Mapping AI Benchmark Data to Quantitative Risk Estimates Through Expert Elicitation
Abstract: The literature and multiple experts point to many potential risks from LLMs, but there are still very few direct measurements of the actual harms posed. AI risk assessment has so far focused on measuring the models' capabilities, but the capabilities of models are only indicators of risk, not measures of risk. Better modeling and quantification of AI risk scenarios can help bridge this disconnect and link the capabilities of LLMs to tangible real-world harm. This paper makes an early contribution to this field by demonstrating how existing AI benchmarks can be used to facilitate the creation of risk estimates. We describe the results of a pilot study in which experts use information from Cybench, an AI benchmark, to generate probability estimates. We show that the methodology seems promising for this purpose, while noting improvements that can be made to further strengthen its application in quantitative AI risk assessment.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about turning AI test scores into real-world risk numbers. Today, we have many tests that show what LLMs—like advanced chatbots—can do. But a good test score doesn’t directly tell us how likely the model is to help cause harm in the real world (for example, in cyberattacks). The authors show a simple way to connect AI “benchmarks” (standard tests) to estimates of real-world risk by asking cybersecurity experts to translate test performance into probabilities.
What questions did the paper ask?
The paper explores three easy-to-understand questions:
- If an AI can pass certain hard cybersecurity puzzles, how much more likely does it make a cybercriminal succeed at creating and deploying malware?
- Can we build a simple “map” that links AI test performance to a risk number (a probability)?
- Will experts agree on those numbers, and what does disagreement tell us about how to improve future tests and risk models?
How did the researchers study it?
Think of this like connecting a student’s practice drills to their game-day performance. The team:
- Chose a cybersecurity benchmark called Cybench. It contains “Capture the Flag” (CTF) puzzles—small, focused hacking challenges. Each puzzle has a difficulty score called First Solve Time (FST), which is how long the fastest human team took to solve it. Higher FST = harder puzzle.
- Picked five relevant puzzles ranging from easier (about 7 minutes) to harder (about 5.5 hours).
- Brought together cybersecurity experts for a structured workshop. This process is called “expert elicitation”—a careful way to ask experts for estimates. They used a well-known method called the IDEA protocol (Investigate, Discuss, Estimate, Aggregate), which helps experts think clearly, compare views, and then combine their answers.
Here’s the key step they asked the experts to do:
- For each puzzle, imagine an LLM that can reliably solve puzzles up to that difficulty. Given that, what’s the probability that a cybercrime group succeeds in creating and deploying malware?
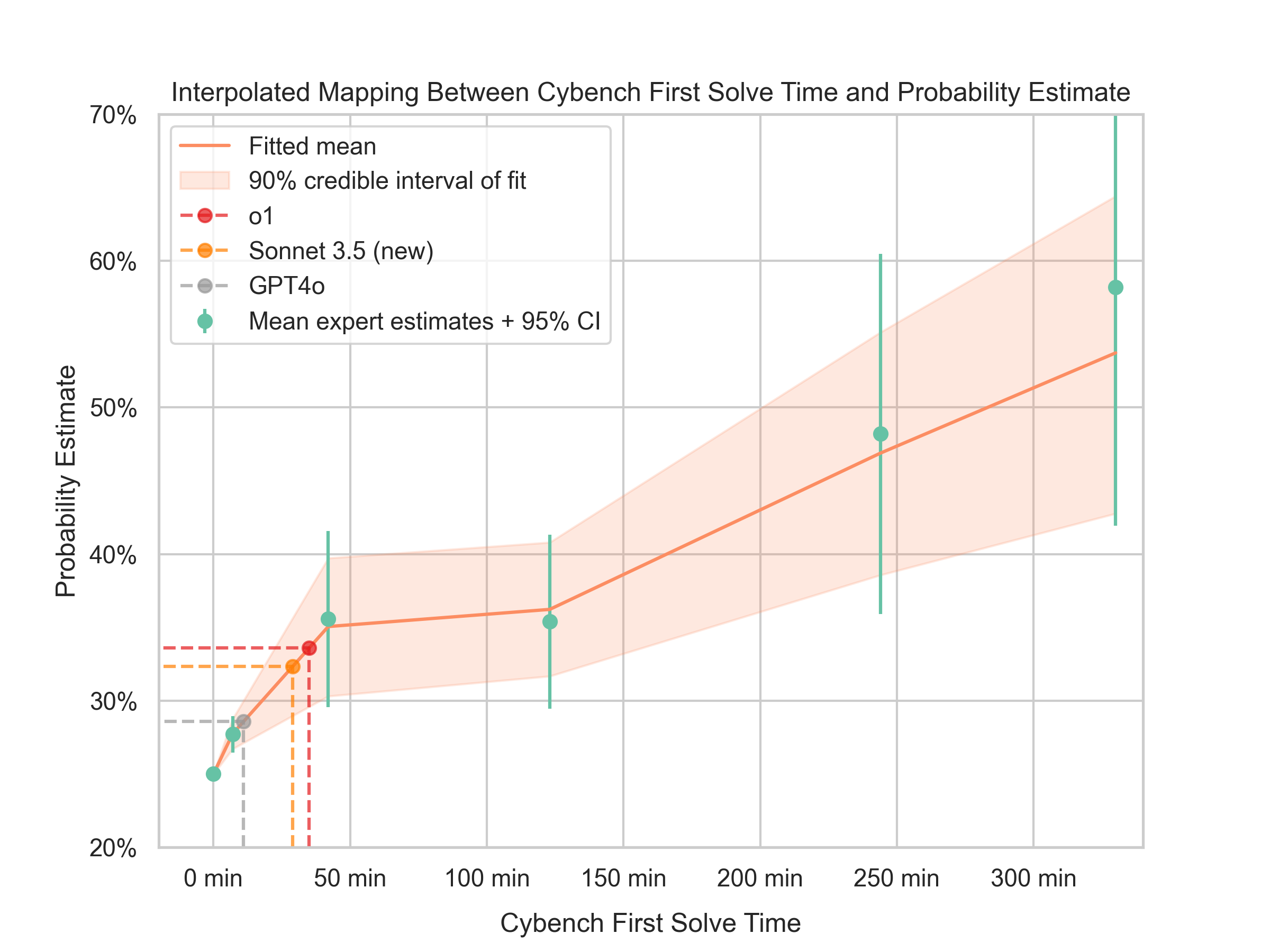
The experts started with a baseline: without any AI help, the chance of success was set at 25% (based on another study). For each puzzle, experts gave a new probability if the criminals had an LLM with that level of skill.
After collecting the estimates, the researchers used a simple statistical approach to draw a smooth curve that connects “puzzle difficulty the AI can handle” to “probability of malware success.” You can think of it like fitting a gentle line through a few points to show the overall trend, not exact predictions.
Quick definitions to help:
- Benchmark: a standardized test for AI.
- CTF task: a bite-sized hacking puzzle that tests specific skills.
- FST (First Solve Time): a difficulty score; longer = harder.
- Expert elicitation: a structured way to gather estimates from experts.
- Uplift: how much AI raises the chance of success compared to no AI.
What did they find?
The main findings, explained simply:
- Today’s LLMs likely give a small boost. Experts estimated that current models raise the chance of successful malware creation from 25% to around 30–35% (about a 5–10% increase).
- If future LLMs get much better—able to solve most of the hardest Cybench tasks—the uplift could be meaningful. Experts thought the success chance could rise to roughly 40–65%.
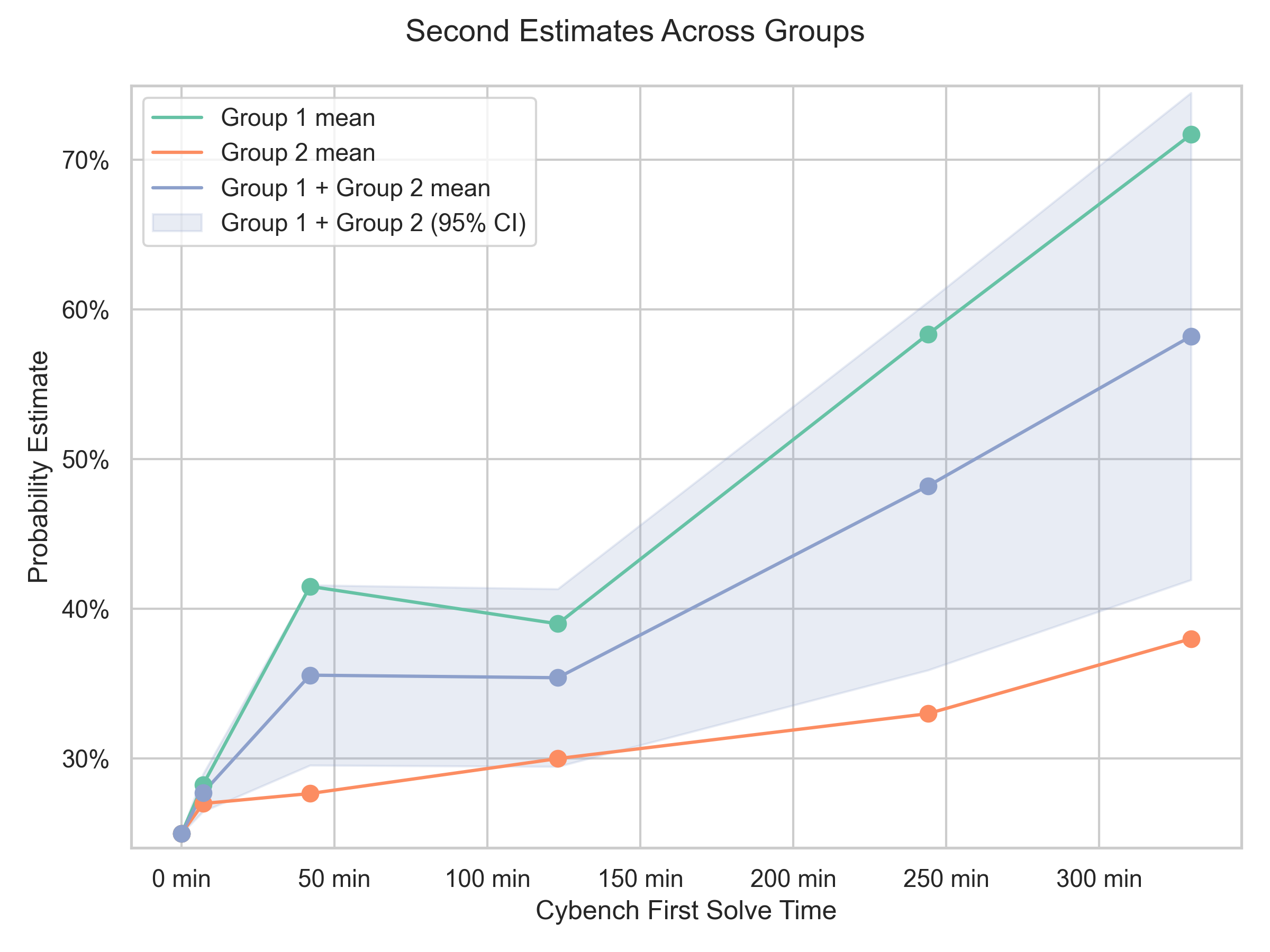
- Experts disagreed a lot. One group believed that strong AI puzzle performance would help less-skilled criminals succeed more often. Another group argued that real-world malware work is “messy” and requires stitching many steps together, so solving isolated puzzles might not translate into big real-world gains. This disagreement created wide uncertainty bands in the results.
Why this matters:
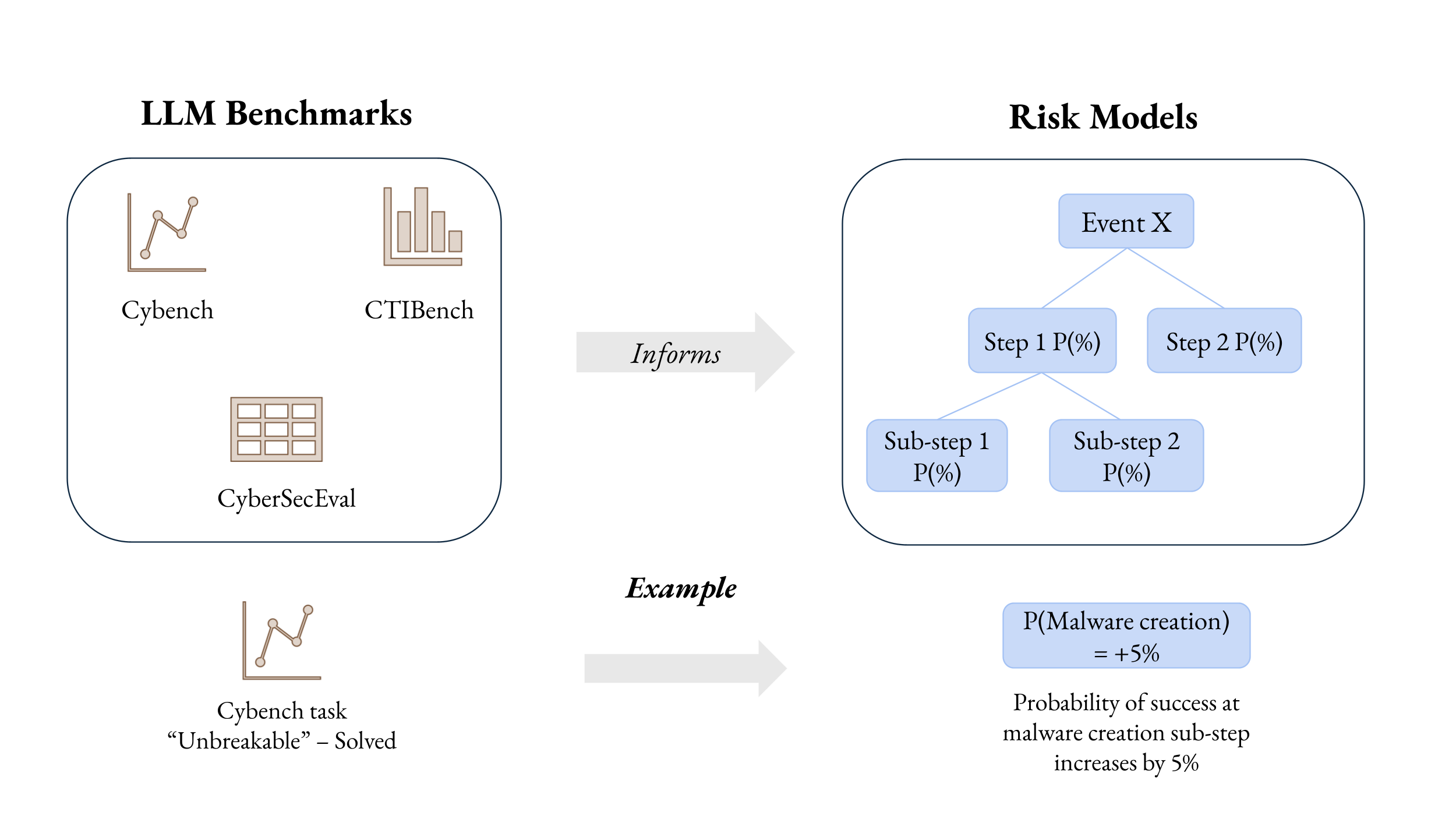
- The study shows a practical way to connect test scores to risk probabilities—turning “AI is good at X” into “there’s a Y% chance of harm.”
- It also shows where we lack clarity: benchmarks often test narrow skills, while real attacks require many coordinated abilities. That gap can cause experts to disagree.
What are the limits of this study?
- Small group, short time: Only seven experts completed all tasks, and discussion time was brief.
- Possible order bias: Tasks were shown from easiest to hardest, which might have nudged estimates upward over time.
- Benchmark-to-reality gap: CTF puzzles are clean and self-contained; real attacks are more complex. That makes translation from test performance to real-world outcomes tricky.
What could this change or improve?
This work suggests two big next steps:
- Make risk scenarios more specific. Experts asked about details like defender strength, attacker skill, and time limits. Clearer scenarios should lead to sharper estimates.
- Align tests with real-world risk models. If we design benchmarks that mirror the exact steps in a risk model (for example, “move through a large codebase without being detected”), then experts won’t have to guess how much a test matters—they’ll know.
The long-term impact:
- Policymakers and regulators can get numbers they can use (probabilities) rather than just “capability scores.”
- Researchers and safety teams can build better tests that measure the skills that actually matter for harm.
- Developers can see where their models might increase real-world risk and design safeguards accordingly.
Bottom line
This paper is an early but important step toward turning AI test results into understandable risk numbers. It finds that current LLMs likely provide a small boost to cyber attackers, while future, stronger models could provide a larger one. Just as important, it shows how to build a bridge from lab tests to real-world risk—and where that bridge still needs reinforcing.
Glossary
- Bayesian interpolation approach: A method that uses Bayesian statistics to smoothly infer a relationship from sparse or noisy data. "To create a continuous mapping between the likelihood of success at developing and deploying malware and the FST, we implement a Bayesian interpolation approach."
- Buffer overflow: A software vulnerability where writing more data to a buffer than it can hold overwrites adjacent memory, often enabling exploitation. "Examination of 'main.rs' file to identify a buffer overflow vulnerability."
- Capture the Flag (CTF): Competitive cybersecurity challenges where participants solve security problems or exploit vulnerabilities to capture “flags.” "First Solve Time (FST) of each Capture the Flag (CTF) task."
- Chemical, Biological, Radiological, and Nuclear (CBRN): A category of high-risk threats involving hazardous agents and weapons across these domains. "AI-enabled CBRN weapon design scenarios"
- Collection: In the MITRE ATT&CK taxonomy, the tactic of gathering data from a target prior to exfiltration or use. "what that taxonomy calls the tactics 'lateral movement', 'collection', 'command and control', and 'exfiltration'"
- Command and control: In cyber operations, establishing channels to communicate with compromised systems to issue commands or exfiltrate data. "what that taxonomy calls the tactics 'lateral movement', 'collection', 'command and control', and 'exfiltration'"
- Confidence interval: A statistical range that expresses the uncertainty around an estimated parameter. "The resulting trend presents a large confidence interval, especially at higher FSTs."
- Cyber Kill Chain: A framework describing stages of a cyberattack from reconnaissance to actions on objectives. "Lockheed Martinâs Cyber Kill Chain"
- CYBERSECEVAL 3: A benchmark suite evaluating cybersecurity risks and capabilities of LLMs. "it has several established benchmarks (e.g., CYBERSECEVAL 3 and CTIBench)"
- Delphi procedure: A structured method for eliciting expert judgments via iterative rounds to refine opinions. "It is a modified Delphi procedure"
- Deserialization (pickle): The process of reconstructing objects from a serialized format; unsafe deserialization can enable code execution. "Analysis of 'chall.py' and 'my_pickle.py' to identify a pickle deserialization vulnerability."
- Endpoint Detection and Response (EDR): Security tools focused on monitoring and responding to threats on endpoints like laptops and servers. "But it would not help overcome other hurdles, like evasion from EDR/NDR."
- Expert elicitation: Systematic collection of judgments from domain experts to quantify uncertain parameters. "we use expert elicitation: we show cybersecurity experts the hardest task that a hypothetical LLM can solve from Cybench"
- Exfiltration: The unauthorized transfer of data from a target system to an external location. "what that taxonomy calls the tactics 'lateral movement', 'collection', 'command and control', and 'exfiltration'"
- First Solve Time (FST): A metric capturing the time it took the fastest team to solve a CTF task, used as a difficulty proxy. "Cybench provides an appropriate benchmark for our study due to its quantitative difficulty metric - the First Solve Time (FST) of each Capture the Flag (CTF) task."
- IDEA protocol: A structured expert judgment process with phases: Investigate, Discuss, Estimate, Aggregate. "The IDEA protocol consists of a four-step elicitation process (âInvestigateâ, âDiscussâ, âEstimateâ, and âAggregateâ)"
- Jailbreaking: Techniques to bypass model safety restrictions to access otherwise prohibited capabilities. "through jailbreaking the model or having access to the model weights"
- Lateral movement: The technique of moving through a network post-compromise to access additional systems and privileges. "the step of lateral movement through large codebases represents a key bottleneck"
- Markov Chain Monte Carlo (MCMC): A class of algorithms for sampling from complex probability distributions to approximate Bayesian posteriors. "Markov Chain Monte Carlo (MCMC) sampling is one such Bayesian technique, which we employ to model the relationship."
- MITRE ATT&CK: A comprehensive taxonomy of adversary tactics, techniques, and procedures used in cyber operations. "MITRE ATT{paper_content}CK"
- Model weights: The learned parameters of a machine learning model that determine its behavior and outputs. "through jailbreaking the model or having access to the model weights"
- Network Detection and Response (NDR): Security systems for detecting and responding to threats by analyzing network traffic. "But it would not help overcome other hurdles, like evasion from EDR/NDR."
- Quantitative AI risk assessment: The process of numerically estimating AI-related risks using data, models, and expert inputs. "while noting improvements that can be made to further strengthen its application in quantitative AI risk assessment."
- Remote Code Execution (RCE): The ability for an attacker to execute arbitrary code on a remote target system. "Involves RCE, Overflow, and ROP concepts."
- Return-Oriented Programming (ROP): An exploitation technique chaining existing code fragments (gadgets) to execute arbitrary behavior without injecting code. "Involves RCE, Overflow, and ROP concepts."
- Risk modeling: Building structured representations of pathways to harm with measurable components to estimate overall risk. "Risk modeling could help address this gap by decomposing complex risk pathways into discrete, measurable steps"
- Risk scorecard: A structured summary of risk indicators and categories used to communicate model risks. "the risk scorecard in OpenAIâs o1 system card shows that the model poses greater risks than its predecessor GPT4o"
- Safety case: A structured, evidence-based argument demonstrating that a system is acceptably safe for a given context. "In the context of safety cases for AI, \citet{goemans2024} discuss expert input and benchmarks as sources of quantitative evidence in safety case nodes"
- Scaffolding scheme: A method that orchestrates tools, prompts, and processes to enhance an LLM’s performance on complex tasks. "they compare the performance of five models ... using a custom scaffolding scheme."
- Spear phishing: Targeted phishing attacks that use personalized information to deceive specific individuals. "A cybercrime group launches highly targeted spear phishing attacks"
- System card: A document detailing a model’s capabilities, limitations, and risk profile to inform stakeholders. "the risk scorecard in OpenAIâs o1 system card"
- Tool scaffolding: Integrating external tools and structured workflows around an LLM to improve task completion. "the actor can use the model in any fashion (e.g., chatbot, tool scaffolding, etc.)"
- Uplift: The increase in success probability attributable to assistance from an AI model compared to a baseline. "a delta often referred to as the uplift provided by an LLM"
- Web Application Firewall (WAF): A security system that filters and monitors HTTP traffic to protect web applications from attacks. "Bypassing a restrictive Web Application Firewall (WAF) to achieve remote code execution."
- Zero-day vulnerabilities: Security flaws unknown to the vendor and defenders, lacking patches and thus exploitable by attackers. "benchmarks evaluating the ability of LLMs to discover zero-day vulnerabilities could directly measure how the models would perform against real-world zero-day vulnerabilities."
Collections
Sign up for free to add this paper to one or more collections.