- The paper illustrates how selecting specific database architectures for conversational, situational, and semantic contexts optimizes GenAI performance.
- It demonstrates that a multi-database approach enhances data ingestion, retrieval, and real-time query processing in GenAI systems.
- It highlights practical examples using Redis, MySQL, and vector databases like Milvus to address scalability and accuracy challenges.
Role of Databases in GenAI Applications
Generative AI (GenAI) applications have revolutionized modern computational tasks by enabling intelligent content generation, automation, and decision-making across diverse domains. Underpinning the effectiveness of these applications is the choice of database architectures that support efficient data storage, retrieval, and contextual augmentation. This essay dissects the critical roles of databases in GenAI workflows, underscoring the significance of matching database types with specific context requirements—namely conversational, situational, and semantic—to optimize performance, accuracy, and scalability in GenAI solutions.
Introduction to Generative AI Systems
Generative AI has made significant strides in content creation using advanced models like Transformers, GPT-4, and Gemini, capable of generating human-like outputs across text, images, code, and audio. Unlike traditional models focused on predictive tasks, GenAI leverages architectures such as Transformer-based LLMs to understand context, automate workflows, and foster innovation in industries ranging from healthcare to finance, customer support, and beyond. These models deploy large-scale data sets in training and improve contextual adaptability via methodologies like RLHF and RAG, propelling multimodal AI advancements.
Importance of Database Selection in GenAI
A common fallacy in GenAI implementations is the over-reliance on vector databases for semantic search, overlooking the distinct storage needs of different data types. The choice of the wrong database architecture can result in bottlenecks and data inconsistencies, adversely impacting model efficiency and scalability. Therefore, integrating a multi-database approach allows GenAI applications to provide context-sensitive, personalized, and high-performance AI solutions.
In practical terms, real-time query processing in GenAI demands databases that can manage rapid data ingestion and retrieval. Traditional databases often falter with the necessary throughput, making low latency and scalability crucial. This necessitates strategic database selection to maintain accuracy and enhance the effectiveness of GenAI solutions.
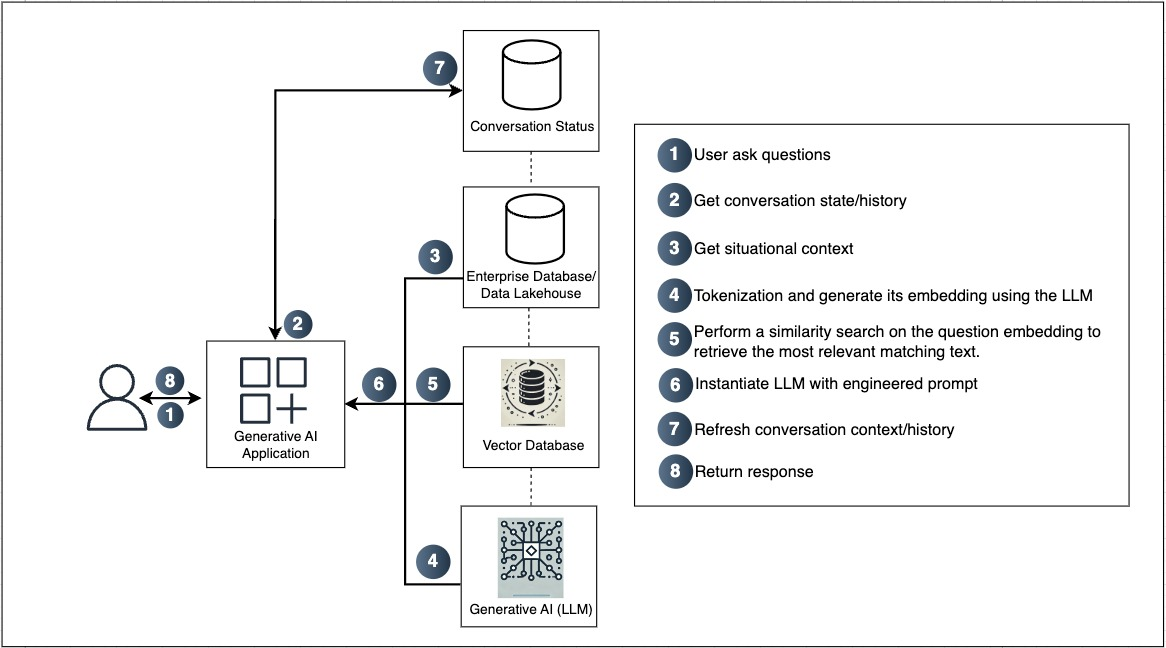
Figure 1: Here is a high-level workflow of a GenAI Application.
Database Roles in GenAI Applications
Conversational Context
Conversational context involves preserving chat histories, user interactions, and system responses to ensure coherence across sessions. Key-value stores like Redis or document databases like MongoDB can offer dynamic storage choices that facilitate rapid read/write operations required for real-time updates.
Situational Context
Situational context encompasses structured data such as user profiles and operational metrics, vital for personalizing AI interactions. Relational databases like MySQL or PostgreSQL, or data Lakehouses like Apache Hudi, provide the necessary schema and consistency for handling this structured information.
Semantic Context
Semantic context refers to managing embeddings and vector data for performing similarity searches, identifying semantic connections beyond keyword matching. Vector databases like Milvus or FAISS excel in storing and retrieving vector embeddings, supporting efficient high-dimensional queries necessary for GenAI.
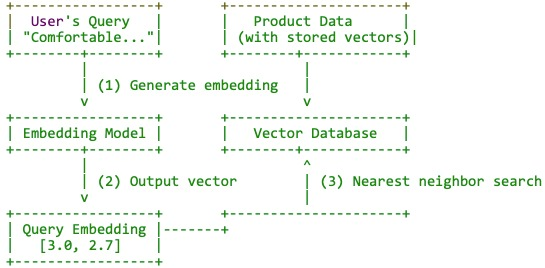
Figure 2: Vector search workflow.
Vector Search Mechanics
Vector databases perform similarity searches by indexing high-dimensional embeddings generated by LLMs. For tasks such as recommendation systems or question answering, the embeddings enable semantic retrieval based on conceptual proximity rather than keyword matches, significantly enhancing user satisfaction and conversion rates on platforms like e-commerce.

Figure 3: Distance Visualization.
Distance calculations using metrics like Euclidean distance facilitate semantic searches, offering a nuanced understanding of user queries. Vector databases allow for efficient indexing and retrieval, addressing scalability and performance challenges in GenAI applications.
Conclusion
The strategic integration of conversational, situational, and semantic database contexts vastly enhances the responsiveness and contextuality of GenAI applications. By leveraging relational, document, and vector databases respective to each context, these systems achieve superior performance in real-time interaction management and data processing. Adopting this tailored approach not only accommodates diverse data requirements but also fosters a richer, more intuitive AI-driven user experience, elevating GenAI's role in advancing technological innovation across multiple sectors.