- The paper presents a learning-based, label-free framework that approximates ASR metrics using task-agnostic multimodal representations and proxy-based agreement signals.
- It achieves single-digit mean absolute error in approximating WER and CER, with over 50% reduction in error compared to state-of-the-art baselines.
- The method generalizes across 40+ ASR models and 14 diverse datasets, demonstrating robust performance in IID, out-of-distribution, and cross-model evaluations.
Robust Approximation of ASR Metrics Without Ground Truth
Motivation and Problem Scope
Quantitative evaluation of ASR systems is typically conducted using ground truth-dependent metrics such as WER or CER. However, in realistic or low-resource deployment environments, access to exhaustively labeled data is limited or impossible. Furthermore, as model diversity and coverage increase—potentially leading to deployment across new domains and device classes—the true generalization capabilities of ASR systems become opaque due to evaluation bottlenecks created by label scarcity. Traditional reference-free methods either rely on confidence/posterior features or produce only relative quality signals, making them inadequate for action-driven tasks such as model selection, domain registration, or knowledge distillation where numerical error metrics are required.
Methodology
The paper "On the Robust Approximation of ASR Metrics" (2502.12408) tackles this central challenge by proposing a learning-based framework to approximate ASR error metrics label-free using task-agnostic multimodal representations and proxy-based agreement signals.
The method leverages multimodal (speech, text) embeddings derived from SONAR, mapping speech inputs and the associated hypothesis transcript into a joint representation space. Cosine similarity in this space serves as an indicator of semantic-alignment quality. Crucially, the pipeline incorporates agreement metrics with a high-quality proxy ASR system: pWER and pCER, computed between the target system’s hypothesis and the reference generated by the proxy. These features—multimodal similarity, pWER, and pCER—are then passed to an ensemble regression model (comprising Random Forest, Gradient Boosting, Histogram-based methods, and Ridge regression) trained to predict the actual error metrics.
The entire approach is agnostic to training/test domain and model; proxy models are dynamically selected based on average performance ranking, ensuring an appropriate reference even when the target and the proxy system architectures are unrelated.
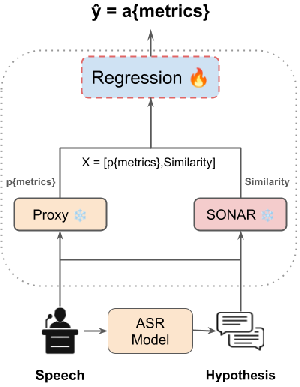
Figure 1: High-level overview of the proposed framework for label-free ASR metric approximation using multimodal embeddings and proxy model agreement.
This pipeline is evaluated in four key evaluation settings: (1) IID data, (2) out-of-distribution domains, and (3) cross-model (evaluating models unseen by the regressor), and (4) the intersection. The training regime employs cross-domain and cross-model splits, with strict separation between train and test domains.
Experimental Results
The experimental protocol is extensive by the standards of ASR metric prediction, covering over 40 ASR models and 14 datasets, encompassing standard benchmarks as well as highly variable "in-the-wild" speech (e.g. Primock57, ATCOsim, noisy LibriSpeech). All models are evaluated using 1,000 randomly sampled utterances per dataset, and cross-domain splits are maintained throughout.
The core claims are substantiated empirically:
- The proposed method achieves single-digit absolute difference (MAE) in approximating WER and CER in all tested configurations, even under significant data/model or domain shift.
- Relative to the strongest prior baseline (eWER3), the approach achieves over 50% reduction in error and frequently attains over 100% improvement margin in mean absolute error across evaluation conditions.
- Human-in-the-loop ablation experiments demonstrate that the error on wild datasets remains nearly invariant (change < 2%) for models with low to moderate error rates, and absolute error rarely exceeds 5% even for poorly performing ASR models on the most difficult datasets.
For example, the whisper-large-v3 model achieves an actual WER/aWER gap of 1.9% on AMI_IHM (out-of-distribution), and the approximation for canary-1b yields a deviation of only 1.1% on the hardest wild domain (VP_Accented). The model faithfully tracks error for noisy and accented test sets, failing only where the error rates are extreme and transcription outputs are semantically incoherent, where the distinction between high and very high error loses operational meaning.
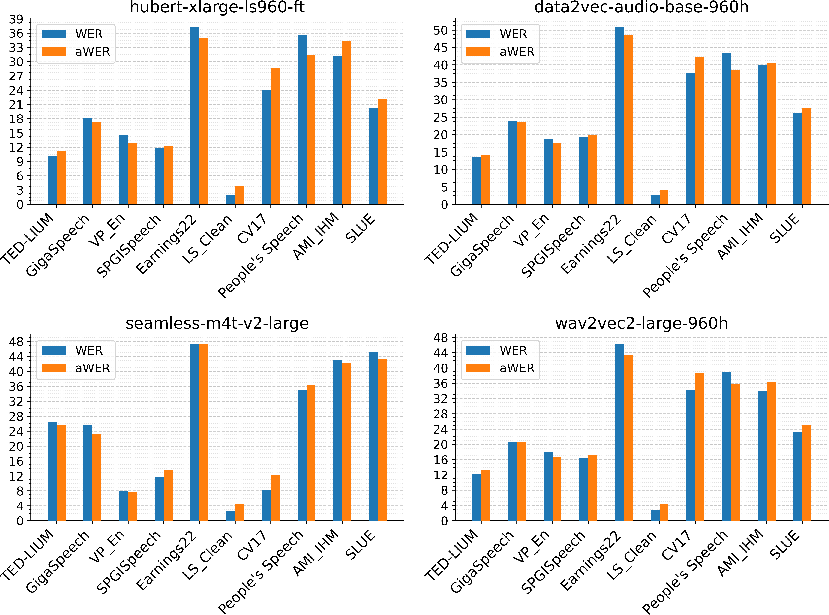
Figure 2: Actual and approximated WER for four representative models across standard benchmarks, showing minimal difference between ground-truth and regression-predicted values.
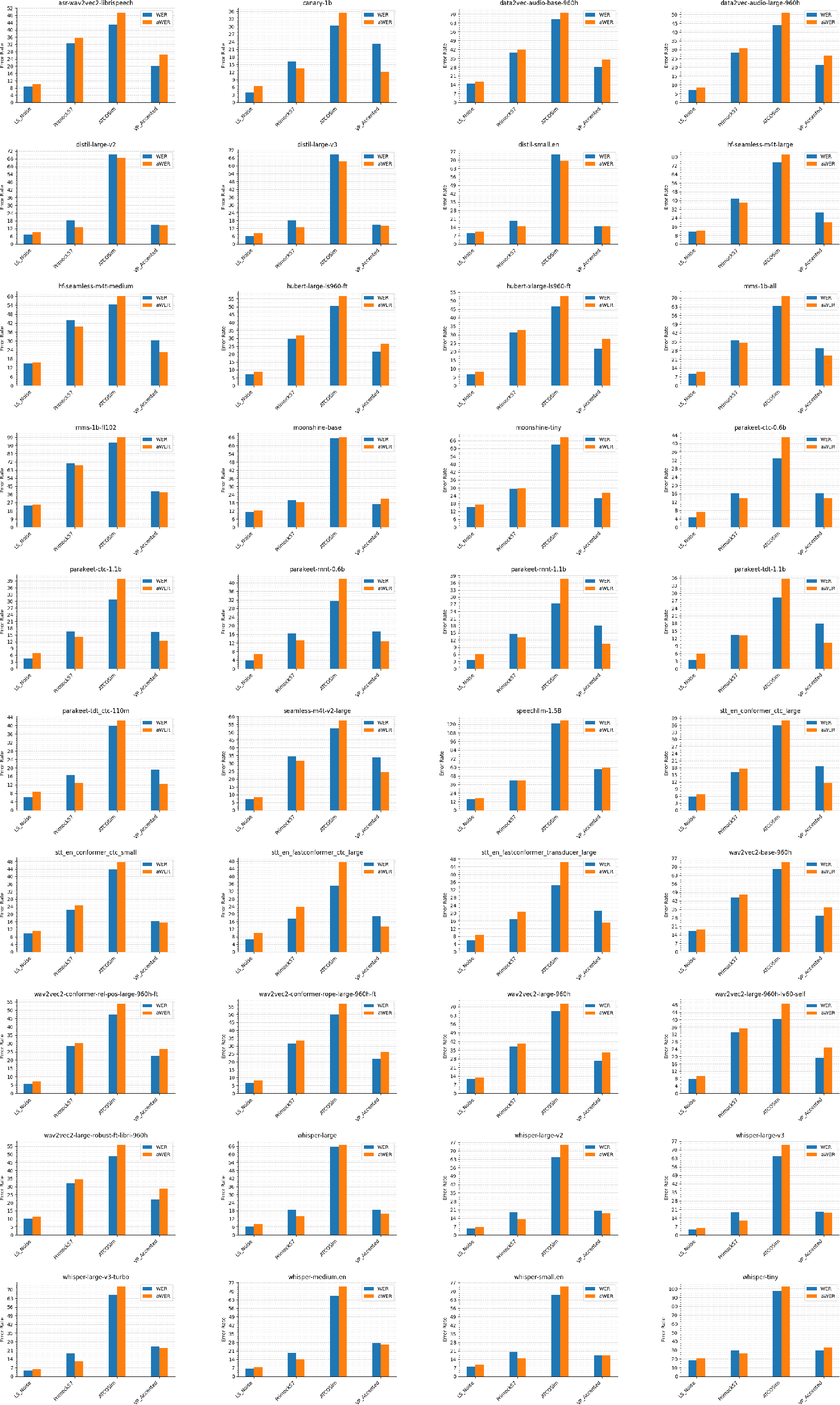
Figure 3: Comparison of Actual vs Approximated WER across all models, attesting to the high fidelity of the regression pipeline.
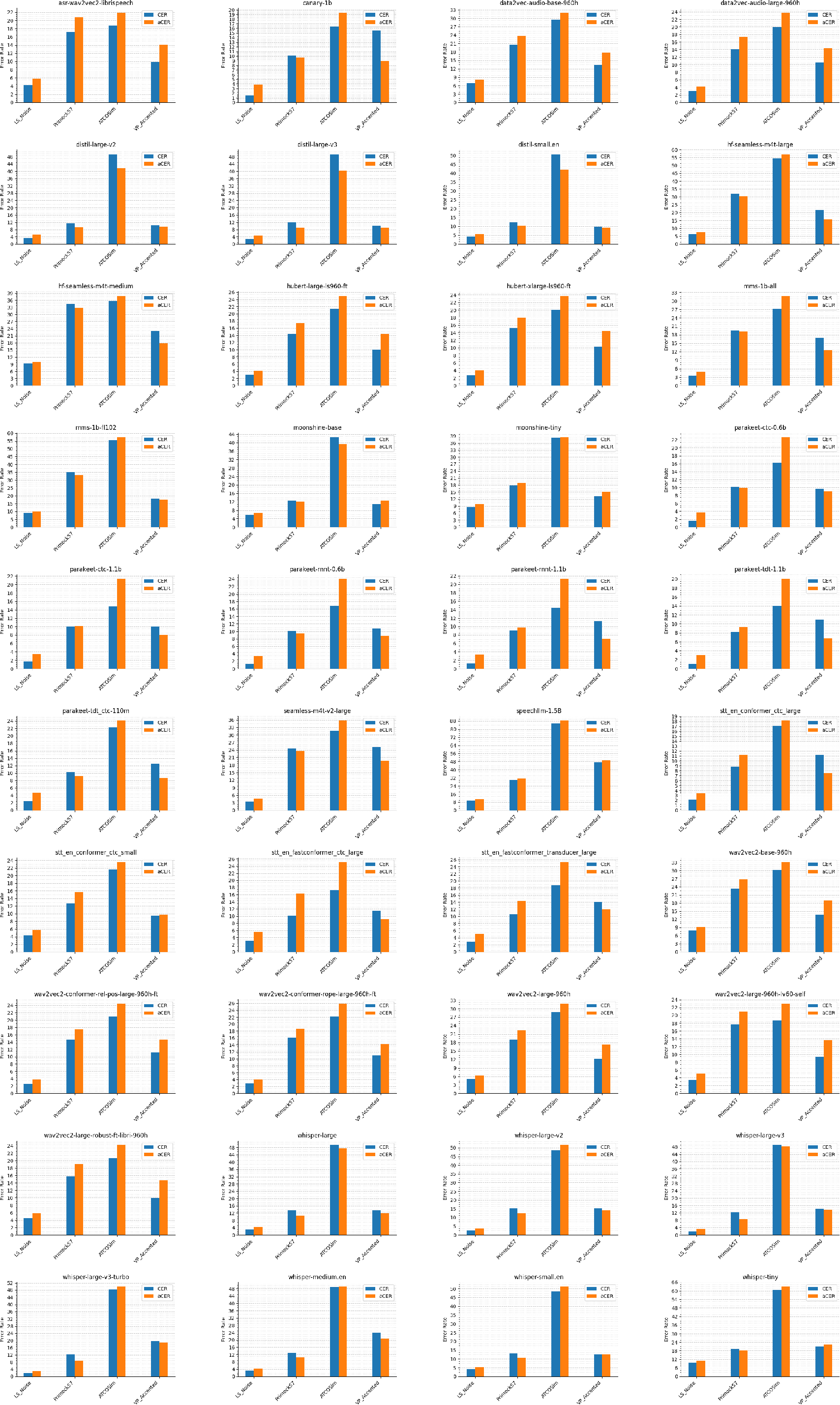
Figure 4: Comparison of Actual vs Approximated CER across all models.
Robustness analyses show that the removal of proxy-based references leads to a tripling of approximation MAE compared to the base pipeline, emphasizing the necessity of high-quality proxy agreement. Introducing multiple proxy references (MPR) further yields a monotonic reduction in MAE, converging to minimal error at as few as 3–5 distinct high-quality proxy systems.
Data scalability is also addressed: increasing training data size for the regression model from 1K to 10K shows negligible benefit, confirming that high performance is attainable with minimal labeled (for regression training) data.
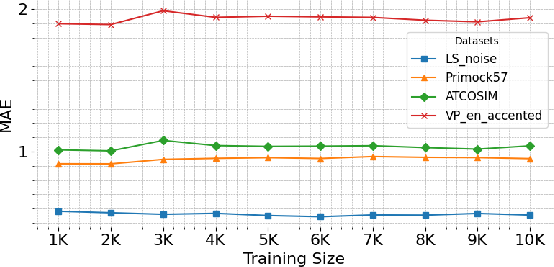
Figure 5: Mean absolute error (↓) between predicted and actual word error counts across varying training data sizes for the regression model, showing effectiveness even at small data regimes.
Model and Dataset Generalization
A pronounced contribution is the demonstration of model- and data-agnostic generalization. The framework is validated not just on frozen architectures (Whisper, NeMo, etc.), but also encoder-only, decoder-only, and hybrid ASR architectures, in both supervised and self-supervised regimes. Ablation across different types and quality levels of proxies demonstrate that regression error tracks the proxy’s actual performance, further underlining that proxy selection is a critical design choice in this paradigm.
The method is deployed on diverse, real-world speech domains and accent groups. Robust error tracking is maintained for difficult domains such as accented and domain-shifted speech, clinical conversation, and air traffic control scenarios. Only in pathological cases—when both the target and proxies are near random-transcription baselines—does approximation degrade.
Implications and Future Directions
This research provides a scalable, actionable solution for label-free, high-fidelity ASR metric approximation, with immediate impact on continuous integration, quality assurance, and rapid model selection workflows where ground-truth annotation is infeasible. The pipeline is suitable for downstream applications including self-training, pseudo-labeling, and domain registration for knowledge distillation, especially in low-resource or non-stationary environments.
Theoretically, the work emphasizes the criticality of both domain-robust multimodal alignment and proxy-based agreement as orthogonal, necessary ingredients to achieve actionable error metric regression.
Practically, two key implications follow:
- With competent proxy selection and modest regression training data, practitioners can deploy reliable ASR metric estimators in new domains with minimal operational overhead.
- The proxy-based ensemble approach enables practitioners to decouple evaluation fidelity from ground truth annotation bottlenecks, allowing for large-scale system benchmarking and active model iteration in unseen or evolving domains.
Going forward, the main research axes include extending this paradigm to truly universal, multilingual or language-agnostic settings, investigating proxy selection under adversarial domain mismatch, and integration with on-device ASR systems where compute and annotation resources are severely constrained.
Conclusion
The framework introduced in "On the Robust Approximation of ASR Metrics" establishes a robust and empirically validated pathway for label-free, model- and data-agnostic ASR metric approximation. Through the integration of cross-modal semantic similarity and proxy reference agreement, it achieves state-of-the-art approximation accuracy for both word-level and character-level error metrics, generalizing across 40+ models and highly diverse datasets. The work directly addresses a critical bottleneck in ASR deployment and evaluation, with broad implications for practical ASR system design and future AI evaluation methodologies.