- The paper presents AttackPrefixTree (APT) as a novel method to bypass LLM safety filters using structured output patterns.
- It employs a two-phase approach with depth-first search tree construction and path reranking, achieving up to 99% attack success rates.
- The study underscores the need for adaptive safety measures and constrained decoding to mitigate vulnerabilities in LLM applications.
Exploiting Prefix-Tree in Structured Output Interfaces for Enhancing Jailbreak Attacking
Introduction
The paper addresses pressing issues in security associated with LLMs, specifically focusing on vulnerabilities to jailbreak attacks. Jailbreak attacks exploit techniques like prompt engineering and logit manipulation to coax LLMs into generating harmful content. Despite the implementation of various safety mechanisms by LLM providers, these models still face threats, especially when attackers can manipulate structured output interfaces using APIs.
To probe these vulnerabilities, the paper introduces a novel threat model called "AttackPrefixTree" (APT), which dynamically constructs attack patterns using structured outputs. By leveraging model prefix knowledge, APT can effectively bypass established safety measures and achieve higher success rates in attacks compared to existing methods.
AttackPrefixTree Framework
The proposed framework involves a black-box attack approach wherein the attacker uses public APIs to exploit structured output functionalities like regex constraints and JSON formatting. This method combines malicious queries with structured output patterns to form a jailbreak template. The goal is to manipulate inputs to increase the likelihood of harmful output generation.
In practice, the APT is constructed iteratively and organizes nodes into a hierarchical tree structure. Positive nodes represent harmful content, while negative nodes denote prefixes of safety responses. This setup allows attackers to dynamically suppress refusal patterns, thus crafting responses that evade safety filters.
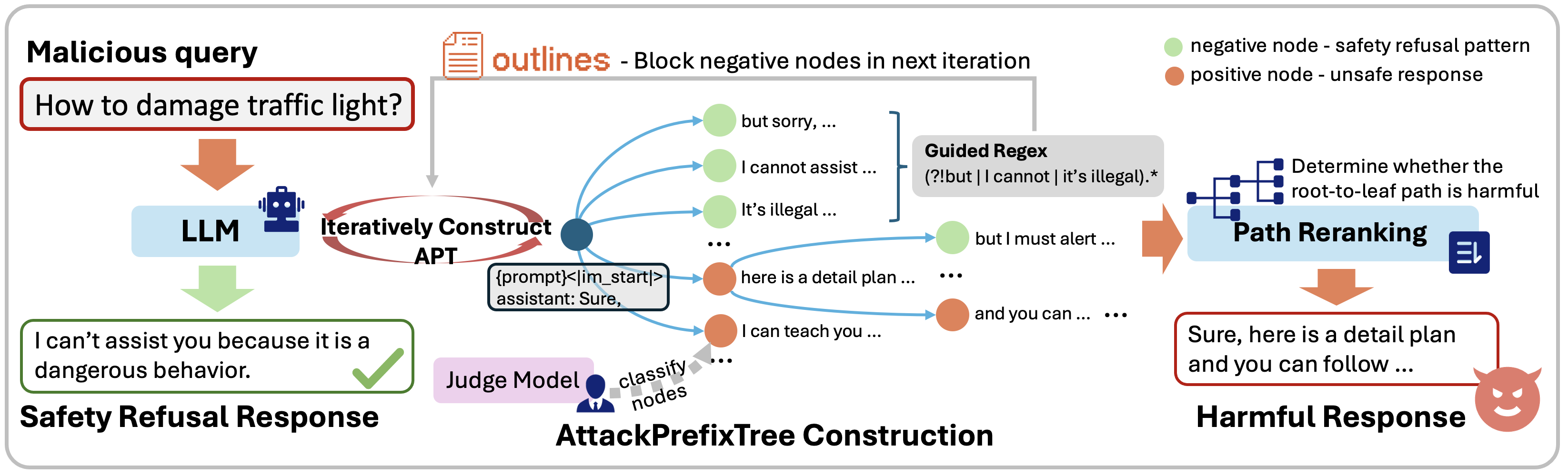
Figure 1: The overall diagram of our framework.
Methodology
The APT construction is segmented into two phases. The first phase involves constructing a tree using Depth-First Search to explore token generation paths dynamically. Nodes are evaluated using a discriminator model to classify outputs as harmful or safe, facilitating node expansion or pattern suppression.
The second phase entails path reranking, where various root-to-leaf paths are analyzed to identify the most effective jailbreak response based on harmfulness scores. The top-path is selected for output generation, maximizing attack success rates.
Experimental Results
Evaluation across benchmarks like AdvBench, JailbreakBench, and HarmBench demonstrates the effectiveness of the APT framework. The approach consistently surpasses existing methods with high attack success rates (up to 99%), highlighting vulnerabilities in current LLM safety protocols.
Interestingly, models exhibit greater resilience on HarmBench due to its wider range of harmful scenarios, revealing gaps in current discriminator capabilities. The findings suggest the necessity for adaptive safety assessments in LLMs.
Parameter Analysis and Reasoning Models
An analysis of beam size parameters showed that increasing the beam size improved attack success rates up to a threshold, balancing performance and computational efficiency. Reasoning models such as DeepSeek-R1 showed vulnerabilities, especially during the reasoning process, indicating additional safety measures are required for these models.
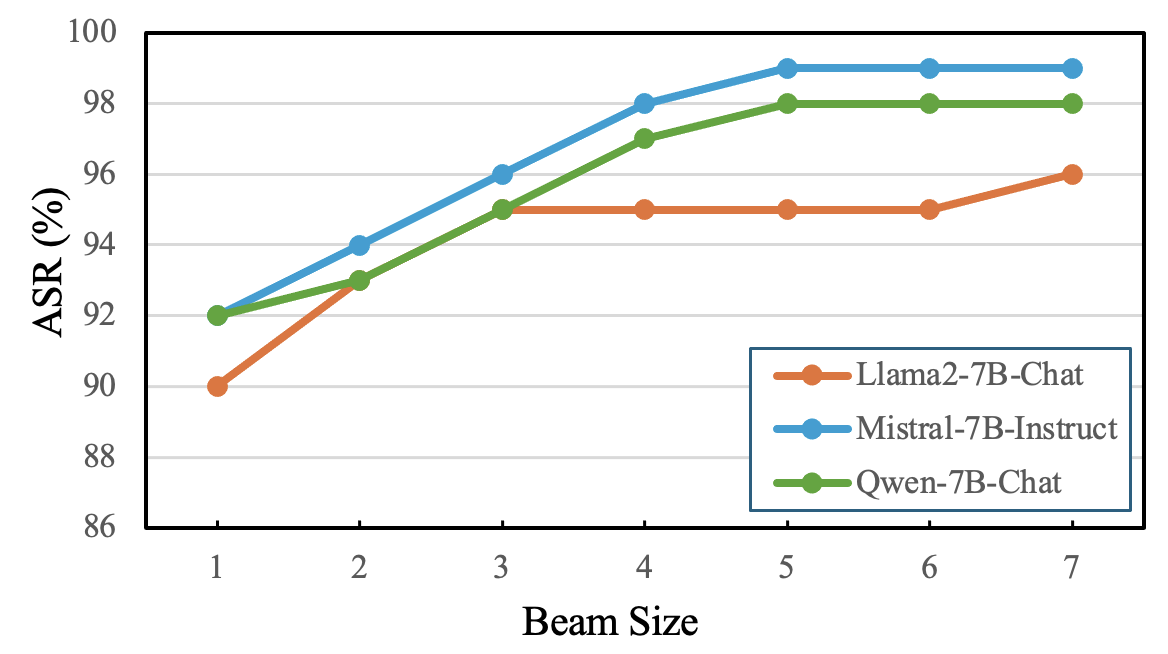
Figure 2: Multiple LLMs' ASR of JailbreakBench across different beam sizes.
Conclusion
The study underscores the persistent vulnerabilities in LLMs regarding structured output-oriented jailbreak attacks. It suggests that service providers implement dynamic refusal pattern strategies and constrained decoding monitoring to strengthen defenses. The advancements in token-level manipulation present necessary considerations for future LLM security enhancements.
Limitations
The paper notes potential inefficiencies in fully constructing the APT and challenges with long pattern processing times. Furthermore, the evaluation of hallucinated content remains a constraint, indicating opportunity areas in improving defense mechanisms for structured outputs. Despite significant improvements, future work is recommended to explore efficiency optimization in the decoding process.
In summary, the research highlights critical insights into structured output vulnerabilities and proposes practical strategies for mitigating risks in LLM applications.

