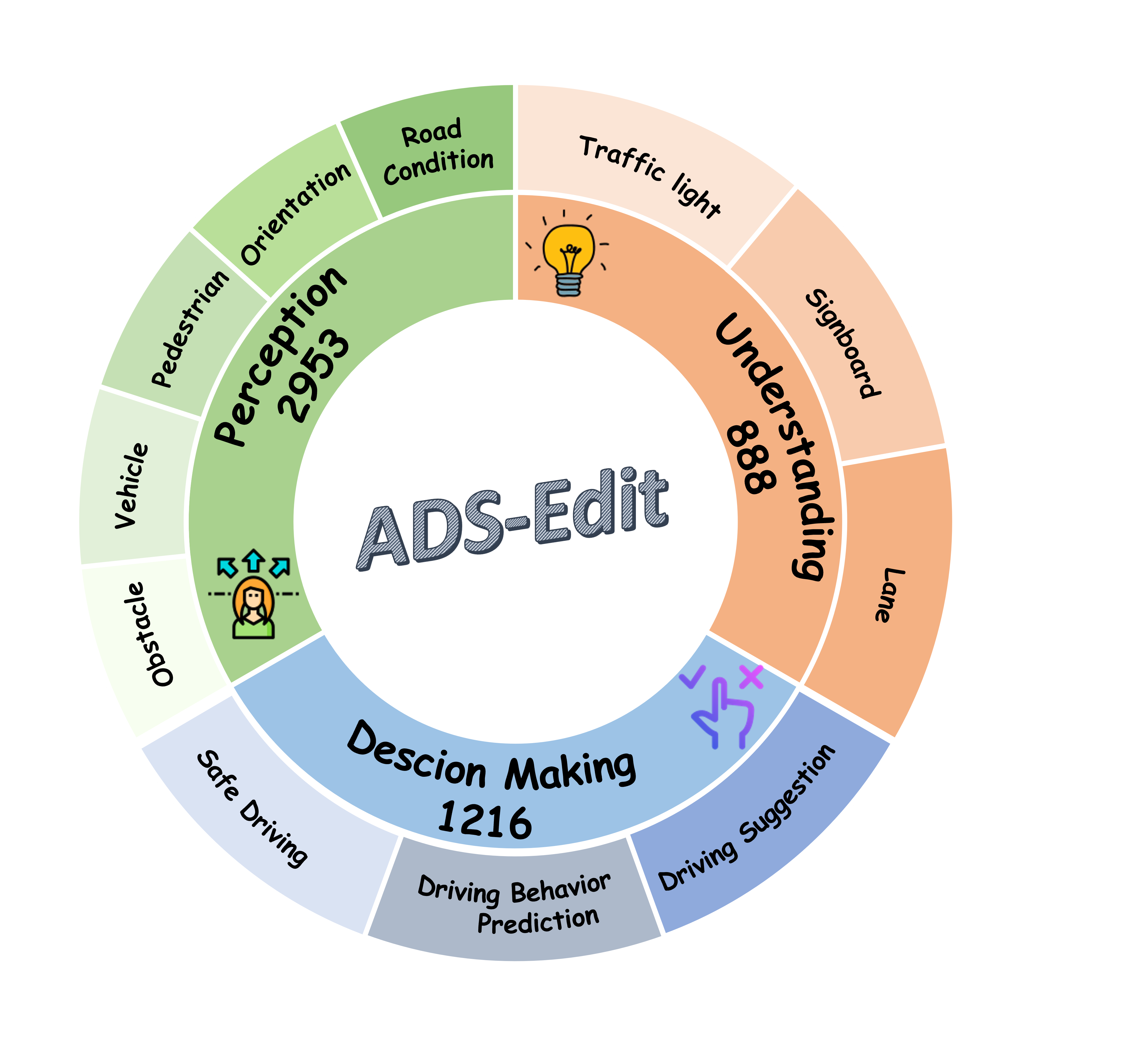
Figure 3: The statistics of scenario types for ADS-Edit.
Evaluation Metrics
The metrics include reliability, which assesses the success of modifying a model's behavior; generality, which evaluates performance across new but related scenarios; and locality, which checks whether unintended knowledge alterations occur after editing. Experiments were conducted on modern LMMs such as LLaVA-OneVision and Qwen2-VL. Performance was measured using editing evaluation (token-level comparison) and real-world evaluation (free-form generation).
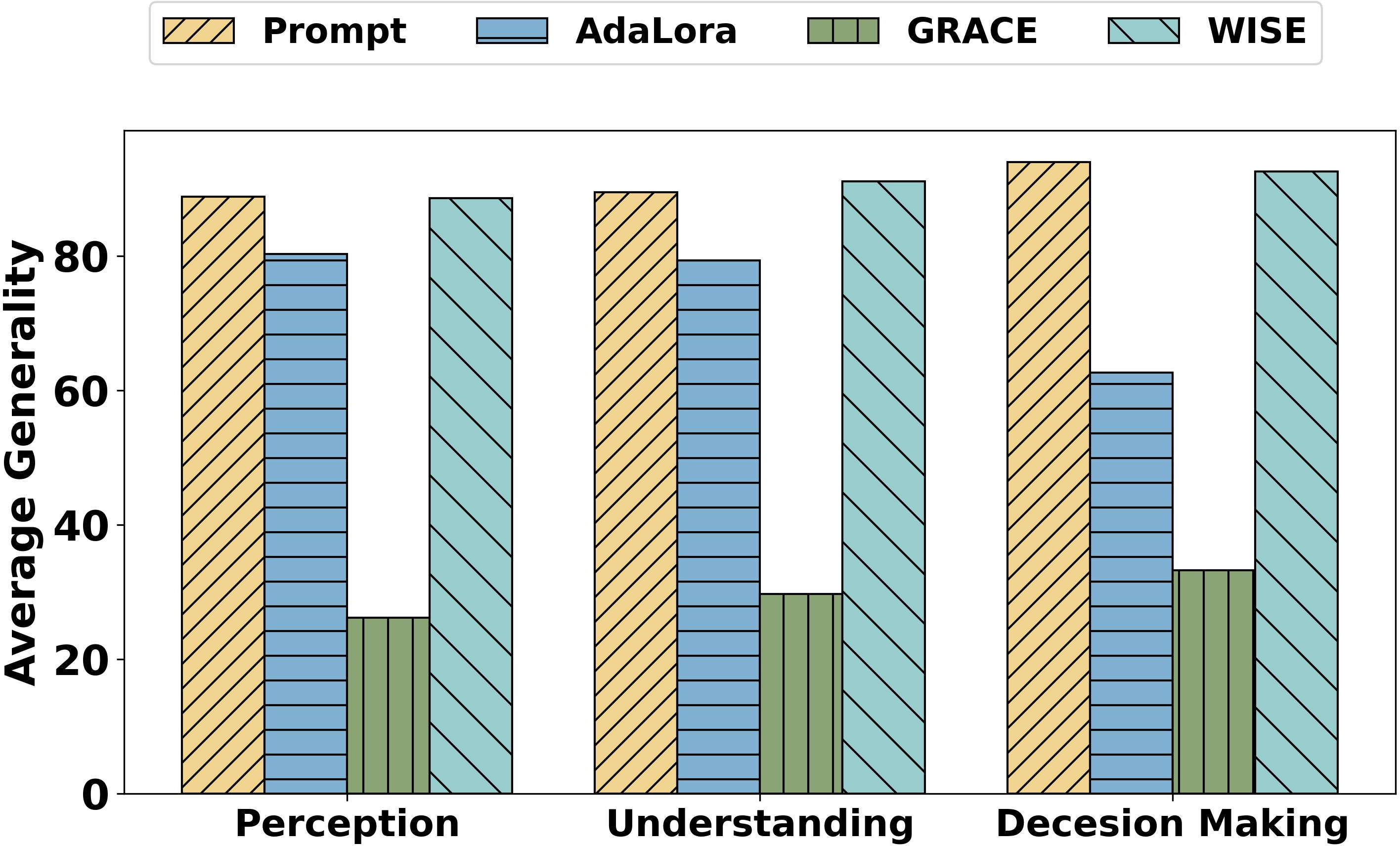
Figure 4: The average generality metric of single editing across different scenarios.
Experimental Results
In experiments, the memory-based editing methods GRACE and WISE showed high effectiveness, with GRACE achieving a perfect modification rate but demonstrating poor generalization. WISE offered a balanced performance. Prompt and AdaLora methods exhibited suboptimal reliability and generality, with AdaLora severely affecting locality due to parameter modifications. The analysis highlighted that, although editing methods performed differently, there was a need for improvements to fully meet ADS requirements.
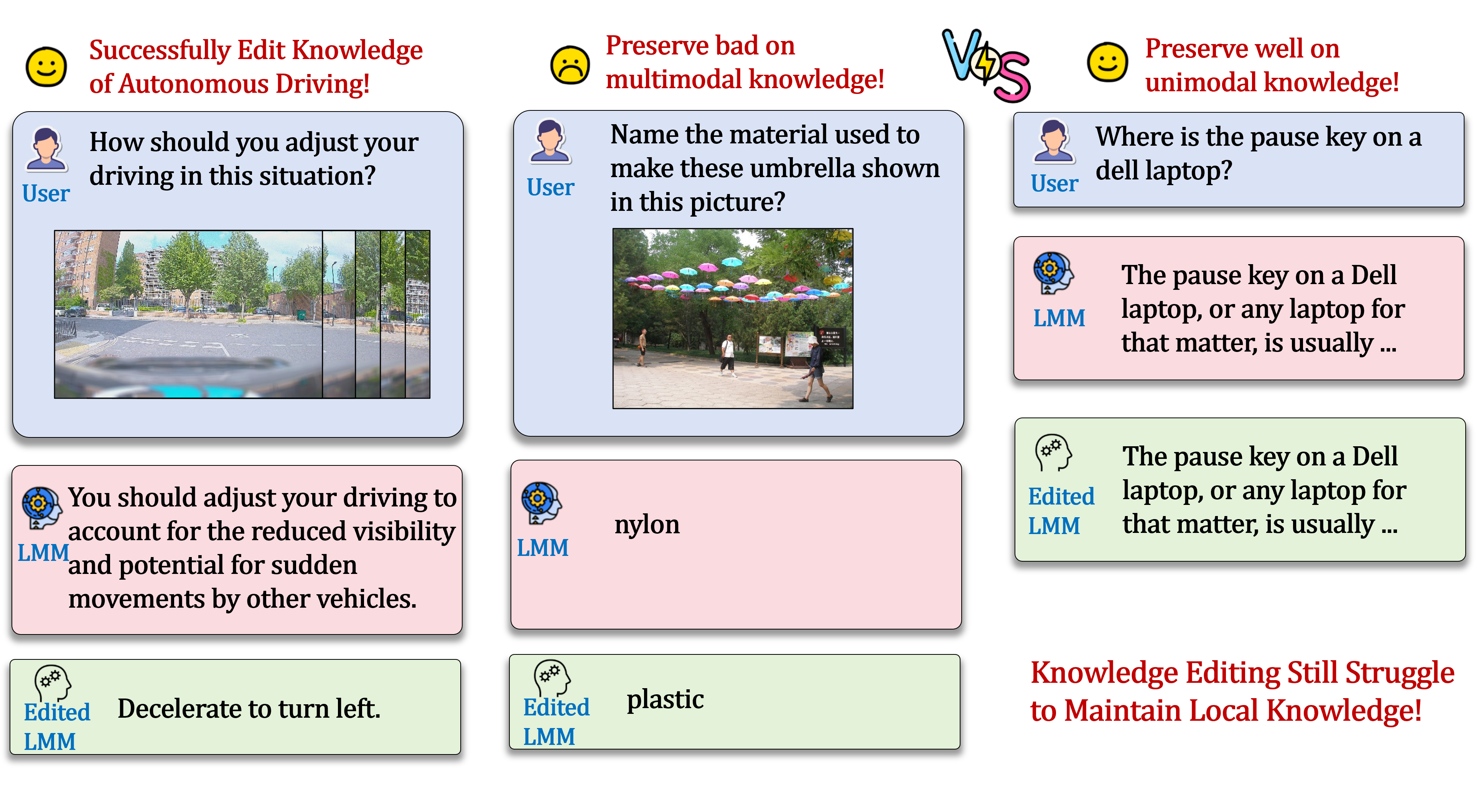
Figure 5: Cases analysis of editing LLaVA-OneVision with WISE.
Analysis
Experiments revealed that decision-making scenario data posed the greatest challenge due to complexity, while simpler perception and understanding scenarios were less demanding. The adaptation of models across different scenarios was analyzed, and the findings indicated that LLMs retained original outputs, displaying resistance to edits, leading to consistency concerns. Reducing video frame inputs demonstrated potential for balancing performance and processing speed, crucial for real-time autonomous applications.
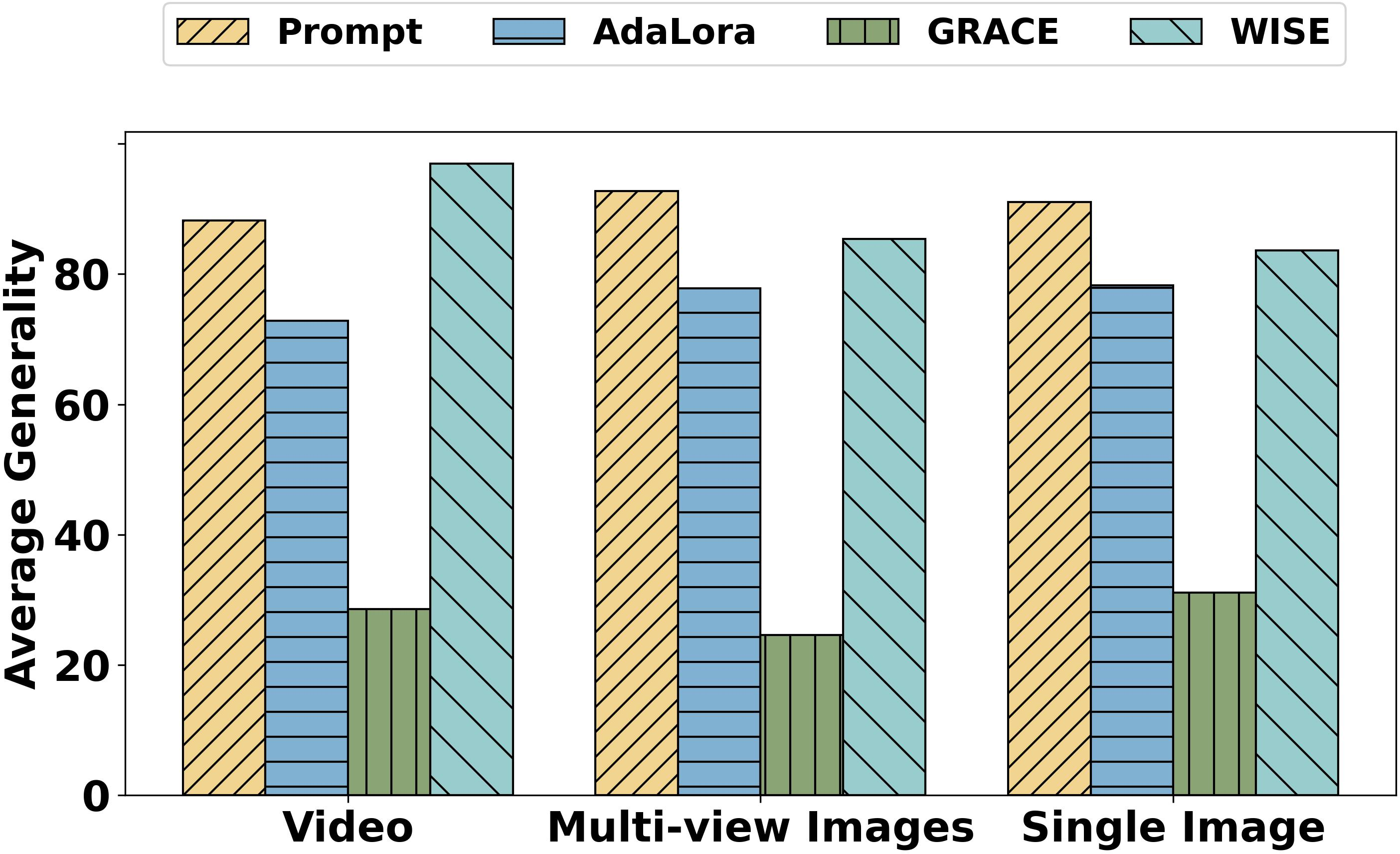
Figure 6: The average generality metric of single editing across different data types.
Conclusion
The work provides a structured methodology for applying knowledge editing techniques in ADS, culminating in the construction of the ADS-Edit benchmark. This work serves as a foundational effort to bridge LMMs with practical challenges in autonomous driving, advocating for continued exploration and improvement of knowledge editing methods specifically tailored for domain-specific applications such as ADS. The study concludes that current techniques require refinement to fully meet the operational demands of autonomous systems. Future work could focus on enhancing the robustness and adaptability of editing methods to better integrate the varied data modalities and scenarios encountered in real-world autonomous driving systems.